前言:三大核心硬件
所有软件都是运行硬件之上的,与运行软件相关的三大核心硬件为cpu、内存、硬盘,我们需要明确三点
#1、软件运行前,软件的代码及其相关数据都是存放于硬盘中的
#2、任何软件的启动都是将数据从硬盘中读入内存,然后cpu从内存中取出指令并执行
#3、软件运行过程中产生的数据最先都是存放于内存中的,若想永久保存软件产生的数据,则需要将数据由内存写入硬盘
python解释器执行文件的流程
以python test.py为例,执行流程如下
#阶段1、启动python解释器,此时就相当于启动了一个文本编辑器
#阶段2、python解释器相当于文本编辑器,从硬盘上将test.py的内容读入到内存中
#阶段3、python解释器解释执行刚刚读入的内存的内容,开始识别python语法
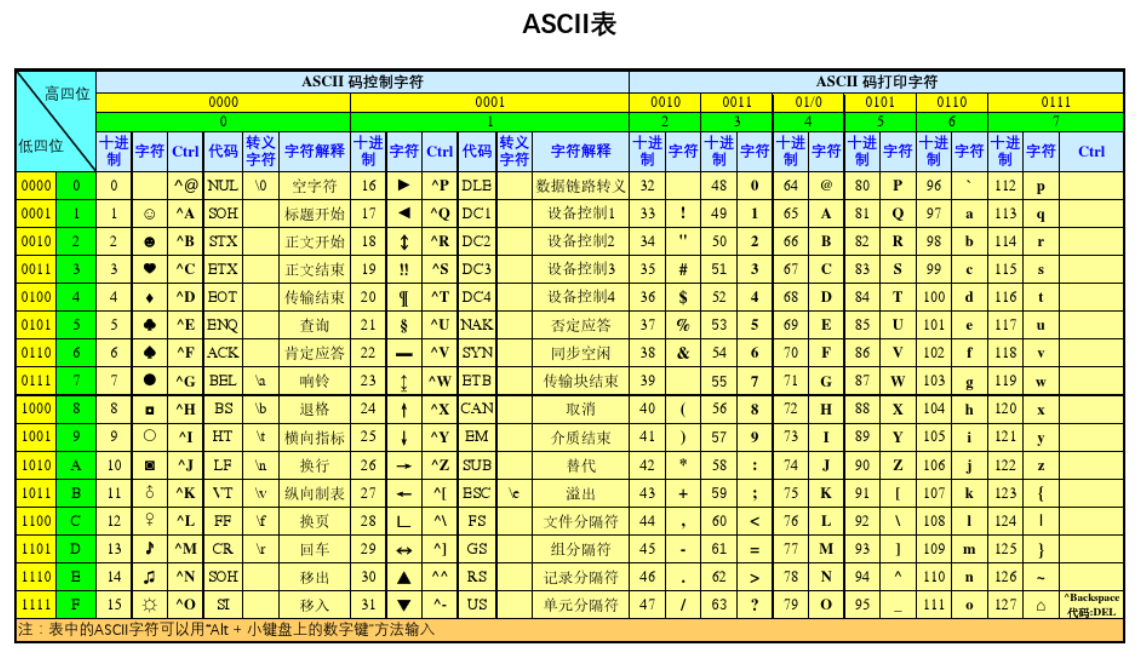
# 什么是字符编码?
计算机是以二进制的形式来存储数据的,即它只认识 0 和 1 两个数字。 20 世纪 60 年代,是计算机发展的早期,这时美国是计算机领域的老大,它制定了一套编码标准,解决了 128 个英文字符与二进制之间的对应关系,被称为 ASCII 字符编码(简称 ASCII 码)。
虽然英语用 128 个字符编码已经够用,但计算机不仅仅用于英语,如果想表示其他语言,128 个符号显然不够用,所以很多其他国家都在 ASCII 的基础上发明了很多别的编码,例如包含了汉语简体中文格式的 GB2312 编码格式(使用 2 个字节表示一个汉字)
GBK(中国)
用2个bytes来代表一个字符,兼容英文字符
0000 0000 0000 0000
1111 1111 1111 1111
最多可以表示65535位
也正是由于出现了很多种编码格式,导致了“文件显示乱码”的情况。
比如说,美国人用的计算机里使用字符编码标准是ASCII、
中国人用的计算机里使用字符编码标准是GBK、
日本人用的计算机里使用字符编码标准是Shift_JIS(
发送邮件时,如果发信人和收信人使用的编码格式不一样,则收信人很可能看到乱码的邮件。)
基于这个原因,Unicode 字符集应运而生。
# bytes类型及用法
新增了 bytes 类型,用于代表字节串。
字符串(str)由多个字符组成,以字符为单位进行操作;
字节串(bytes)由多个字节组成,以字节为单位进行操作。
bytes 和 str 除操作的数据单元不同之外,它们支持的所有方法都基本相同,bytes 也是不可变序列。
bytes 对象只负责以字节(二进制格式)序列来记录数据,至于这些数据到底表示什么内容,完全由程序决定。如果采用合适的字符集,字符串可以转换成字节串;反过来,字节串也可以恢复成对应的字符串。
由于 bytes 保存的就是原始的字节(二进制格式)数据,因此 bytes 对象可用于在网络上传输数据,也可用于存储各种二进制格式的文件,比如图片、音乐等文件。
如果希望将一个字符串转换成 bytes 对象,有如下三种方式:
- 如果字符串内容都是 ASCII字符,则可以通过直接在字符串之前添加 b 来构建字节串值。
