注意力机制 transformer
https://jalammar.github.io/illustrated-transformer/
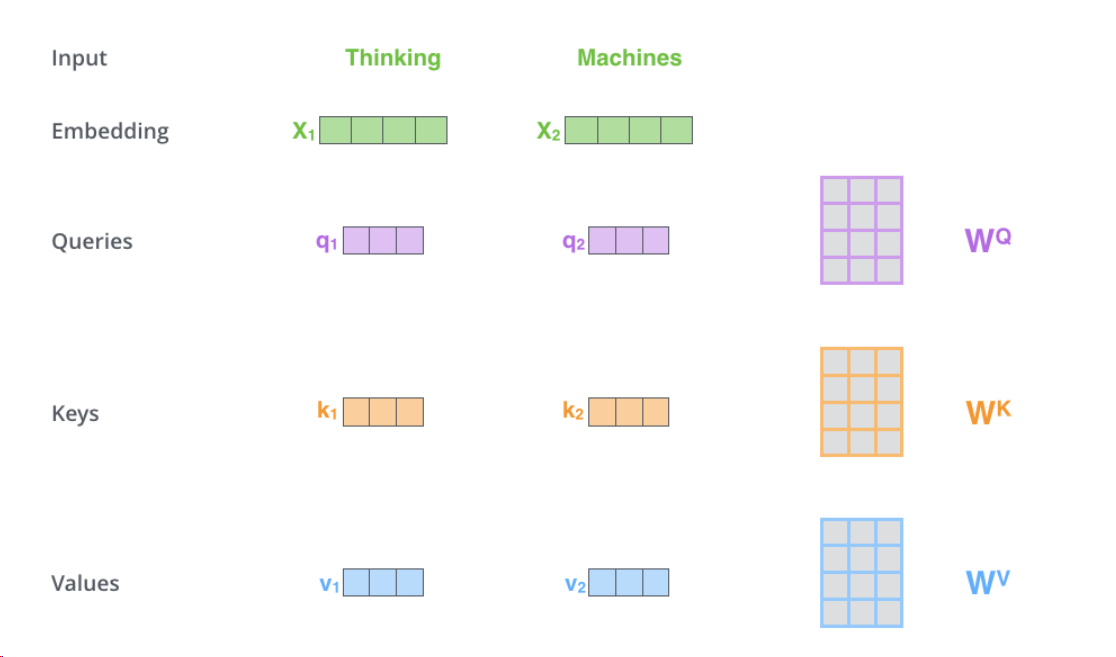
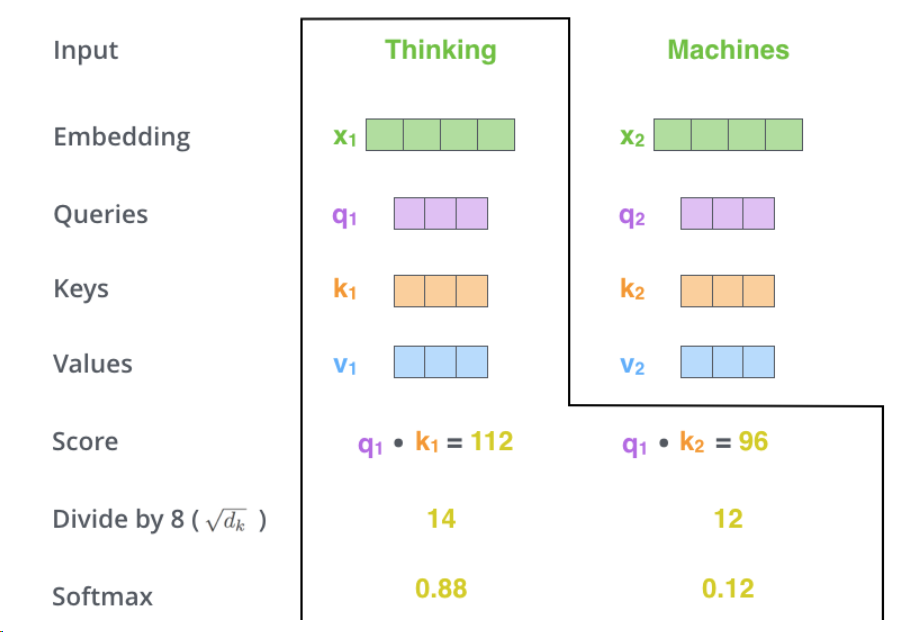
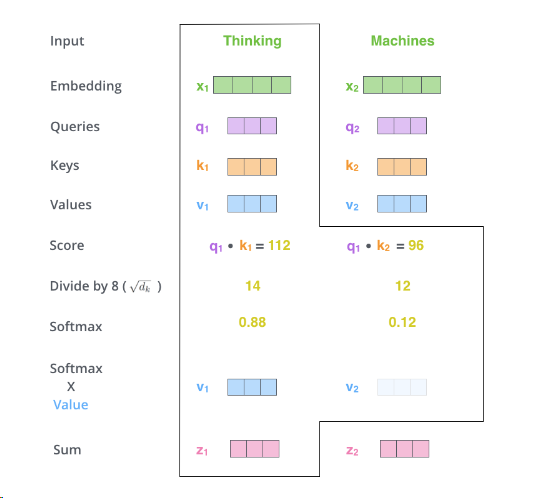
X就是输入的向量 ,第一步就是创建三个输入向量qkv
