


一个可执行文件的诞生
前言
作为一个初级程序员,在第一次跑通“hello world”这个经典程序的时候。就总在思考这个程序到底需要经过怎么样的处理,才可以在计算机上面成功运行。但是那个因为相关的基础知识比如计算机组成原理、操作系统等相关的基础知识还没有掌握。所以一直到学习了计算机这么久之后才开始比较系统的了解这个过程。那么这一系列文章就是解决“一个可执行文件的诞生”。
一、基础知识回顾
一个程序从源代码文件到可执行文件,会经过四个过程——预处理、编译、汇编、链接。到此一个可执行文件已经产生了。当我们执行这个文件的时候,该可执行文件会被加载到内存,接下来就是CPU从这个被加载到内存中的文件中取指令,进行运算最后得到目标结果。显然,上面的表述还是太过简略。但是没关系现在我们要做的就是先对基础知识进行回顾,为我们后面的学习打下基础。
首先我们先简单回顾一下操作系统的知识。操作系扮演的角色其实就是整个计算机的资源管理者。而操作系统管理的资源包括文件系统管理、I/O设备管理、存储空管理、进程管理以及网络相关的资源。咱们既然是讲一个可执行程序的诞生那么我们首先主要讲一下进程管理这一小部分。
进程是什么?进程就是计算机资源分配的最小单位。怎么理解比较好呢?我们从我们写的程序入手,借用一下我之前在一本书上的描述。进程如同是一个舞台,而我们写的程序就是舞台上面的演员。如果没有舞台,演员没有办法进行表演。如果没有进程,我们的程序也无法运行。
1.1单批道系统
在最古老的单批道系统之下,咱们程序的运行是一个相对简单的过程,一个程序一旦被允许执行,那么其它想要执行的程序只有排队等它执行完毕后才可以继续执行。这个进程会霸占内存以及CPU全部资源,当然这里我们没有讨论内存里面的监管程序,同时也没有讨论我们主动杀死一个进程。这个就是单任务系统的特点,比如DOS系统就是一个单批道系统。
1.2多任务
当然,咱们现在都是站在巨人的肩膀上面,接触的都是多任务系统。“知其然而知其所以然”,我还记得我之前上相关课程或者看相关博客的时候,老师们都会举一个类似的例子,如果当前程序不需要使用CPU,而是在等待IO,比如等待键盘输入。那么我们的CPU是不是空闲下来了,这个不就是浪费了CPU这么宝贵的资源吗?所以为了尽最大的可能"压榨"CPU,我们最好设计一个多批道操作系统,让CPU时刻都在运行。
现在我们来深刻的体会一下,CPU等待一个IO,到底会有多浪费!假设键盘输入需要1秒钟,那么我们CPU在等待这个的1秒钟可以执行多少条指令呢?我现在以我的计算机为例,它的主频是1.6GHZ(时钟周期约0.625ns),假设我的电脑总线周期是12个时钟周期即7.5ns,然后在假设指令周期等于4个总线周期。那么在1秒钟我的电脑可以执行3百多万条指令。虽然上面的MIPS(备注:(Million Instructions Per Second):单字长定点指令平均执行速度 Million Instructions Per Second的缩写),是我估算的,情景也比较简单,但是误差再大,我们也可以肯定它的执行速度在百万级别。当然更直接的方式就在在网上查一下。这浪费的一秒钟,拿去执行一个其它的程序不可以吗?它不香吗?计算MIPS。
现在大家应该对CPU资源浪费这个概念应该有了一个度的认识。那么咱们了解多任务系统就不在是无源之水。操作系统任务调度算法,大家可以自行去了解一下,网上一搜一大把。了解一下思想就好了。
1.3多线程
