
神经网络结构及模型训练(笔记)
一、神经网络
1、人工神经元
神经网络由很多的节点构成,这些节点又叫做人工神经元(或神经元)
他的结构如图所示:
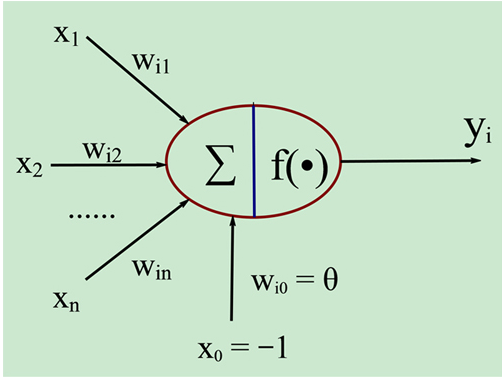
x1~xn是输入信号
wij代表从神经元j到神经元i的连接权值
θ表示一个阈值 ( threshold ),或称为偏置( bias )
神经元i的输出与输入的关系表示为:
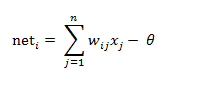
yi=f(neti)
yi表示神经元i的输出,函数f称为激活函数或转移函数,net称为净函数。
若用X代表输入向量,用W代表权重向量,即:
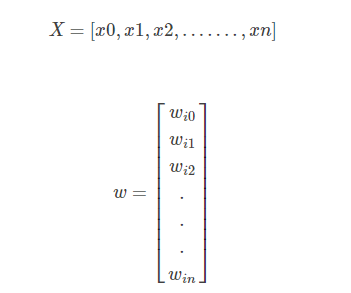
则神经元的输出可以表示为向量相乘的形式:
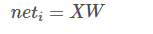
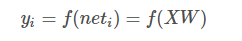
若神经元的净激活net为正,称该神经元处于激活状态或兴奋状态,若净激活为负则称神经元处于抑制状态。
这种“阈值加权和”的神经元模型称为M-P模型(McCulloch-Pitts Model),也称为神经网络的一个处理单元
2、常用的几种激活函数
1、S函数(Sigmoid函数)
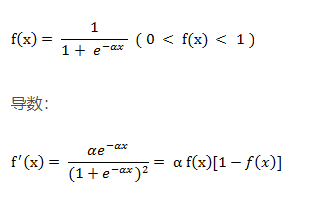
2、双极性S函数
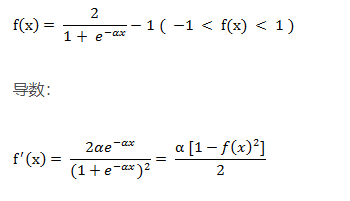
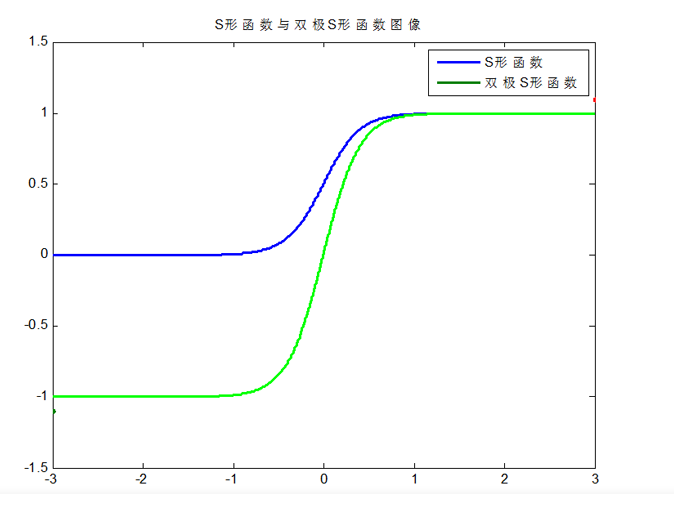
两种函数的对比:
3、几种神经网络模型(基石)
1、前馈神经网络(Feedforward Neural Networks)
前馈网络又称为前两网络
模型如图:
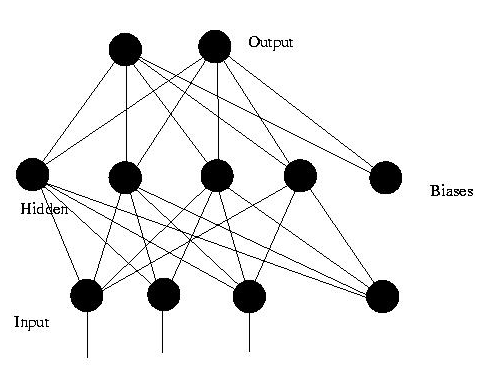
这是一个三层的前馈神经网络,其中第一层是输入单元,第二层称为隐含层,第三层称为输出层(输入单元不是神经元,因此图中有2层神经元)
