

django组件-rest_framework(下)
解析器
request.body为请求体原始数据,并在headers中的content-type字段指定该请求体的数据格式,默认情况下,数据格式指定为application/x-www-form-urlencode格式,也就是"name=tom&age=18&gengde=M"这样的数据格式。django会解析request.body中的数据,将“name=tom&age=18&gengde=M”字符串数据通过&断开,得到 一个个k-v对,从而解析为字典,并保存到request.POST属性上。django默认情况下只支持application/x-www-form-urlencode类型的数据的解析。解析其他数据需要我们自己手动解析,或者使用rest_framework的解析器。
使用解析类
from rest_framework.view import APIView # 在rest_framework.parsers有多个内置的解析器,这里导入几个比较常用的 from rest_framework.parsers import JSONParser, FormParser, MultiPartParser class OrderView(APIView): # 指定该视图类需要使用的解析器,或者可以在配置文件中指定。 parser_classes = [JSONParser, ] def dispicth(self, request, *args, **kwargs): return super().dispatch(request, *args, **kwargs) def get(self, request): request.data # ==>
在视图类中使用的解析类,程序执行时,将会按照提交的请求头中的content-type字段的去加载对应的解析类解析请求体中的数据,如果能成功解析,调用request.data将能解析。
自定义解析类
如果发送和接受方使用自己的数据格式,通过自己的方式去解析数据,就需要自定义解析数据的方法。
from rest_framework.parsers import BaseParser class MyParser(BaseParser): media_type = "自定义的格式名" # rest 会根据content-type指定的数据格式名,找到该类来解析数据 def parse(self, stream, media_type=None, parser_context=None): # stream 为 reqeust.body封装BytesIO对象,可以通过文件对象的方式访问request.body中的内容 # 自定义方式解析该内容即可,返回值为data数据的值, 解析失败直接报ParseError()错,data将会None return data # ===> request.data
如果可以成功解析,使用request.data可以得到解析后的数据。调用request.data时,解析器才会去解析reqeust.body中的数据。解析过程为
- request.data,为一个property方法, 执行该方法,没有_full_data数据则调用self._load_data_and_files()方法。
- _load_data_and_files中,如果request._data没有数据,则执行self._parse()立即解析数据,并将解析后的数据赋值到request._data和request_full_data中,下次直接使用即可。
- self.parse 中,首先根据request中content-type获取数据类型名,在去我们指定的解析中寻找对应的解析器。找到对应的解析器后,调用解析器的parse(self, stream, media_type=None, parser_context=None)方法。注入body对象的ByteIO对象来解析数据即可。
全局配置
同样在配置文件中指定,所有使用了rest_framework视图类的视图都将使用这些定义的解析器解析
REST_FRAMEWORK = { 'DEFAULT_PARSER_CLASSES':[ 'rest_framework.parsers.JSONParser' 'rest_framework.parsers.FormParser' 'rest_framework.parsers.MultiPartParser' ] }
序列化器
服务间的数据交换需要我们对数据进行序列化和反序列化,也就是转化成一个特殊的格式的字符串,同时改字符串还能方便的反序列化为原来的数据结构。由于我们使用ORM框架进行表数据增删改查,数据通常封装为查询集对象,解析这些数据通常需要编写比较复杂的解析过程,来提取对象中的数据并拼凑成序列化的数据。使用rest-framework 将能方便的完成该任务。
两个功能
- 对查询结果进行序列化:定义序列化类作用到结果上即可
- 对用户提供的数据进行校验,需要使用校验器类,并在定义的字段中指定
简单数据的序列化方式
from rest_framework import serializers # 同ORM的model类相同,定义对应的字段名的类属性。用户接受对应的数据。 class UserSerlize(serializers.Serializer): # 定义序列化类,将需要序列化字段名定义为指定属性名 # 使用serializers中提供类型信息,对应数据库表中的类型 id = serializers.IntegerField() username = serializers.CharField() user_type = serializers.CharField() pwd = serializers.CharField() class OrderView(APIView): def get(self, request, *args, **kwargs): users = UserInfo.objects.filter(id__lt=10).all() # 查询的结果对象,将其进行序列化 ser = UserSerlize(instance=users, many=True) # many表示多个值 print(ser.data, type(ser.data)) ret = json.dumps(ser.data, ensure_ascii=False) return HttpResponse(ret)
定义序列化类后,直接对user查询对象解析即可,实例的data属性为解析后的数据的有序字典。
自定义序列化显示方式
UserSerlizer被定义用来专门序列化user对象,属性名和Model类的属性名相同即可对应解析数据。也可以使用source参数指定对应的字段数据,如果该字段是一个外键,对应的值为一个对象,还可以继续调用其属性得到我们想用的数据。