- 调用 bytes() 函数(其实是 bytes 的构造方法)将字符串按指定字符集转换成字节串,如果不指定字符集,默认使用 UTF-8 字符集。
- 调用字符串本身的 encode() 方法将字符串按指定字符集转换成字节串,如果不指定字符集,默认使用 UTF-8 字符集。
例如,如下程序示范了如何创建字节串:
# 创建一个空的bytes
b1 = bytes()
# 创建一个空的bytes值
b2 = b''
# 通过b前缀指定hello是bytes类型的值
b3 = b'hello'
print(b3)
print(b3[0])
print(b3[2:4])
# 调用bytes方法将字符串转成bytes对象
b4 = bytes('我爱Python编程',encoding='utf-8')
print(b4)
# 利用字符串的encode()方法编码成bytes,默认使用utf-8字符集
b5 = "学习Python很有趣".encode('utf-8')
print(b5)
b'hello'
104
b'll'
b'\xe6\x88\x91\xe7\x88\xb1Python\xe7\xbc\x96\xe7\xa8\x8b'
b'\xe5\xad\xa6\xe4\xb9\xa0Python\xe5\xbe\x88\xe6\x9c\x89\xe8\xb6\xa3'
从上面的输出结果可以看出,字节串和字符串非常相似,只是字节串里的每个数据单元都是 1 字节。
计算机底层有两个基本概念:位(bit)和字节(Byte),其中 bit 代表 1 位,要么是 0,要么是 1,就像一盏灯,要么打开,要么熄灭;Byte 代表 1 字节,1 字节包含 8 位。
在字节串中每个数据单元都是字节,也就是 8 位,其中每 4 位(相当于 4 位二进制数,最小值为 0 ,最大值为 15)可以用一个十六进制数来表示,因此每字节需要两个十六进制数表示,所以可以看到上面的输出是 b'\xe6\x88\x91\xe7\x88\xb1Python\xe7\xbc\x96\xe7\xa8\x8b',比如 \xe6 就表示 1 字节,其中 \x 表示十六进制,e6 就是两位的十六进制数
理解字符编码前,我们有必要把一些基础概念弄清楚,虽然有些概念我们每天都在接触甚至在使用它,但并不一定真正理解它。比如:字节、字符、字符集、字符编码。
字节
字节(Bytes)是计算机中数据存储的基本单元,一字节等于一个8位的比特(8bit);
bytes: 二进制,互联网上(电脑磁盘)的数据都是以二进制的方式进行传输
字符
你正在阅读的这篇文章就是由很多个字符(Character)构成的,字符一个信息单位,它是各种文字和符号的统称,比如一个英文字母是一个字符,一个汉字是一个字符,一个标点符号也是一个字符。
字符集
字符集是计算机中多个字符的集合,字符在计算机中是各种文字和符号的统称。
字符编码 一套法则, 能够将0/1和人类的语言之间进行转换的法则
