1、初识爬虫
明晰路径
一般来说,传统的拿数据的做法是:通过浏览器上网,手动下载所需要的数据。其实在这背后,浏览器做了很多我们看不见的工作,而只有了解浏览器的工作原理后,才能真正理解爬虫在帮我们做什么。
浏览器的工作原理

实不相瞒,在这个过程中,浏览器的交流对象不只有你,还有【服务器】。我们可以把服务器理解为一个超级电脑,它可以计算和存储大量数据,并且在互联网中互相传输数据。
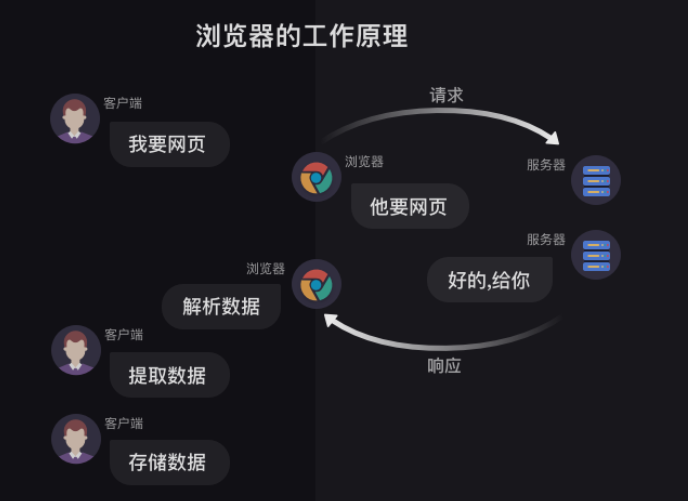
更完整的交流过程是下图这样的:

首先,我们在浏览器输入网址(也可以叫URL)。然后,浏览器向服务器传达了我们想访问某个网页的需求,这个过程就叫做【请求】。
紧接着,服务器把你想要的网站数据发送给浏览器,这个过程叫做【响应】。
- 所以浏览器和服务器之间,先请求,后响应,有这么一层关系。

-
当服务器把数据响应给浏览器之后,浏览器并不会直接把数据丢给你。因为这些数据是用计算机的语言写的,浏览器还要把这些数据翻译成你能看得懂的样子,这是浏览器做的另一项工作【解析数据】
-
紧接着,我们就可以在拿到的数据中,挑选出对我们有用的数据,这是【提取数据】。
-
最后,我们把这些有用的数据保存好,这是【存储数据】。
爬虫做的事

其实,还可以把最开始的【请求——响应】封装为一个步骤——获取数据。由此,我们得出,爬虫的工作分为四步:

第0步:获取数据。爬虫程序会根据我们提供的网址,向服务器发起请求,然后返回数据。
第1步:解析数据。爬虫程序会把服务器返回的数据解析成我们能读懂的格式。
第2步:提取数据。爬虫程序再从中提取出我们需要的数据。
第3步:储存数据。爬虫程序把这些有用的数据保存起来,便于你日后的使用和分析。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号