source参数
source参数,指定属性值来源于Model的那个字段,如果该字段对应一个对象,还可以属性访问对象的属性,如果指定为一个方法,直接调用得到结果作为值
xxx = serializers.CharField(source="user_type") # 简单获取对象 xxx = serializers.CharField(source="user_type.name") # 对象的属性 xxx = serializers.CharField(source="get_user_type_display") #get_ user_type _display为一个方法
SerializerMethodField
ModelSerializer继承于Serializer,可以更加方便的解析,同时支持灵活的定义函数来解析内容,,并支持原Serializer的即可。定义函数需要将该属性定义为xxx = serializers.SerializerMethodField()类型,并在类的定义对应的get_xxx(self, row)方法,row参数为一个数据库的行记录,对应被解析数据的一条记录,也就是一个model实例。该方法的返回值为xxx字段的序列化结果。
使用ModelSerializer
使用ModelSerilizer后,普通字段的解析不在一个个定义字段,使用Meta的fields字段可以快速指定要序列化的字段,使用__all__为全部解析,否则只会解析对应的内容。
class UserSerlizer(serializers.ModelSerializer): # 继承自ModelSerializer,解析字段 xxx = serializers.CharField(source="get_user_type_display") # get_(user_type)_display 处理choice显示 ooo = serializers.SerializerMethodField() # 复杂的显示方式,指定一个对应的函数来显示,get_ooo函数 # source参数,指定属性值来源于数据库的那个字段,如果该字段对应一个对象,还可以属性访问对象的属性 class Meta: model = UserInfo # 指定对应model类 fields = ["id", "username", "password", "xxx"] # 指定需要序列化的字段 extra_kwargs = {'user': {'min_length': 6}, 'pwd': {'validators': [PasswordValidator(666), ]}} # read_only_fields = ['user'] def get_ooo(self, row): # 对应到ooo的显示上去,获取一个行对象,因为解析的是一行行数据 group = row.group.all() # 一个用户对应的多个组, 假设组和人为多对多关系 display = [] for g in group: # 遍历出组对象,拿出每个组的名字来显示,最后显示这个用户所在的每个组的名字 display.append(g.name) return display # 返回的display的内容,就是ooo字段显示的内容。
class OrderView(APIView): # 使用序列化器 def get(self, request, *args, **kwargs): users = UserInfo.objects.filter(id__lt=10).all() # 查询的结果对象,将其进行序列化 ser = UserSer(instance=users, many=True) # many表示多个值 ret = json.dumps(ser.data, ensure_ascii=False) return HttpResponse(ret)
depth参数进行连表
为了从上面的user表中的group字段,拿到group的信息,或者其他的一对多多对多关系时候,使用depth可以方便获取。
例如user表中group外键关联了一个group对象,默认情况下depth=0,将只能拿到user表中保存的group的id信息,无法拿到该id关联的组的其他数据。depth则指定可以多次获取关联的对象。
class UserSerlizer(serializers.ModelSerializer): # 继承自ModelSerializer,解析字段 class Meta: model = UserInfo # 指定对应model类 fields = ["id", "username", "password", "group"] # 指定需要序列化的字段 depth = 1 # 结果 # depth = 0时 { id;1, username:abc, password:123, group:1 } # depth = 1时, 由于group是外键关联的对象 { id;1, username:abc, password:123, group:{ id:1, title:研发部 desc:.... } }
数据验证
使用验证器对用户提交的数据进行验证,还有django的form表单类的使用,如何使用的。
class NameVaildator: def __init__(self): self.reg = re.compile(r"^[u4e00-u9fa5]+$") def __call__(self, value): if not self.reg.fullmatch(value): msg = "用户名含有其他字符" raise serializers.ValidationError(msg) class PasswordVaildator: def __init__(self): self.reg = re.compile(r"<f>[\u4e00-\u9fa5a-zA-Z]+") def __call__(self, value): if len(value) < 6: msg = "密码长度不够" raise serializers.ValidationError(msg) class UserRegVaildator(serializers.Serializer): username = serializers.CharField(error_messages={"required": "只能使用字母中文"}, validators=[NameVaildator(),]) password = serializers.CharField(error_messages={"required": "密码长度不够"}, validators=[PasswordVaildator(),]) # 视图类 class Reg(APIView): def post(self, request, *args, **kwargs): print(request.data) ser = UserRegVaildator(data=request.POST) if ser.is_valid(): # 必须先调用,才能使用ser.validated_data print(ser.validated_data) # 验证成功 else: print(ser.errors, "=========") # 未通过验证 return JsonResponse({"m": "post"})