哎呀!刚刚才介绍了进程,现在这个线程又是什么东西?头疼。其实我们可以简单的理解一下,一个进程就是由多个线程组成的。线程的定义可就是:计算机最小的执行单位。其实呢,在还只有进程概念的时候,进程即是资源分配的基本的单位又是可执行的基本单位。但是经过不停的发展,计算机科学学者发现,把进程当做一个可执行的单位还是不行,还是浪费资源,拖慢了计算机执行程序的速度。所以又提出了线程的概念。
那么,线程又是如何提高计算机资源的使用效率的呢?这里咱们可以稍作讨论。我们知道一个进程必然会拥有一个完整的内存映射。(不知道,没关系,稍后一点会讲)假设现在某个进程正在等待IO事件发生。我们可以暂时把它调出内存,阻塞掉。在这个进程切换过程中我们还需要做很多额外的事情,比如进程内核栈的切换、进程用户堆栈切换、寄存器内容以及虚拟空间的切换。但是如果是切换线程的话,整个过程就就会稍微简单一点,因为线程共享内存的虚拟地址,所以它的切换只会有现场寄存器保存和用户空间堆栈保存两个额外操作。而且进程切换最耗费时间的操作就是虚拟空间重新映射这个操作,由此看来多进程技术的效率确实比多线程技术要低一些。
刚才讲的东西可能还是会偏向理论,那么现在我们来举一个例子。假设现在我们打算开发一个非常小型的Web服务器项目,现在有36个客户端同时向服务器请求资源。为了提高服务器的处理速度,你觉得应该用多线程技术还是用多进程技术?答案应该是多线程,至于为什么,其实大家仔细想一想应该都会想得通,等我组织好语言再来写一写威为什么。(注: 其实在linux系统下面多进程技术更加成熟,多线程就显得可有可无。可是,在windows系统下面多线程技术非常成熟,并且有一套专门的标准。)
1.4内存管理
上面咱们讨论了进程的相关内容,现在再来看看内存方面的内容。首先我们应该了解的是,计算机为我们提供的内存,我们并没有全部的掌控权利(我的意思是,应用程序没有权限使用全部的内存空间)。为了保护整个计算机资源的安全性,我们的内存被分成了两个部分。内核空间和用户空间。假设我的计算机是4G的内存,那么咋linux下面它将有1G是属于内核空间,剩下的3G才是用户可以利用访问的空间。而windows下面则是对半分一方2G。
这里咱们要回忆一下,计算机发展初期的对内存的操作。毕竟“忆苦思甜”是个好习惯,让我么好好珍惜现在。在还没有提出
虚拟地址和逻辑地址这两个概念之前,命令中使用的地址全部都是物理地址。如果咱们是在一个单批道系统中其实不用考虑这么多,只要咱们的程序需要的空间小于内存可利用的空间就万事大吉了。奈何咱们现在更喜欢多任务的运行环境。那么运用直接
物理地址会存在以下问题:
1、进程间地址空间不隔离,会造成不同进程有意或者无意的去访问了别的进程的地址空间。你自己的东西,你希望其它人可以随意的使用吗?进程也是这样,它并不希望有除它以外的进程去访问它。
2、内存的使用率低下。如果我们要执行某个程序时,发现内存没有办法提供足够多的内存,这个时候就需要将内存中的某一个程序调换出内存。这样一会就会造成,随着用户需要不同进程被唤醒,进程被不停的调出调进内存。
3、程序每次运行的地址都不确定。由于每一次程序加载进入内存的位置都是不固定的,这给我们编写程序造成了很大的困难。
我们可以联想一下自己写代码,什么时候关心过它到底被加载到了那一块内存,从那一块地址开始运行?当然没有,如果这些还要我们作为一个高级程序员来考虑的话,那么计算机专业就不会那样有生机了。那么为了解决直接使用物理地址的困境,科学家们首先提出的就是分段访问内存,为每一个可执行程序分一个单独的段,这个段的大小就是可执行程序的大小。这样咱们的进程空间隔离性就基本解决了。当然也不需要每次都直接得到指令需要的物理地址,而是得到一个逻辑地址,通过程序指令的起始地址加上指令的偏移量就可以访问到真正的地址。这样咱们地址的总是不确定那一块也基本解决了。但是内存空间的使用率还是不高。因为我们执行一个程序仍然要将整个进程加载进入内存空间。所以,又有了一个升级版的方式———分页。
