Network
Network的功能是:记录在当前页面上发生的所有请求。现在看上去好像空空如也的样子,这是因为Network记录的是实时网络请求
Network能够记录浏览器的所有请求。我们最常用的是:ALL(查看全部)/XHR(仅查看XHR)/Doc(Document,第0个请求一般在这里),有时候也会看看:Img(仅查看图片)/Media(仅查看媒体文件)/Other(其他)。最后,JS和CSS,则是前端代码,负责发起请求和页面实现;Font是文字的字体;而理解WS和Manifest,需要网络编程的知识,倘若不是专门做这个,你不需要了解

在Network,有非常重要的一类请求是XHR(或Fetch),因为有它的存在,人们不必刷新/跳转网页,即可加载新的内容。随着技术发展,XHR的应用频率越来越高,我们常常需要在这里找我们想要的数据
XHR的功能是传输数据,其中有非常重要的一种数据是用json格式写成的,和html一样,这种数据能够有组织地存储大量内容。json的数据类型是“文本”,在Python语言当中,我们把它称为字符串。我们能够非常轻易地将json格式的数据转化为列表/字典,也能将列表/字典转为json格式的数据。
如何解析json数据?答案如下:

什么是XHR?
在Network中,有一类非常重要的请求叫做XHR(当你把鼠标在XHR上悬停,你可以看到它的完整表述是XHR and Fetch)
我们平时使用浏览器上网的时候,经常有这样的情况:浏览器上方,它所访问的网址没变,但是网页里却新加了内容。
典型代表:如购物网站,下滑自动加载出更多商品。在线翻译网站,输入中文实时变英文。比如,你正在使用的教学系统,每点击一次Enter就有新的内容弹出。
这个,叫做Ajax技术(技术本身和爬虫关系不大,在此不做展开,你可以通过搜索了解)。应用这种技术,好处是显而易见的——更新网页内容,而不用重新加载整个网页。又省流量又省时间的,何乐而不为。
如今,比较新潮的网站都在使用这种技术来实现数据传输。只剩下一些特别老,或是特别轻量的网站,还在用老办法——加载新的内容,必须要跳转一个新网址。
这种技术在工作的时候,会创建一个XHR(或是Fetch)对象,然后利用XHR对象来实现,服务器和浏览器之间传输数据。在这里,XHR和Fetch并没有本质区别,只是Fetch出现得比XHR更晚一些,所以对一些开发人员来说会更好用,但作用都是一样的。
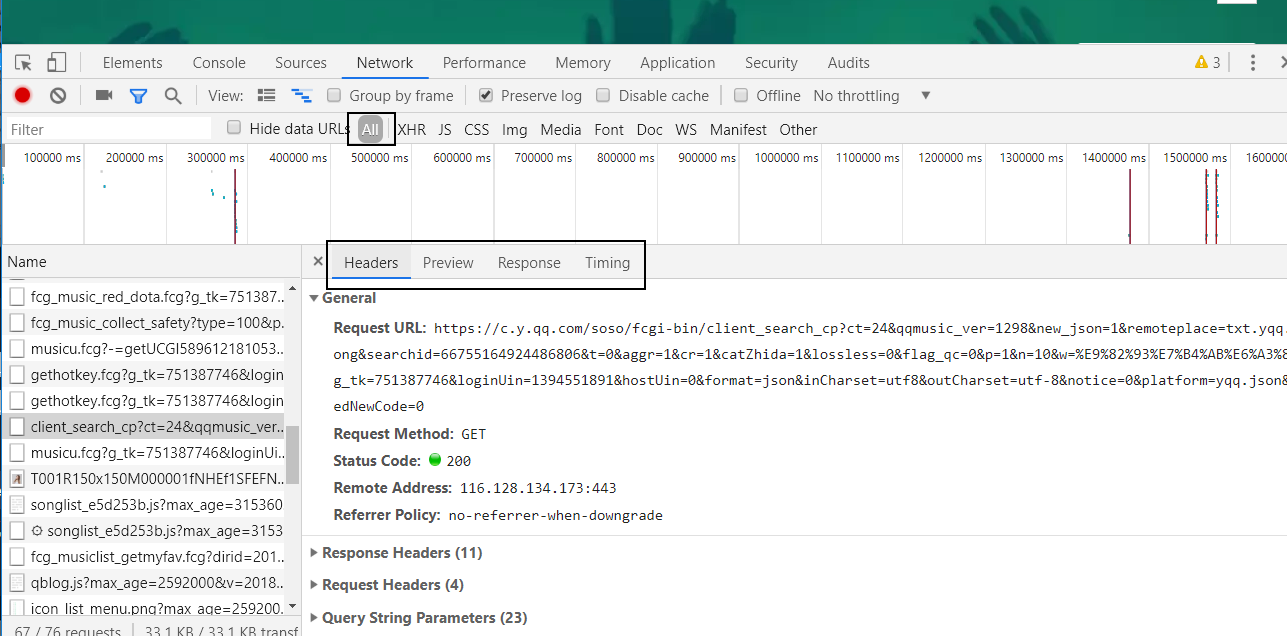
找到一个XHR点击它,出现了如上图这样的一个窗口,我们先来看蓝框里面的内容,从左往右分别是:Headers:标头(请求信息)、Preview:预览、Response:原始信息、Timing:时间
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号