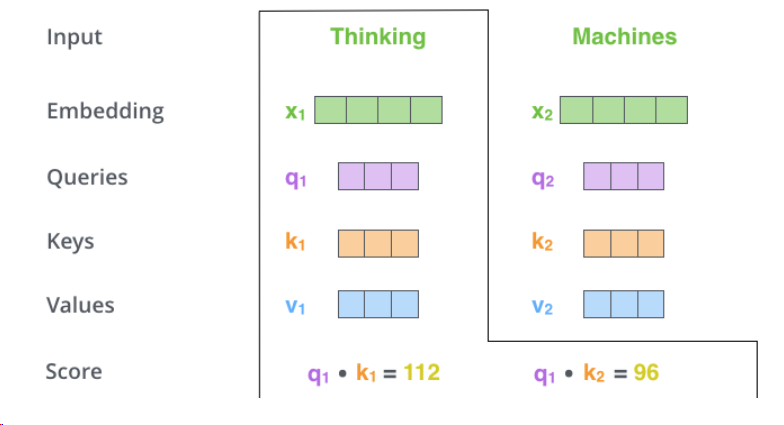
第二步是计算分数:分数决定了对输入句子的其他部分的关注程度。
分数是通过查询向量与我们要评分的各个单词的键向量的点积来计算的。因此,如果我们处理位置#1中单词的自注意力,第一个分数将是q1和k1的点积。第二个分数是q1和k2的点积。
第三步和第四步是将分数除以 8(论文中使用的关键向量维度的平方根 – 64。这会导致梯度更稳定。