分页的意思就是,操作系统将内存空间按页来划分。分配内存的时侯也以页为单位。之前咱们也讲过现代的操作系统为每一个进程都分配了一个4G的虚拟空间。其实我们知道,就算我们提供了4G的内存我们也没有办法办法全部使用。但是咱们总是喜欢“强机器所难”,没有条件也要创造条件来实现!我们将可执行程序分页装入,一般不会完全装入整个程序。根据程序执行的局部原理,我们会将部分页驻留在内存,如果发现某个将要使用的页不在内存里面就会触发缺页中断,将该页调入内存。(备注: 这里讲的东西都比较简陋,大家想要在仔细了解下分页系统到底怎么使用,程序中的虚拟地址怎么转换为物理地址可以看一下百度百科,很实在。分页)
二、聊一聊链接
备注:若没有特别备注,以下所有程序的运行环境都将是32位x86环境下面。
大家觉得生成一个可执行文件。其中最重要的是哪一步呢?哈哈哈,我个人觉得没有最重要的一步,倒是有一个最简单的一步,那就是预编译阶段。它主要完成的工作包括:
- 1、展开#include、删除所有注释。
- 2、删除所有#define并且展开它。
- 3、处理所有条件编译比如#if #endif #ifdef。
- 4、添加行号和文件标识名,以便编译时产生调试用的行号信息以及编译错误是可以显示行号。
- 5、保留所有#program编译指令。我们可以使用 gcc中的-E指令来得到预处理后的文件。
所用命令:
gcc -E XXX.c -o XXX.i
接下来的三个步骤,都需要花费比较多的精力去了解它们设计的原理。比如编译过程就是一个单独的知识点。因为我这篇文章主要讨论的还是一个可执行文件的格式意见大致的一个诞生过程。所以也只会简单的介绍一下。(感兴趣的同学可以直接去了解一下编译原理)
- 1、对预编译生成的文件进行词法分析,生成符号表。
- 2、进行语法分析,得到语法树。
- 3、进行语义分析。
所用命令:
gcc -S XXX.c -o XXX.s
然后是汇编操作,将汇编文件转换为机器文件。毕竟高级语言都是为人服务,计算机只认得机器语言。其实这一步得到的目标文件已经十可执行文件的格式了,但是为了代码的可维护性,我们需要模块化编程。不同模块中的内容会有交叉应用。故而还需要连接这一步。
as XXX.s -o XXX.o
或者
gcc -c XXX.c -o XXX.o
最后,也是我们需要着重讲解的一步——链接,那么链接过程主要的任务就是把各个不同的模块组合起来得到有个真正可以执行的程序。它要做的包括了地址和空间分配、符号决议和重定位。
2.1目标文件的格式
一般大家在windows编程上面生成的可执行文件是什么呢?在linux下面又是什么呢?答案是,windows下面的可执行文件格式是PE,而linux下面的可执行文件格式是ELF文件。虽然是两个不同名称的可执行文件的格式,但是它们的COFF文件的变种。换言之,它们就是实现框架下面的不同实现。现在咱们看看linux下面ELF文件类型。

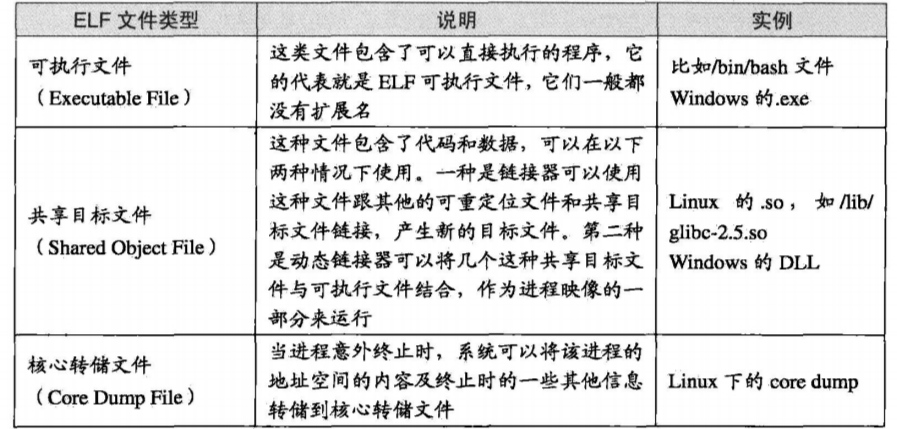
但是这一节我们只是暂时了解一下可执行文件,目标文件才是我们的核心。目标文件其实就是还没有链接的中间文件。那么目标文件里面将会与一些什么信息呢?毋庸置疑,我们应该想到目标文件里面需要有汇编后的机器指令,需要有进行链接的符号表,也许还应该选择性的出现一些调试的信息……当然这些东西都是有的。目标文件会将这些不同属性的信息,以“节”的顺序来存储,有的时候也叫做“段”。接下来咱们通过一段及其简单的代码来进行该知识点的讲解。