这种网络只在训练过程中会有反馈信号,而在分类过程中数据只能向前传送直到到达输出层,层间没有向后的反馈信号。
感知机与BP神经网络就属于前馈网络。
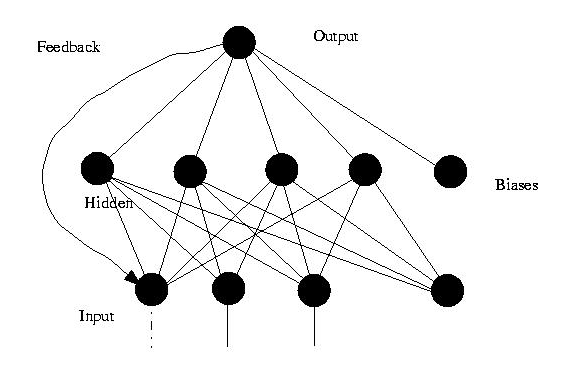
2、反馈神经网络(Feedback Neural Networks)
反馈神经网络是一种从输出到输入具有反馈连接的神经网络,经典的反馈型神经网络有:Elman网络和Hopfield网络。
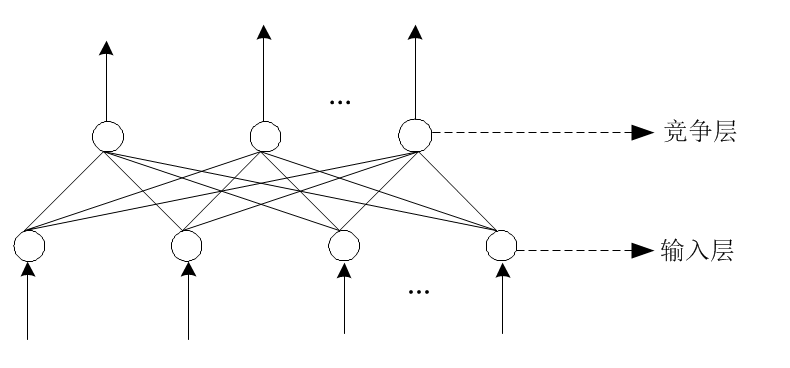
3、自组织网络(SOM,Self-Organizing Neural Networks)
自组织神经网络是一种无导师学习网络。它通过自动寻找样本中的内在规律和本质属性,自组织、自适应地改变网络参数与结构。
二、模型训练过程
神经网络中最基本的思想:先“蒙”一个结果,姑且称它为预测结果a,看看这个预测结果和事先标记好的训练集中的真实结果y之间的差距,然后调整策略,再试一次,这一次不再是“蒙”了,而是有依据地向正确的方向靠近,如此反复多次,一直到预测结果和真实结果之间相差无几(即|a-y|趋于0)才结束训练。在神经网络训练中,我们把“蒙”叫做初始化,可以随机初始化,也可以根据以往的经验给定初始值(有技术含量地“蒙”)。 //我觉得这一个总体纲领关于其他的一些细节都是在这个总体纲领下慢慢完善优化。
简单的神经网络的训练过程包括以下几个步骤:
1、定义一个包含多个可学习参数(权重)的神经网络;
2、对输入的数据集进行迭代计算;
3、通过多层网络结构来处理输入数据;
4、计算损失值(输出值与目标值的差值);
5、反向传播梯度到神经网络的参数中;
6、根据更新规则来更新网络中的权重值。
神经网络训练及参数更新流程图:
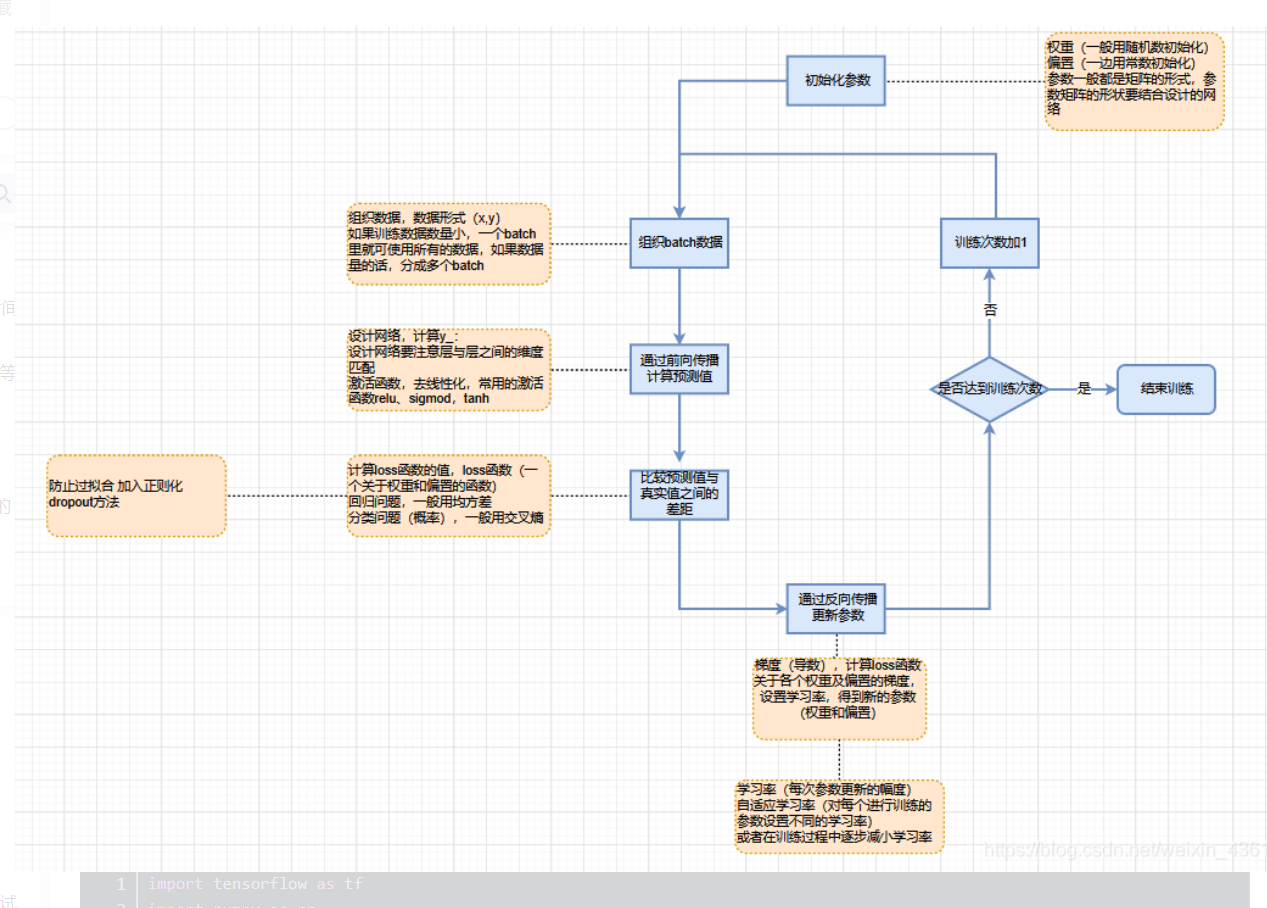
下面来根据这张图进行说明。
1、构建数据集
训练集:模型用于训练和调整模型参数
验证集:来验证模型精度和调整模型超参数