这里可能还有其他可能的值,但这是默认),然后将结果传递给 softmax 运算。 Softmax 对分数进行归一化,使它们全部为正值并且加起来为 1。

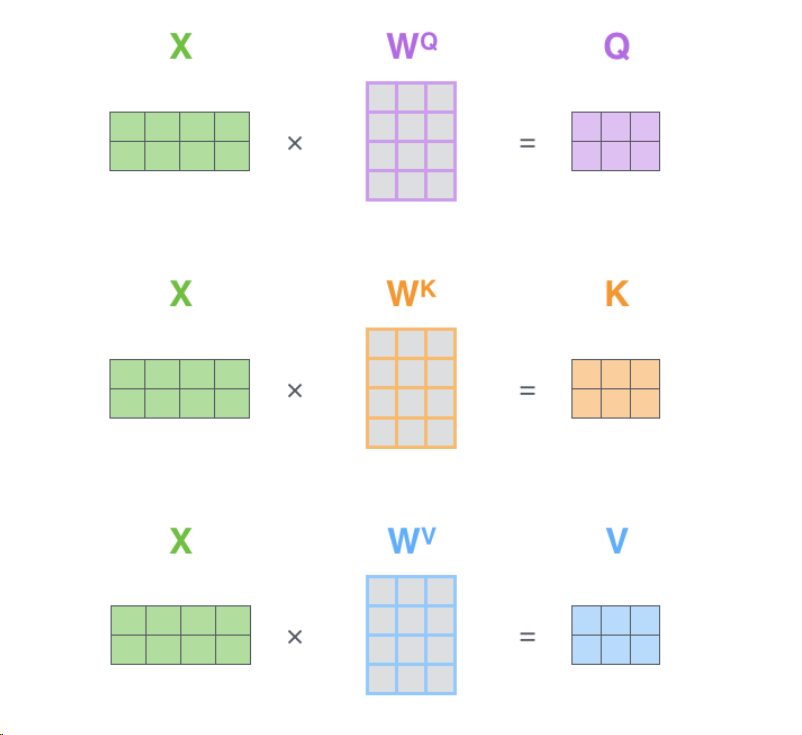
矩阵格式
WQ、WK、WV是由训练得到的
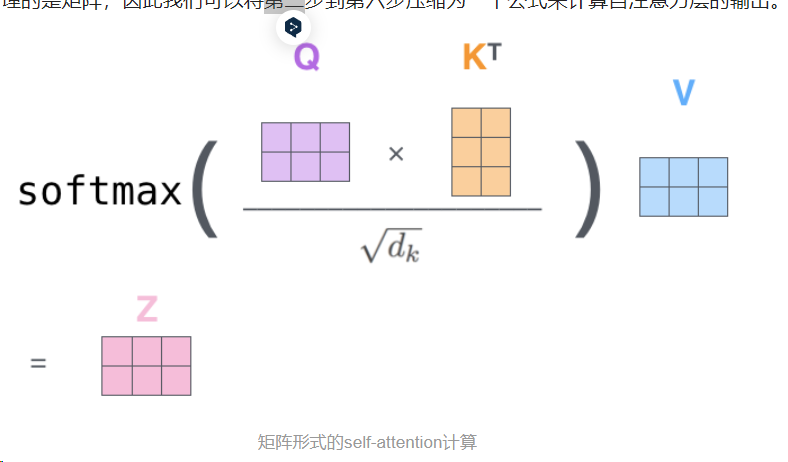
自注意力层的输出是以下形式:(下面这个公式总结了上面的第二步到第六步)