字符编码(Character Encoding)是将字符集中的字符码映射为字节流的一种具体实现方案,常见的字符编码有 ASCII 编码、UTF-8 编码、GBK 编码等。某种意义上来说,字符集与字符编码有种对应关系,例如 ASCII 字符集对应 有 ASCII 编码。
Python 3.x 中,字符串采用的是 Unicode 字符集,可以用如下代码来查看当前环境的编码格式:
>>> import sys
>>> sys.getdefaultencoding()
'utf-8'
同时,在 Python 3.x 中也可以用 ord() 和 chr() 函数实现字符和编码数字之间的转换,例如:
>>> ord('Q')
81
>>> chr(81)
'Q'
>>> ord("网")
32593
>>> chr(32593)
'网'
八位二进制 = 8bit
8bit = 1bytes
1024bytes = 1KB
1024KB = 1MB
1024MB = 1GB
1024GB = 1TB
1024TB = 1PB
# 万国码
unicode于1990年开始研发,1994年正式公布,具备两大特点
#1. 存在所有语言中的所有字符与数字的一一对应关系,即兼容万国字符
#2. 与传统的字符编码的二进制数都有对应关系
此处需要强调:软件是存放于硬盘的,而运行软件是要将软件加载到内存的
面对硬盘中存放的各种传统编码的软件,想让我们的计算机能够将它们全都正常运行而不出现乱码,
内存中必须有一种兼容万国的编码,
并且该编码需要与其他编码有相对应的映射/转换关系,这就是unicode的第二大特点产生的缘由
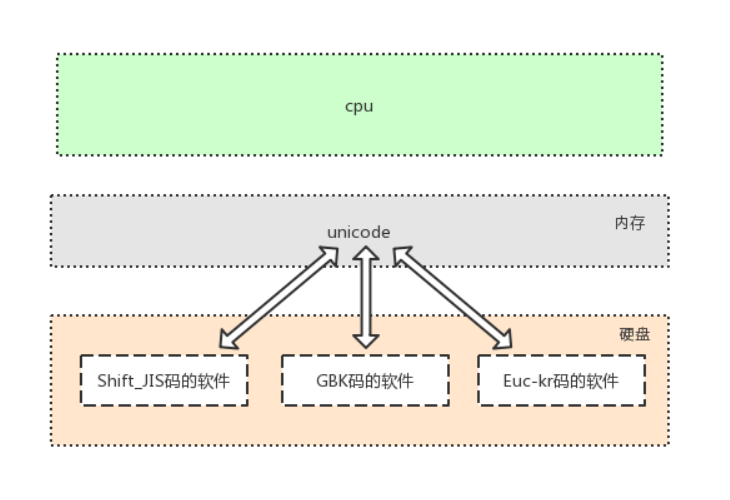
文本编辑器输入任何字符都是最新存在于内存中,是unicode编码的,存放于硬盘中,则可以转换成任意其他编码,只要该编码可以支持相应的字符
# 英文字符可以被ASCII识别
英文字符--->unciode格式的数字--->ASCII格式的数字
# 中文字符、英文字符可以被GBK识别
中文字符、英文字符--->unicode格式的数字--->gbk格式的数字
# 日文字符、英文字符可以被shift-JIS识别
日文字符、英文字符--->unicode格式的数字--->shift-JIS格式的数
Unicode就是为了统一各国各地区的编码规则, 重新搞了一套包罗地球上所有文化, 符号的字符集! Unicode没有编码规则, 只是一套包含全世界符号的字符集. Unicode也不完美, 于是后续有了众多UTF编码(UTF-8, UTF-16)
Unicode为何不完美:
汉字的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),
也就是说,这个符号的表示至少需要2个字节(生成`unicode`**所有的字符都用`2bytes`)
表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
而英文字母只用一个字节表示就够了
这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
最致命地是:
当我们由内存写入硬盘时会额外耗费一倍的时间,
总结:
1、占用存储空间
2、io次数增加,程序运行速度变慢(最致命)
所以将内存中的unicode二进制写入硬盘或者基于网络传输时
必须将其转换成一种精简的格式,
这种格式即utf-8
# 多国字符—√—》内存(unicode格式的二进制)——√—》硬盘(utf-8格式的二进制)
# utf-8
utf-8 (unicode transformation format)
Unicode 字符集可以使用的编码方案有三种,分别是:
- UTF-8:一种变长的编码方案,使用 1~6 个字节来存储;
- UTF-32:一种固定长度的编码方案,不管字符编号大小,始终使用 4 个字节来存储;
- UTF-16:介于 UTF-8 和 UTF-32 之间,使用 2 个或者 4 个字节来存储,长度既固定又可变。
UTF-8 最大的一个特点,就是它是一种变长的编码方式。一个英文字符占1Bytes,一个中文字符占3Bytes,生僻字用更多的Bytes存储,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
----------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
跟据上表,解读 UTF-8 编码非常简单。
如果一个字节的第一位是0,则这个字节单独就是一个字符;
如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
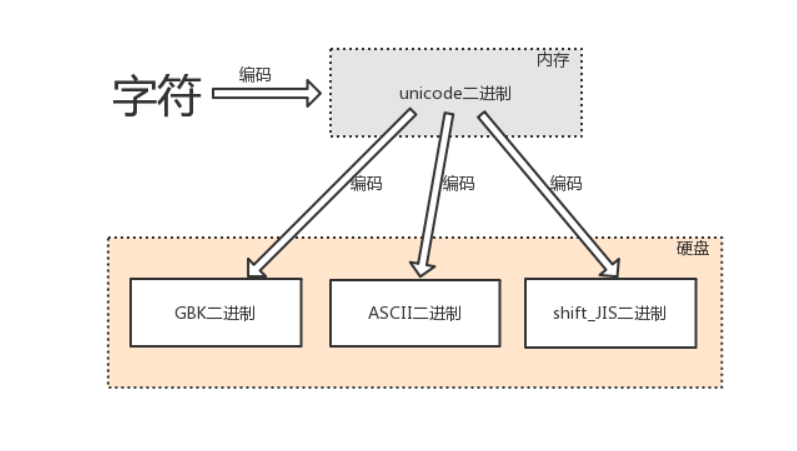
编码与解码
encode
由字符转换成内存中的unicode,以及由unicode转换成其他编码的过程,都称为编码encode
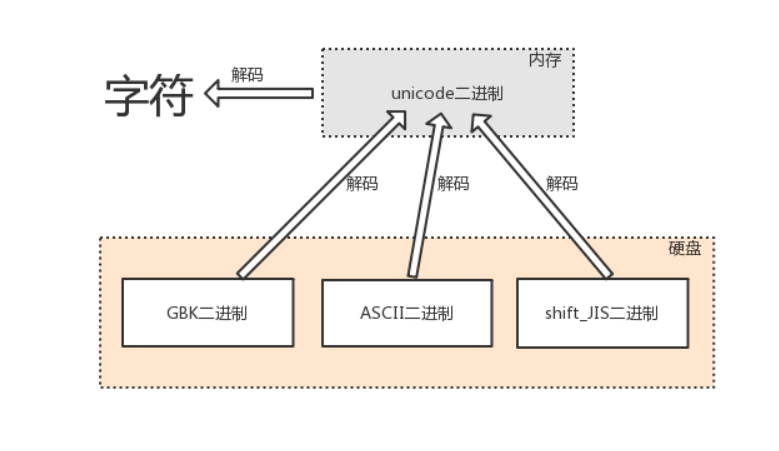
decode
由内存中的unicode转换成字符,以及由其他编码转换成unicode的过程,都称为解码decode
在诸多文件类型中,只有文本文件的内存是由字符组成的,因而文本文件的存取也涉及到字符编码的问题
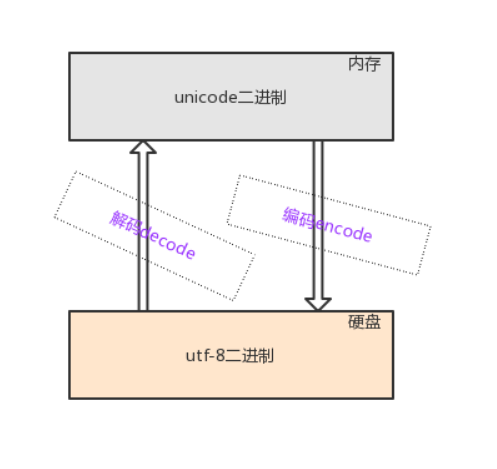
总之搞清楚一件事情, 一个字符用了UTF-8编码的, 就要用UTF-8去解码, 不然就会出现乱码.
需要掌握:
1、用户无论输入什么字符,存入内存,unicode都可以兼容
2、硬盘中无论是什么编码的文件,读到内存,都可以兼容unicode
必须掌握
(内存)unicode二进制字符 >>> 编码(encode) >>> (硬盘)utf-8二进制字符**
(硬盘)utf-8二进制字符 >>> 解码(decode) >>> (内存)unicode二进制字符**
保证不乱码核心:
用什么编码存的数据,就用什么编码取
python2 :
默认的字符编码ascii码(因为当时的unicode还没盛行)
python3:
默认的字符编码utf-8
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号