测试集:验证模型的泛化能力
因为训练集和验证集是分开的,所以模型在验证集上面的精度在一定程度上是可以反映模型的泛化能力。在划分验证集的时候需注意验证集的分布应该与测试集尽量保持一致,不然模型在验证集上的精度就失去了指导意义。
验证集的划分主要有如下几种方式:
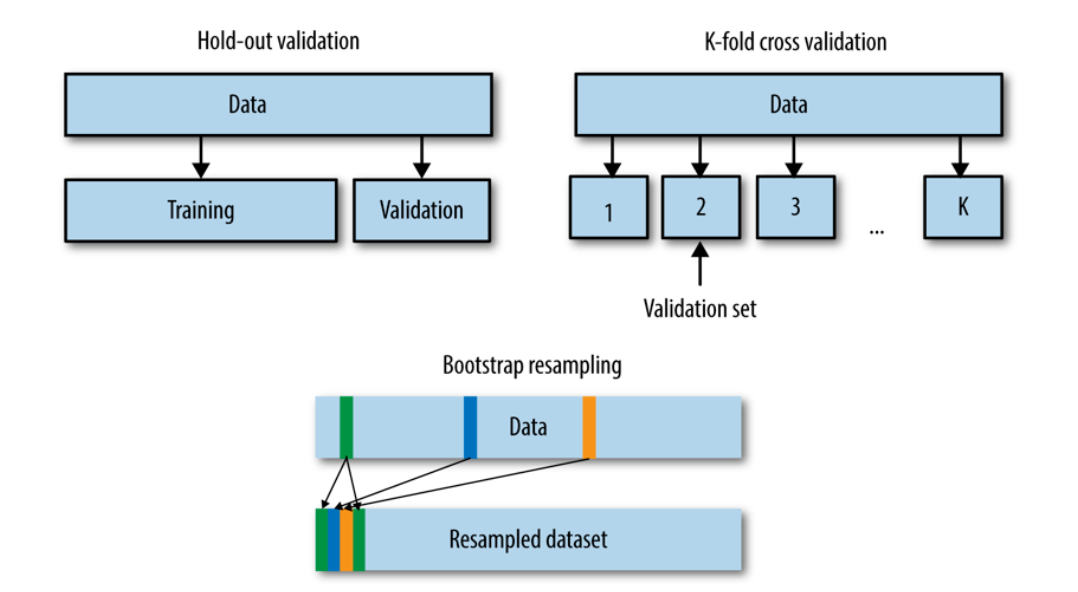
留出法:直接将训练集划分成两部分,新的训练集和测试集。这种划分方法的优点是最为直接简单;缺点是只得到了一份验证集,有可能导致模型在验证集上过拟合。留出法的应用场景是数据量比较大的情况。
交叉验证法(Cross Validation):将训练集划分成K份,将其中的K-1份作为训练集,剩余的一份作为验证集,循环K训练。这种划分方法是所有的训练集都是验证集,最终模型验证精度是K份平均得到。这种方式的优点是验证集精度比较可靠,训练K次可以得到K个有多样性差异的模型;CV验证的缺点是需要训练K次,不适合数据量很大的情况。
自助采样法:通过有放回的采样方式得到新的训练集和验证集,每次的训练集和验证集都是有区别的。这种划分方式一般适用于数据量较小的情况。
2、防止过拟合的几个方法
1、正则化方法。正则化包括L0正则化,L1正则、L2正则,而正则一般是在目标函数之后加上对于的范数,机器学习中一般使用L2正则化。
2、数据增强(Data augmentation)。增大数据的训练量,还有一个原因就是我们用于训练的数据太少了导致的,训练数据占总数据的比例过小。
4、提前终止法 ,对模型的训练的过程即是对模型的参数进行学习更新的过程,这个参数学习的过程往往会用到一些迭代优化方法,比如梯度下降学习算法。提前终止法便是一种迭代数次截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合(这种方法我没有看懂)
5、丢弃法。这个方法在神经网络中很常用。丢弃法是ImageNet中提出的一种方法,通俗一点讲就是在训练的时候让神经元以一定的概率不工作。如图:
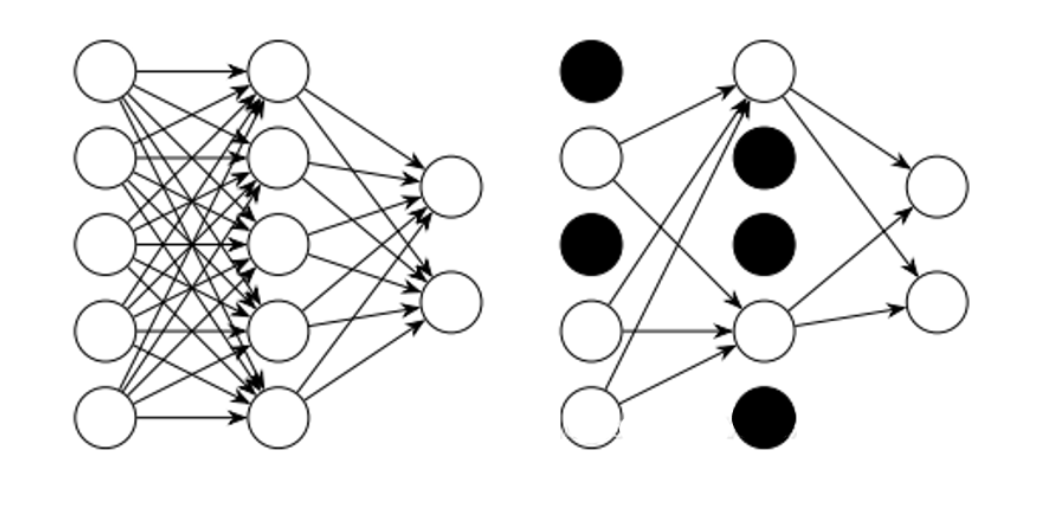
