词法分析(四):DFA的化简
虽然本篇博客冠名以词法分析,但是DFA的化简对于词法分析来说不是必要的
它仅仅是自动机理论的一部分,甚至,你不需要自动机理论,也可以手打出来一个Tokenizer
但是自动机理论是词法分析器的自动产生工具的理论
自动化并且简化
要不然何以称之为屠龙之术?(虽然前端技术可能只是屠龙术的起式 )
(词法分析的理论我都看了有一周了,还没着手实现,好tm难 )
DFA的化简(最小化)
DFA的化简(最小化):对于给定的DFA M,寻找一个状态数比M少的DFA M’,使得L(M)=L(M’)
状态的等价性:
若 s 和 t 为 M 的两个状态,如果从状态 s 出发可以读出字 α 而停止于终态,
从 t 出发也同样能读出 α 而停止于终态,反之亦然,则称它们是等价的
两个状态不等价,则称它们是可区分的
(存在一个字可以由状态 s 读出且停止在终态,而不能由状态 t 读出停止在终态,则状态 s 和状态 t 是可区分的)
DFA的化简即是状态集按等价类的划分
- 使任何两个不同的子集中的状态是可区分的,而同一状态中的任意状态间是等价的
- 任何两个子集均不相交
- 最后每个子集保留一个状态
DFA的化简过程
由 ε 可以将DFA的状态集区分为 终态 和 非终态 两个子集,形成基本划分Π
假定某个时候,Π包含m个子集,即为Π={I(1),I(2),……,I(m)},检查Π中的每个子集是否可以进一步划分
检查方法如下:
- 对某个 I(i),设 I(i) = {s1,s2,……,sn},
- 若存在一个输入字符a使得 Ia(i)不包含在任何一个现行Π的某个子集 I(j)中,则 I(i)至少应该分为两部分
(若s1与s2经过字符a输入后,到达两个不同的状态集,而存在字 α 可以区分这两个状态集,所以字 aα 是可以区分状态s1与s2的,即s1与s2不等价)
接下来按字符a将 I(i) 分割成分别包含s1与s2的两部分 I(i1) 和 I(i2)
- I(i1)含有s1,I(i1) = {s|s∈I(i)且 s 与 s1 经 a弧 到达同一个现行Π的子集}
- I(i2)含有s2,I(i2) = I(i) - I(i1)
分隔出的新子集应添加到检查队列中,判断能否进一步进行划分
一般来说,对某个字符 a 和 子集 I(i),若 Ia(i) 落入现行Π的N个不同子集中,
则应该把 I(i) 按接收字符 a 落入的子集是否相同划分为 N 个不相交的子集
划分完成后,选取每个子集 I 中的一个状态代表该子集,
含有原来初态的子集选出的状态为新的初态,含有原来终态的子集选出的状态为新的终态
化简如下DFA
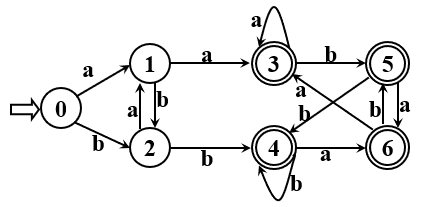
I = {0,1,2,3,4,5,6},其中终态为{3,4,5,6}
∴初始划分为 I(1) = {3,4,5,6},I(2) = {0,1,2}
等待划分的子集有 I(1)、I(2),Π = {I(1),I(2)}
检查 I(1) 是否可以按字符 a 或 b 进行划分,Ia(1)包含于 I(1) ,Ib(1)也包含于 I(1) ,
即 I(1) 中各状态是等价的,无须划分
等待划分的子集有 I(2),Π = {I(1),I(2)}
检查 I(2) 是否可以按字符 a 进行划分,Ia(2) = {1,3},分别落在I(1)和I(2)中,
因此将 I(2) 划分为 I(21) = {0,2},I(22) = {1}
等待划分的子集有 I(21)、I(22),Π = {I(1),I(21), I(22)}
检查 I(21) 是否可以按字符 a 划分,(其实已经检查过了 ), Ia(21) 包含于 I(22),
检查 I(21) 是否可以按字符 b 划分,Ib(2) = {2,4},分别落在 I(21) 和 I(1) 中,
因此将 I(21) 划分为 I(211) = {0}, I(212) = {2}
等待划分的子集有 I(22)、I(211)、I(212),Π = {I(1),I(22),I(211),I(212)}
I(22)大小为1,无须继续划分
I(211)大小为1,无须继续划分
I(212)大小为1,无须继续划分
划分完毕,Π = {I(1),I(22),I(211),I(212)}
I(1) = {3,4,5,6},I(22) = {1},I(211) = {0},I(212) = {2}
则保留状态 0、1、2、3,其中0为初态,3为终态
按照转换关系,得到化简结果如下
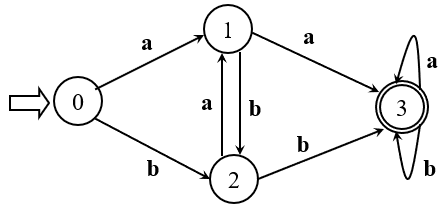
没错,就是酱紫
小结
DFA的化简的要点:
状态的等价和可区分
最小化算法
2019/7/23

 浙公网安备 33010602011771号
浙公网安备 33010602011771号