
过拟合问题,L1L2正则化
正则化:凡是可以减少泛化误差而不是减少训练误差的方法都是正则化方法。
在神经网络中参有两类,w叫权重,b叫偏置,w(权重)其实是模型里面未知数的系数,其取值情况决定了模型曲线什么样子,b的取值只会改变模型平移情况,L1L2正则化只针对w进行正则化处理。
L1L2是指L1L2范数,范数理解为把”空间中两点的距离“这个概念进行了扩充。
权重w理解为高维的向量也可以理解为是在高维空间中的一个点,如果这个点到原点的距离如果是欧式距离的话那就是L2范数,如图:
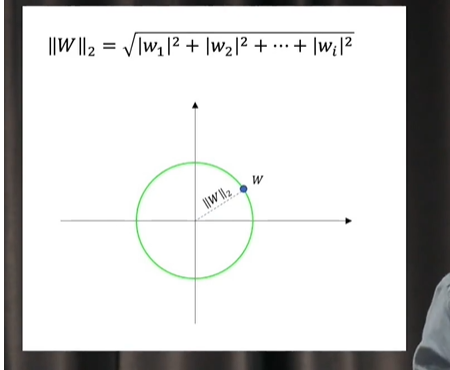
L1范数:
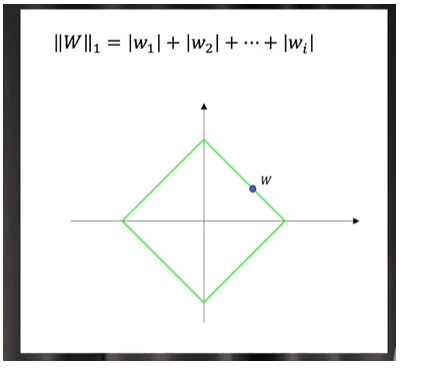
神经网络为什么会出现过拟合:
在训练过程中w和b的取值并不是不变的,最后的结果有大有小,在训练集测试集全集中,w和b的大小并不会改变最后的分类结果,但是在应用场景中的图片并不是来自于训练集图片,过大的w和b,与新的图片数据 相乘以后最后得到的是一个比较大的数值,同时误差与噪声在经过大参数相乘以后也会被放大。
所以我们要控制参数,让参数取值不要那么大:
解决方法:人为设定一个参数的取值范围,并且只设定w的范围,b并不考虑

 浙公网安备 33010602011771号
浙公网安备 33010602011771号