左侧为全连接网络,右侧的网络以0.5的概率丢弃神经元。
1、防止欠拟合的几个方法:
1、添加其他特征项:有时候我们的模型出现欠拟合的时候是因为特征项不够导致的,可以添加其他特征项来很好地解决。例如,“组合“、”泛化"、“相关性”三类特征是特征添加的重要手段,无论在什么场景,都可以照葫芦画瓢,总会得到意想不到的效果。出上面的特征之外,“上下文特征”、“平台特征”等等,都可以作为特征添加的首选项。
2、添加多项式特征:****机器学习中普片应用的算法,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强。
3、减少正则化参数,正则化目的是用来防止过拟合,但是现在模型出现了欠拟合,则需要减少正则化参数。
2、模型训练和验证
我认为模型的训练过程本质上是参数的自我学习与更新的过程
神经网络的循环过程
如下:
1,输入进来神经网络(每个神经元先输入值加权累加再输入激活函数作为该神经元的输出值),前向传播,先用初始化的矩阵将输入转换成和输出类似的形式,得到得分。
2、将得分输入损失函数loss function(正则化乘法,防止过度拟合),与期待值比较得到误差,通过误差判断识别成都(损失值越小越好)。
4、通过反向传播(反向求导的过程,误差函数和神经网络中每个激活函数都要求,目的是使误差最小)来确定梯度向量。
5,根据获取的梯度,更新梯度。具体的过程是通过梯度向量来调整每一个权值,向“得分”使误差趋于0或者收敛的趋势调节(SGD算法)
6、重复每一个epoch,直到损误差失的平均值不再下降(最低点)。
整个流程大致就是一个epoch,在实际场景的神经网络训练中,这样的循环可能都是成百万次,千万次级别的。
计算loss就是那个所谓的交叉熵损失函数的计算(通过初始的我们给予模型的参数来进行的训练,也就是随机种子)
更新梯度就是优化算法,各种梯度下降之类的。
模型训练的过程应该会有很多的笔记,但是现有的各种库调用一个函数就完全能训练好一个模型,虽然代码的实现过程非常容易,