#include <stdio.h>
int main()
{
//经典代码——Hello World
printf("Hello World!\n");
return 0;
}
//生成目标文件
gcc -c hello.c
接下来我们可以使用命令:objdump -h hello.o来打印一下目标文件中各个段的信息。
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 00000017 0000000000000000 0000000000000000 00000040 2**0
CONTENTS, ALLOC, LOAD, RELOC, READONLY, CODE
1 .data 00000000 0000000000000000 0000000000000000 00000057 2**0
CONTENTS, ALLOC, LOAD, DATA
2 .bss 00000000 0000000000000000 0000000000000000 00000057 2**0
ALLOC
3 .rodata 0000000d 0000000000000000 0000000000000000 00000057 2**0
CONTENTS, ALLOC, LOAD, READONLY, DATA
4 .comment 0000002a 0000000000000000 0000000000000000 00000064 2**0
CONTENTS, READONLY
5 .note.GNU-stack 00000000 0000000000000000 0000000000000000 0000008e 2**0
CONTENTS, READONLY
6 .eh_frame 00000038 0000000000000000 0000000000000000 00000090 2**3
CONTENTS, ALLOC, LOAD, RELOC, READONLY, DATA
上面这一段文字,大家现在可能还是不清楚它的具体含义,没关系我们现在就来解释一下。首先.text:这一个段就是咱们的指令段。.data :数据段,存放已经初始化全局变量局部静态变量。.bss存放未初始化的全局变量和局部静态变量。以及一些其它的段,请参看下面这个表格:
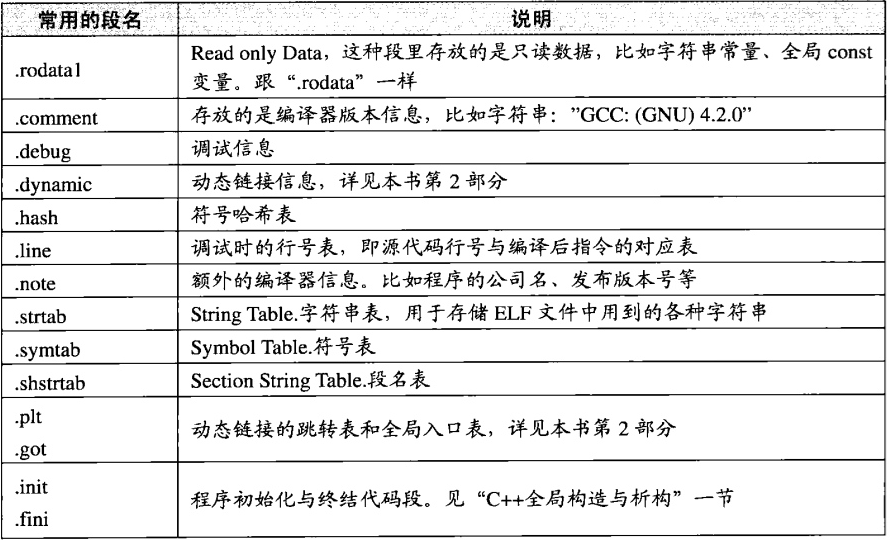
备注:咱们现在看到的段的名字都是以 “.” 开头的,但是我们其实也可以自定义段。大家有兴趣的可以自行了解一下。
经过刚才的简单的介绍,咱们应该丢ELF文件的基本轮廓有了大概的印象。现在咱们看一下ELF文件的核心结构:
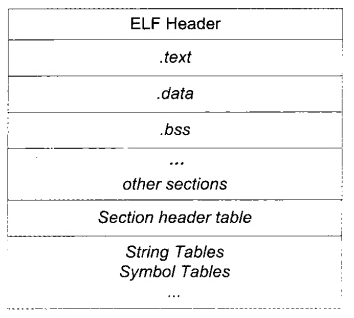
首先ELF Header:ELF文件头。接下来就是各个段。这个ELF问价头有什么作用呢?接下里就用命令:readelf -h hello.c来稍微研究一下问价头:
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 712 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 13
Section header string table index: 12
文件头解析:
备注:ELF头文件相关的常数常常被定义在“/usr/include/elf.h”