分页
三种分页方式
PageNumberPagination
url显示方式为 ?page=0&page_size=10
from rest_framework.pagination import PageNumberPagination class MyPgaePagination(PageNumberPagination): # 默认每页显示的数据条数 page_size = 1 # 获取URL参数中设置的每页显示数据条数 page_size_query_param = 'page_size' # 获取URL参数中传入的页码key page_query_param = 'page' # 最大支持的每页显示的数据条数 max_page_size = 1
LimitOffsetPagination
url显示方式 ?limit=10&offset100
from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination class MyLimitPagination(LimitOffsetPagination): # 默认每页显示的数据条数 default_limit = 10 # URL中传入的显示数据条数的参数 limit_query_param = 'limit' # URL中传入的数据位置的参数 offset_query_param = 'offset' # 最大每页显得条数 max_limit = None
CursorPagination
CursorPagination实现了页码的加密,用户无法通过url中查询字符串实现跳页,页码值是一个加密的字符串。这样用户只能使用提供的翻页链接。
url显示方式 ?cursor=SDFF,这是一个随机的加密数值,用户无法知道下一页的url, 只能使用提供的翻页链接
from rest_framework.pagination import LimitOffsetPagination, CursorPagination class MyCursorPagination(CursorPagination): # URL传入的游标参数 cursor_query_param = 'cursor' # 默认每页显示的数据条数 page_size = 2 # URL传入的每页显示条数的参数 page_size_query_param = 'page_size' # 每页显示数据最大条数 max_page_size = 1000 # 根据ID从大到小排列 ordering = "id"
使用Pagination
三种分页器的使用方式相同,只需要创建各自的实例即可实现不同的分页器。
class UserViewSet(APIView): def get(self, request, *args, **kwargs): user_list = models.UserInfo.objects.all().order_by('-id') # 实例化分页对象,获取数据库中的分页数据, 使用不同的分页器只需要实例化不同的类即可 paginator = MyCursorPagination() # paginator = MyLimitPagination() # paginator = MyPgaePagination() # 对user_list查询集进行分页 page_user_list = paginator.paginate_queryset(user_list, self.request, view=self) # 对该页内容进行序列化 serializer = UserSerializer(page_user_list, many=True) # 生成分页的数据和查询 response = paginator.get_paginated_response(serializer.data) return response
视图
视图类的层次关系
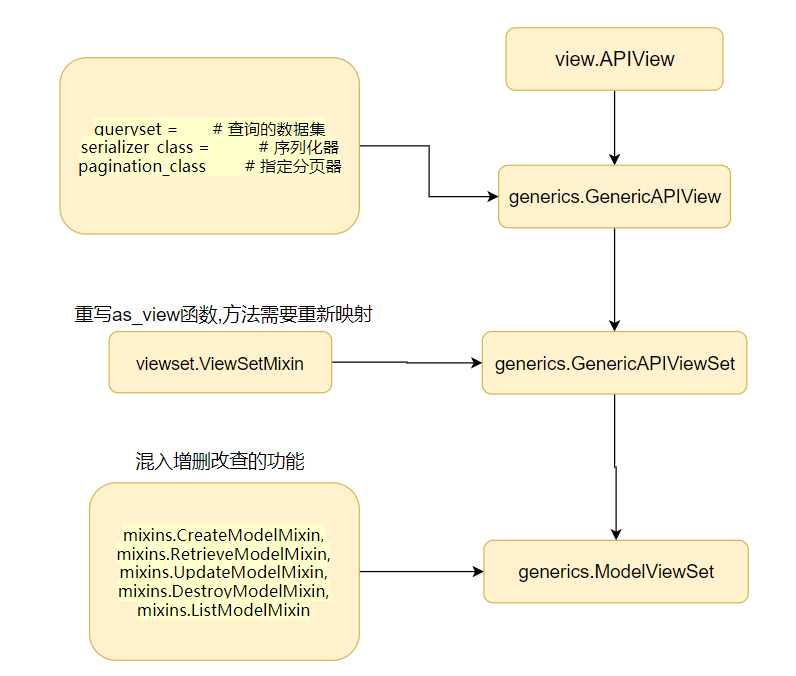
from rest_framework.generics import GenericAPIView, CreateAPIView from rest_framework.mixins import ( CreateModelMixin, # 增加一条数据 使用 post -> 定义create 方法 RetrieveModelMixin, # 获取一条数据 使用 get -> 定义retrieve方法 UpdateModelMixin, # 更新一条数据 使用 update -> 定义update方法 DestroyModelMixin, # 删除一条数据 使用 delete -> 定义destroy方法 ListModelMixin, # 获取列表数据 使用 get方法,但是路由不同,前面四个方法需要匹配id GenericViewSet ) from rest_framework.viewsets import GenericViewSet, ModelViewSet # set视图类重写了APIview的as_view()方法,新的as_view需要传入映射关系 # ModelViewSet继承了上面所有的Mixin类,并继承GenericViewSet重写了as_view(),用于分发不同的请求
以上5个Mixin视图中,分别对数据进行增删改查和列出所有数据。使用了对应类,就需要在as_view函数中进行对应的方法映射,将不同方法的请求分别映射到对应处理方法上去。以下是全部的映射配置,使用时按照需求配置即可。
urlpatterns = [ # 该url获取列表 path("orders", OrderSetView.as_view(actions={'get': 'list', 'post': "create",})), # ListMixin的list方法中 # 该url对单条数据进行增删改查 path("orders/<int:pk>", OrderSetView.as_view(actions={ 'get': 'retrieve', 'update': "update", 'delete': "destroy" })), ]