但是内部原理的事项我觉得是非常重要的。
整个的这个过程还有大量的细节没有完全搞明白,现在只是能上手用而已。包括各种参数,各种推导公式都是需要继续学习的。
下面写一些细节:
1、权重初始化
在深度学习中,神经网络的权重初始化方法对(weight initialization)对模型的收敛速度和性能有着至关重要的影响。说白了,神经网络其实就是对权重参数w的不停迭代更新,以期达到较好的性能。在深度神经网络中,随着层数的增多,我们在梯度下降的过程中,极易出现梯度消失或者梯度爆炸。因此,对权重w的初始化则显得至关重要,一个好的权重初始化虽然不能完全解决梯度消失和梯度爆炸的问题,但是对于处理这两个问题是有很大的帮助的,并且十分有利于模型性能和收敛速度。
随机种子
即高斯分布的方法随机设置参数,这是最为传统的方法
深度学习网络模型中初始的权值参数通常都是初始化成随机数
而使用梯度下降法最终得到的局部最优解对于初始位置点的选择很敏感,为了能够完全复现作者的开源深度学习代码,随机种子的选择在一定程度上能够减少算法结果的随机性,也就是更趋于原始的作者的结果,产生随机种子意味着每次运行产生的随机数都是相同的。
在大多数情况下,即使设定了随机种子,仍然没有办法完全复现paper中所给出的模型性能,这是因为深度学习代码中除了产生随机数中带有随机性,其训练的过程中使用 mini-batch SGD或者优化算法进行训练时,本身就带有了随机性。因为每次更新都是从训练数据集中随机采样出batch size个训练样本计算的平均梯度。作为当前step对于网络权值的更新值,所以即使提供了原始代码和随机种子,想要复现作者paper中的性能也是非常困难的。
2、一些优化技巧
前两天看到一个博客给了一个优化的技巧:(但还未实践)
将一个模型进行过拟合化训练(即专注于训练损失),然后适当对其进行正则化(即放弃一些训练损失以获得验证损失)。
此阶段的一些技巧:
1、选择模型:为了减少训练损失,您需要为数据选择合适的体系结构。
