
pytorch 修改预训练模型网络层 (VGG /transformer)
VGG:
这个是VGG的网络模型架构:
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
(fc): Linear(in_features=2048, out_features=2, bias=True)
)
现在想要删除features里面某一层:
from collections import OrderedDict
model_new = OrderedDict(model.features.named_children()) # 定位到features层
model_new.pop("1") # 删除行标为1的那一层
修改后的网络架构:
OrderedDict([('0', Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))), ('2', Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))), ('3', ReLU(inplace=True)), ('4', MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)), ('5', Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))), ('6', ReLU(inplace=True)), ('7', Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))), ('8', ReLU(inplace=True)), ('9', MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)), ('10', Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))), ('11', ReLU(inplace=True)), ('12', Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))), ('13', ReLU(inplace=True)), ('14', Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))), ('15', ReLU(inplace=True)), ('16', MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)), ('17', Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))), ('18', ReLU(inplace=True)), ('19', Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))), ('20', ReLU(inplace=True)), ('21', Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))), ('22', ReLU(inplace=True)), ('23', MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)), ('24', Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))), ('25', ReLU(inplace=True)), ('26', Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))), ('27', ReLU(inplace=True)), ('28', Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))), ('29', ReLU(inplace=True)), ('30', MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))])
方法2:
# model_new = torch.nn.Sequential(*list(model.children())[:-2]) # 这种方法直接修改的是Sequential。该方法直接删除了fc和classifier层。
VGG网络层
这样,直接定位到classifier那一层的网络,将classifier的网络结构换成下面的网络架构。
model_new.classifier= torch.nn.Sequential(torch.nn.Linear(25088, 4096),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(4096, 4096),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(4096,2048 ))
Transformer
我用的是vision transformer,用来做图像分类的。
transformer的网络架构太大,截取一部分来看:
截取了前面两个Block,一共是有11个block的模块
ViT(
(patch_embedding): Conv2d(3, 768, kernel_size=(16, 16), stride=(16, 16))
(positional_embedding): PositionalEmbedding1D()
(transformer): Transformer(
(blocks): ModuleList(
(0): Block(
(attn): MultiHeadedSelfAttention(
(proj_q): Linear(in_features=768, out_features=768, bias=True)
(proj_k): Linear(in_features=768, out_features=768, bias=True)
(proj_v): Linear(in_features=768, out_features=768, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
(proj): Linear(in_features=768, out_features=768, bias=True)
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(pwff): PositionWiseFeedForward(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(drop): Dropout(p=0.1, inplace=False)
)
(1): Block(
(attn): MultiHeadedSelfAttention(
(proj_q): Linear(in_features=768, out_features=768, bias=True)
(proj_k): Linear(in_features=768, out_features=768, bias=True)
(proj_v): Linear(in_features=768, out_features=768, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
(proj): Linear(in_features=768, out_features=768, bias=True)
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(pwff): PositionWiseFeedForward(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(drop): Dropout(p=0.1, inplace=False)
)
(2): Block(
(attn): MultiHeadedSelfAttention(
(proj_q): Linear(in_features=768, out_features=768, bias=True)
(proj_k): Linear(in_features=768, out_features=768, bias=True)
(proj_v): Linear(in_features=768, out_features=768, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
(proj): Linear(in_features=768, out_features=768, bias=True)
(norm1): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(pwff): PositionWiseFeedForward(
(fc1): Linear(in_features=768, out_features=3072, bias=True)
(fc2): Linear(in_features=3072, out_features=768, bias=True)
)
(norm2): LayerNorm((768,), eps=1e-06, elementwise_affine=True)
(drop): Dropout(p=0.1, inplace=False)
)
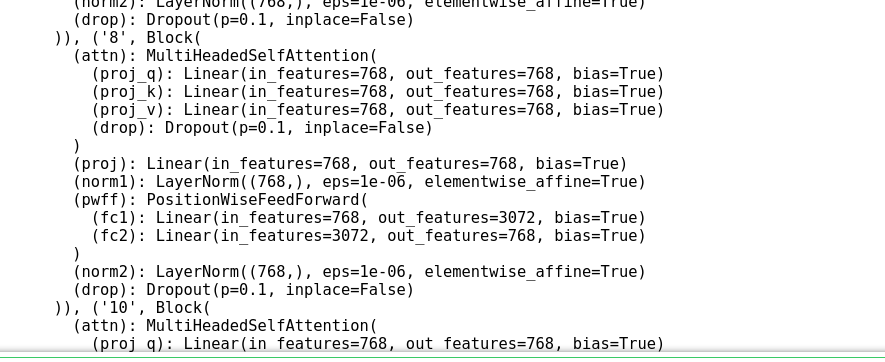
之前由于这整个的模型太大,block的模块过多,参数过多,训练的时候gpu内存会溢出,于是我想删除几个block层。
方法跟VGG的方法差不多:
model_new = OrderedDict(model.transformer.blocks.named_children()) #定位到这一层
model_new.pop("9") #直接删除了第九层的block
print(model_new)
可以看到第八层第十层block,没有显示第九层的block
model_new = OrderedDict(model.amed_children()) #定位到这一层
model_new.pop("transformer“) # 这样写的话,直接删除掉了整个的transformer层
print(model_new)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号