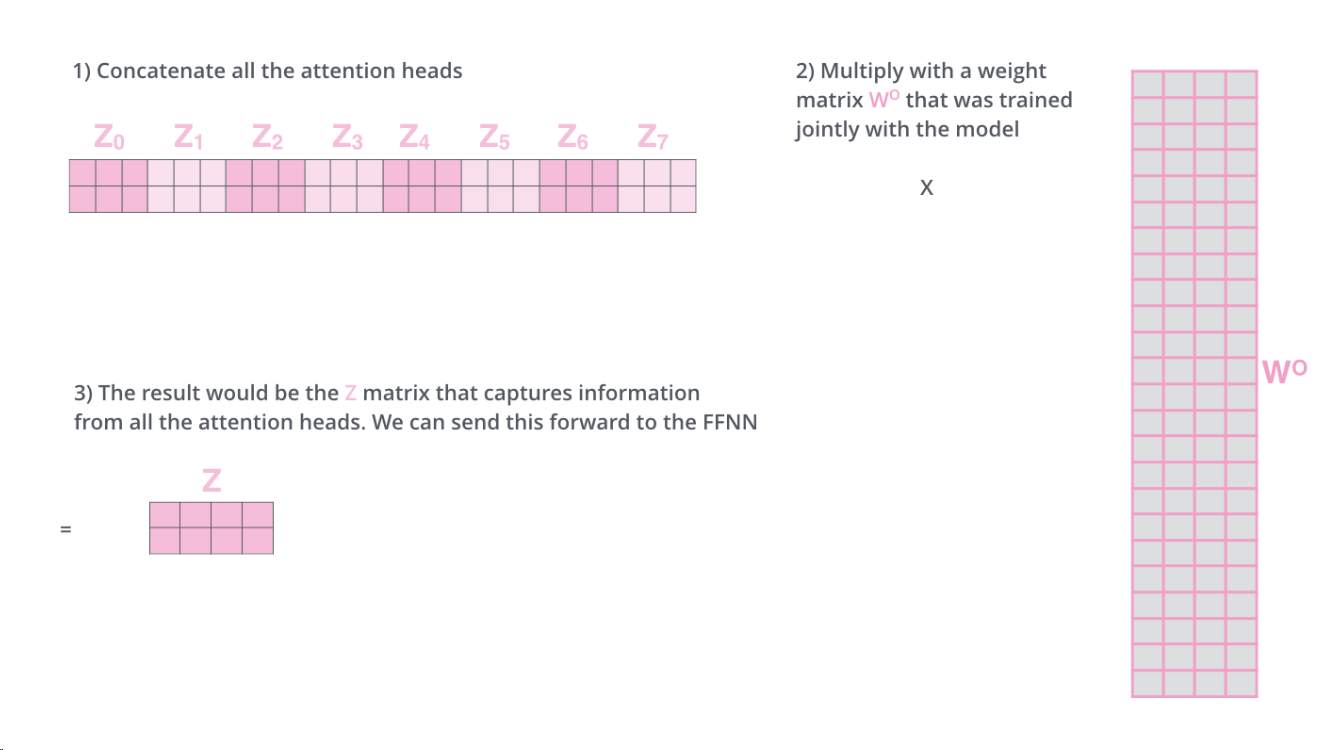
单头注意力 经过注意力层之后会输出一个z,但是多头会输出n个z矩阵
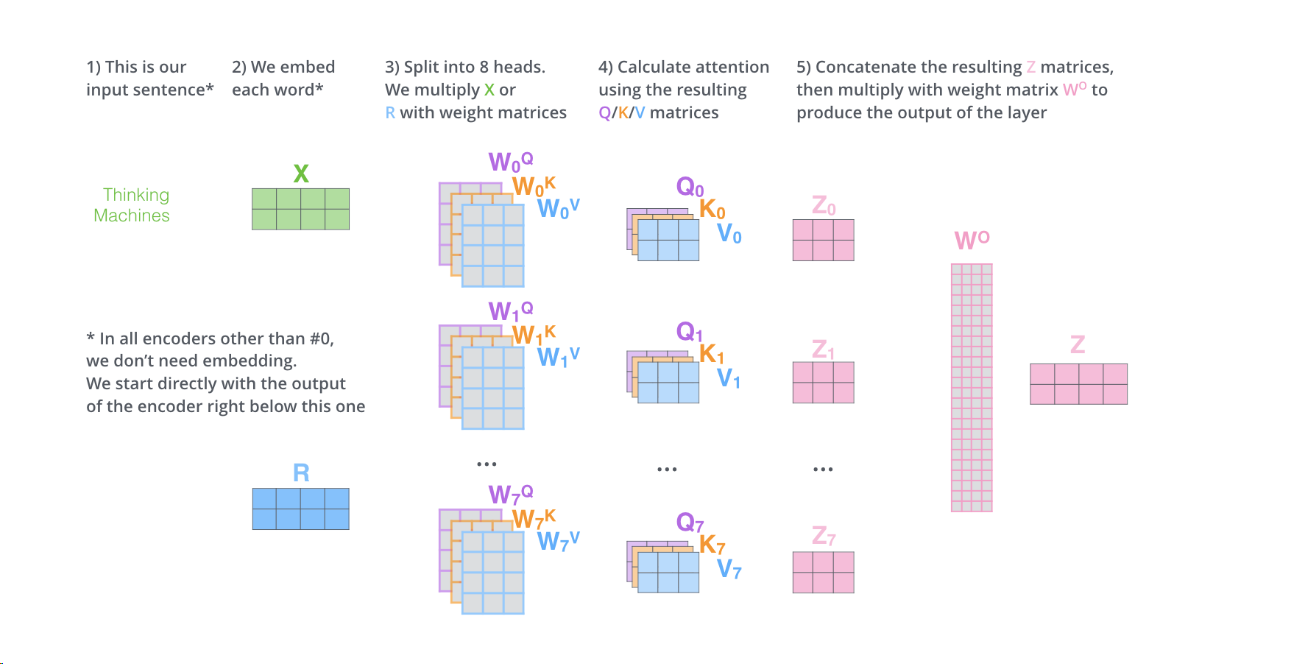
多头注意力机制(它扩展了模型关注不同位置的能力)
注意力机制只是拿出一个qkv 而多头注意力机制是拿出了多组qkv,同时输出也是n个z矩阵。
然后再经过一个训练得到的W矩阵相乘,得到z矩阵