2、Adam是安全的。在设定基准的早期阶段,我喜欢以3e-4的学习率使用Adam 。以我的经验,亚当更宽容超参数,包括不良的学习速度。对于ConvNets,调整良好的SGD几乎总是比Adam稍胜一筹,但是最佳学习率区域要狭窄得多且针对特定问题。
3、一次只使一个复杂化。如果您有多个信号要插入您的分类器,我建议您将它们一个接一个地插入,并每次确保获得预期的性能提升。
4、不要相信学习率衰减的默认值。如果您要重新使用其他领域的代码,请务必小心学习率。
一些其他问题
1、收敛速度慢
深度学习实际是一个反复调整模型参数的过程。收敛速度多慢导致训练时间过长一方面在总时间内迭代次数变少映像准确率,另一方面使得训练次数变少,减少了尝试不同超参数的机会。
1、设置合理的初始化权重W和偏置b
模型训练的本质就是调整w和b的过程,也就是weight和bias。根据奥卡姆剃刀法则,模型越简单那越好,我们通过线性函数这种最简单的表达式来提取特征也就是
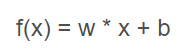
关于初始化w和b,前面已经说过传统的使用高斯分布的方式来初始化,但是这种初始化方式效果并不好。
2、优化学习率
模型训练是在不断尝试调整不同的w和b,学习率就是每次调整的幅度是多少。w和b是在一定范围内调整的,增大学习率会减少迭代次数加快了训练速度,但是学习率太大容易跳过局部最优解降低准确率,学习率太小会增加迭代次数加大训练时间。
解决方法:
一开始可以学习率大一些从而加快收敛。在训练的后期学习可以小一点从而稳定的落入局部最优解。使用Adam、Adagrad等自适应优化算法可以实现学习率的自适应调整,从而保证准确率的同时加快收敛。
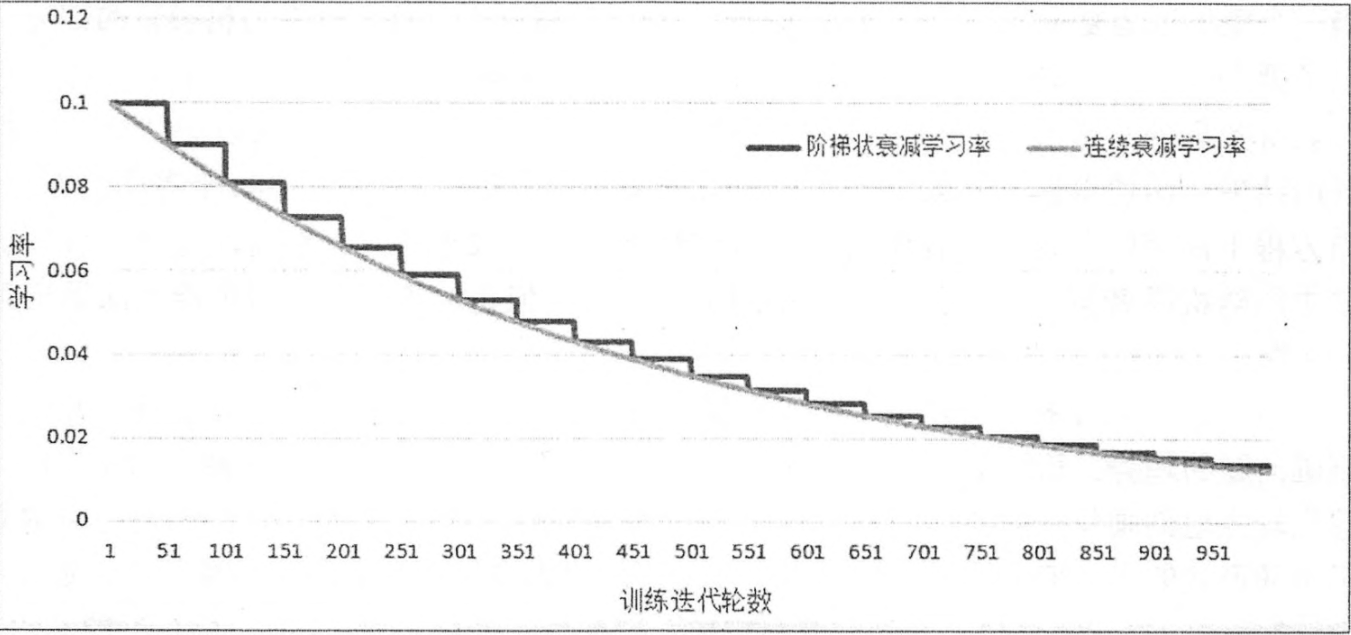
3、网络节点输入值正则化 batch normalization
神经网络训练时,每一层的输入分布都在变化。不论输入值大还是小,我们的学习率都是相同的,这显然是很浪费效率的。而且当输入值很小时,为了保证对它的精细调整,学习率不能设置太大。我们可以让输入值标准化得落到某一个范围内,比如[0, 1]之间呢,这样我们就不必为太小的输入值而发愁了。
解决方法:
由于我们学习的是输入的特征分布,而不是它的绝对值,故可以对每一个mini-batch数据内部进行标准化,使他们规范化到[0, 1]内。这就是Batch Normalization,简称BN。它在每个卷积层后,使用一个BN层,从而使得学习率可以设定为一个较大的值。使用了BN的inceptionV2,只需要以前的1/14的迭代次数就可以达到之前的准确率,大大加快了收敛速度。
4、采用更先进的网络结构
如何用较少的参数量达到较高的精度,一直是构建网络模型的难点。
目前的几种方式:(卷积神经网络中)
使用小卷积核来代替大卷积核。VGGNet全部使用3x3的小卷积核,来代替AlexNet中11x11和5x5等大卷积核。小卷积核虽然参数量较少,但也会带来特征面积捕获过小的问题。inception net认为越往后的卷积层,应该捕获更多更高阶的抽象特征。因此它在靠后的卷积层中使用的5x5等大面积的卷积核的比率较高,而在前面几层卷积中,更多使用的是1x1和3x3的卷积核。
使用两个串联小卷积核来代替一个大卷积核。inceptionV2中创造性的提出了两个3x3的卷积核代替一个5x5的卷积核。在效果相同的情况下,参数量仅为原先的3x3x2 / 5x5 = 18/25
1x1卷积核的使用。1x1的卷积核可以说是性价比最高的卷积了,没有之一。它在参数量为1的情况下,同样能够提供线性变换,relu激活,输入输出channel变换等功能。VGGNet创造性的提出了1x1的卷积核
非对称卷积核的使用。inceptionV3中将一个7x7的卷积拆分成了一个1x7和一个7x1, 卷积效果相同的情况下,大大减少了参数量,同时还提高了卷积的多样性。
depthwise卷积的使用。mobileNet中将一个3x3的卷积拆分成了串联的一个3x3 depthwise卷积和一个1x1正常卷积。对于输入channel为M,输出为N的卷积,正常情况下,每个输出channel均需要M个卷积核对输入的每个channel进行卷积,并叠加。也就是需要MxN个卷积核。而在depthwise卷积中,输出channel和输入相同,每个输入channel仅需要一个卷积核。而将channel变换的工作交给了1x1的卷积。这个方法在参数量减少到之前1/9的情况下,精度仍然能达到80%。
全局平均池化代替全连接层。这个才是大杀器!AlexNet和VGGNet中,全连接层几乎占据了90%的参数量。inceptionV1创造性的使用全局平均池化来代替最后的全连接层,使得其在网络结构更深的情况下(22层,AlexNet仅8层),参数量只有500万,仅为AlexNet的1/12
2、过拟合问题
在一定次数的迭代后,模型精确度在训练集上越来越好,但是在测试集上越来越差。原因是模型学习了太多无关特征,将这些特征认为是目标所应该具备的特征导致的。
3、梯度弥散,无法使用更深的网络
深度学习利用正向传播来提取特征,同时利用反向传播来调整参数。反向传播中梯度值逐渐减小,神经网络层数较多时,传播到前面几层时,梯度接近于0,无法对参数做出指导性调整了,此时基本起不到训练作用。这就称为梯度弥散。梯度弥散使得模型网络深度不能太大,但我们都知道网络越深,提取的特征越高阶,泛化性越好。因此优化梯度弥散问题就很重要了
1、relu函数代替simoid激活函数
sigmoid函数值在[0,1],ReLU函数值在[0,+无穷]。relu函数,x>0时的导数为1, 而sigmoid函数,当x稍微远离0,梯度就会大幅减小,几乎接近于0,所以在反向传播中无法指导参数更新。
2、残差网络
resNet将一部分输入值不经过正向传播网络,而直接作用到输出中。这样可以提高原始信息的完整性了,从而在反向传播中,可以指导前面几层的参数的调整了。如下图所示。
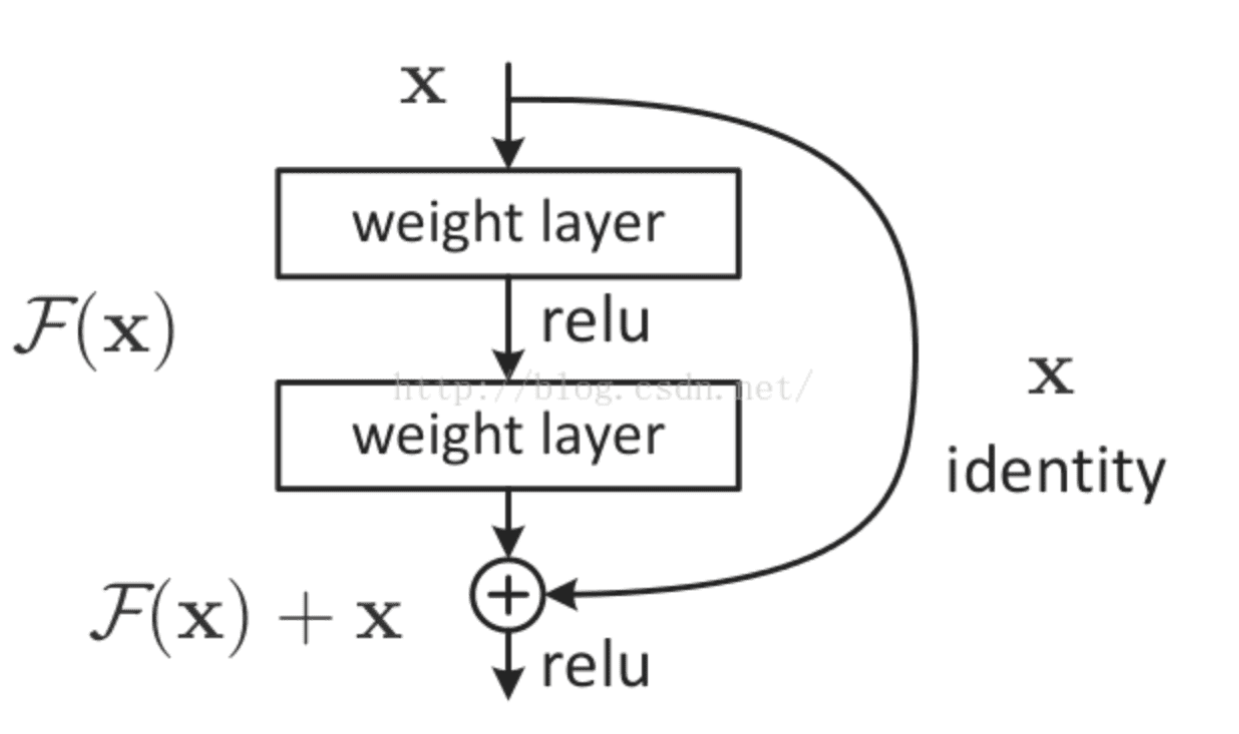
使用了残差网络的resNet,将网络深度提高到了152层,大大提高了模型的泛化性,从而提高了预测准确率,并一举问鼎当年的imageNet冠军!



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!