redis进阶
redis主从复制
- 从服务(slave)从主服务(Master)同步更新数据,保持主从数据同步。
- 主服务提供读写服务,从服务只能提供读服务。
- 一个主服务可以有多个从服务。
建立主从关系
可以使用三种方式:
- 开启服务时指定该服务从属于其他redis服务。
redis-server --salveof <master-ip> <master-port>
- 启动时的配置文件中指定
salveof选项
salveof <master-ip> <master-port>
- 通过指令建立
进入客户端后,使用命令指定:salveof <master-ip> <master-port>
使用该方式建立主从关系,如果主服务发生故障,redis服务将会失去写入能力,仅能由从服务提供读能力。而从服务不会自己提升为主服务,而实现这种自动故障转移可以使用sentinel。
高可用sentinel
官方文档:http://www.redis.cn/topics/sentinel.html
sentinel是官方提供的高可用方案,可以管理多个redis服务实例,其本身也是分布式的系统,可以在不同的节点上运行sentinel进程,协同管理该redis集群服务。在默认情况下, Sentinel 使用 TCP 端口 26379 ,它的主要功能:
- 监控(Monitoring):Sentinel 会不断地检查主服务器和从服务器是否运作正常。
- 提醒(Notification):当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automatic failover):当一个sentinel检测到主服务器无法正常工作时,将会主观认为其下线,并发起投票,如果超过半数的sentinel认为其已经下线,则将其客观下线。Sentinel 会开始一次自动故障迁移操作,它会向失效主服务器的一台从服务器发送SLAVEOF NO ONE命令将其升级为新的主服务器,并让其他从服务器重新从属于新主服务器; 当客户端试图连接失效的主服务器时,集群也会向客户端返回新主服务器的地址,使得集群可以使用新主服务器代替失效服务器。客观下线条件只适用于主服务器: 对于任何其他类型的 Redis 实例, Sentinel 在将它们判断为下线前不需要进行协商,直接进行下线。
Redis Sentinel 使用了一个单独的可执行文件 redis-sentinel 位于reids-server同级, 但实际上它只是一个运行在特殊模式下的 Redis 服务器, 可以在启动一个普通 Redis 服务器时通过给定 –sentinel 选项来启动 Redis Sentinel ,下面两种方式均可启用sentinel
redis-sentinel /path/to/sentinel.conf # 指定配置文件位置 # redis-server /path/to/sentinel.conf --sentinel # --sentinel参数指定
sentinel配置文件内容
Redis 源码中包含了一个名为 sentinel.conf 的文件, 这个文件是一个带有详细注释的 Sentinel 配置文件示例。
运行一个 Sentinel 所需的最少配置如下所示:
port 26379 # sentinel的端口号,未指定默认26379 sentinel monitor mymaster 127.0.0.1 6379 2 sentinel down-after-milliseconds mymaster 60000 # sentinel判断下线的毫秒数 sentinel failover-timeout mymaster 180000 # 自动故障转化的最长时间,超过视为失败 sentinel parallel-syncs mymaster 1 # 最多只有1个服务器同时同步新主服务器的数据 sentinel monitor resque 192.168.1.3 6380 4 sentinel down-after-milliseconds resque 10000 sentinel failover-timeout resque 180000 sentinel parallel-syncs resque 5
第一行配置指示 Sentinel 去监视一个名为 mymaster 的主服务器, 这个主服务器的 IP 地址为 127.0.0.1 , 端口号为 6379 , 而将这个主服务器判断为失效至少需要 2 个 Sentinel 同意 ,不过要注意, 无论你设置要多少个 Sentinel 同意去判定一个服务器失效, 一个sentinel都需要获得系统中多数 Sentinel 的支持, 才能发起一次自动故障迁移, 并预留一个给定的配置纪元 (configuration Epoch ,一个配置纪元就是一个新主服务器配置的版本号)。
Redis Cluster
Redis 集群是一个提供在多个Redis间节点间共享数据的程序集, 通过数据分片和主从服务来提供一定程度的可用性。
数据分片
集群将整个数据库分为16384个槽位,使用0-16383表示,所有的key会经过crc16(key)%16384计算,根据得到的结果将该key分配到对应范围的节点上。这样 可以避免单个节点的性能瓶颈。
原理
使用了一个16384/8长度个字节的char保存这个槽,也就是16384位,这是一个bitmap数据结构。例如,假如某节点该char值二进制为11100000,则表示该节点的槽位为6-8。16384个槽位的设计主要为了避免数据节点相互相互通信之间的数据jian'huanhttps://www.cnblogs.com/rjzheng/p/11430592.html
主从节点
为了保证集群的可靠性,集群中每一个节点都有若干个从节点,主节故障时由从节点代替主节点继续提供服务,从节点提供读服务减轻主节点压力,主从节点使用的hash槽位是相同的,并且从节点会实时拷贝主节点数据。
集群中的所有主节点会像sentinal机制一样,如果某个节点故障,其他主节点会从故障节点的从节点中选出新的主节点,继续提供服务。
数据的一致性
redis没有保证数据的强一致性,可能造成写丢失,有两种情况:
- 一个主节点接受写命令后,先向客户端回复命令,再向从节点复制写操作,该过程异步执行。
- 网络分区:主节点接受写操作后无法与其他节点通信,但其他节点网络正常,达到一定时间后其他节点将选举无法通信节点的子节点作为主节点,原主节点的写入请求将永远无法同步。该操作丢失。
配置文件
port 7000 " 该节点端口 cluster-enabled yes " 是否启动集群模式 cluster-config-file nodes.conf " 节点的配置文件,默认nodes.conf,节点启动时候创建,并再有需要时候实时更新 cluster-node-timeout 5000 appendonly yes
部署
开启了7000-7005端口的6个redis实例,使用的时集群模式开启的状态
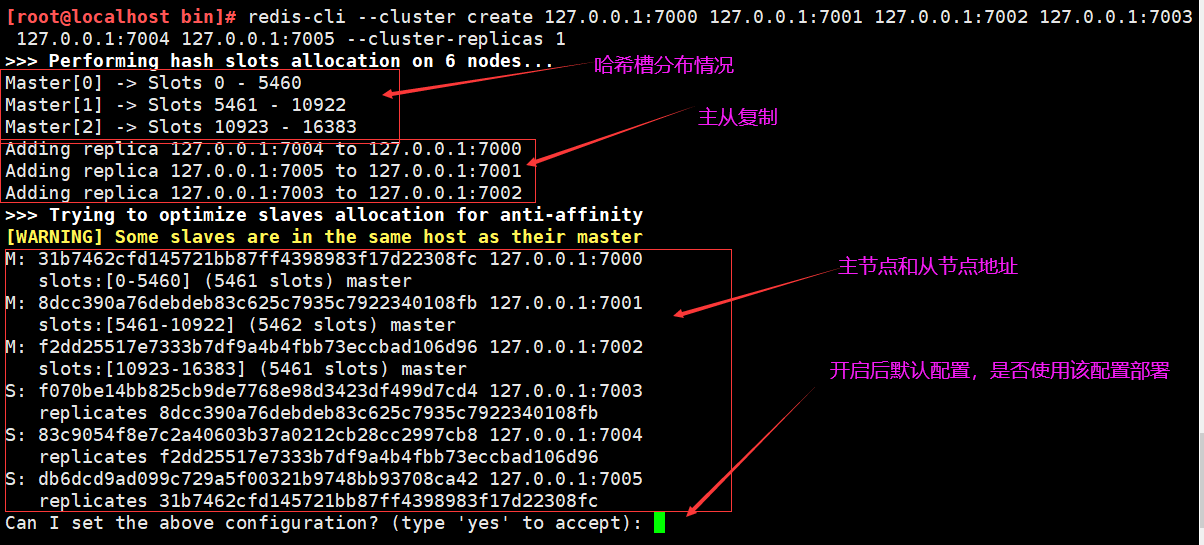
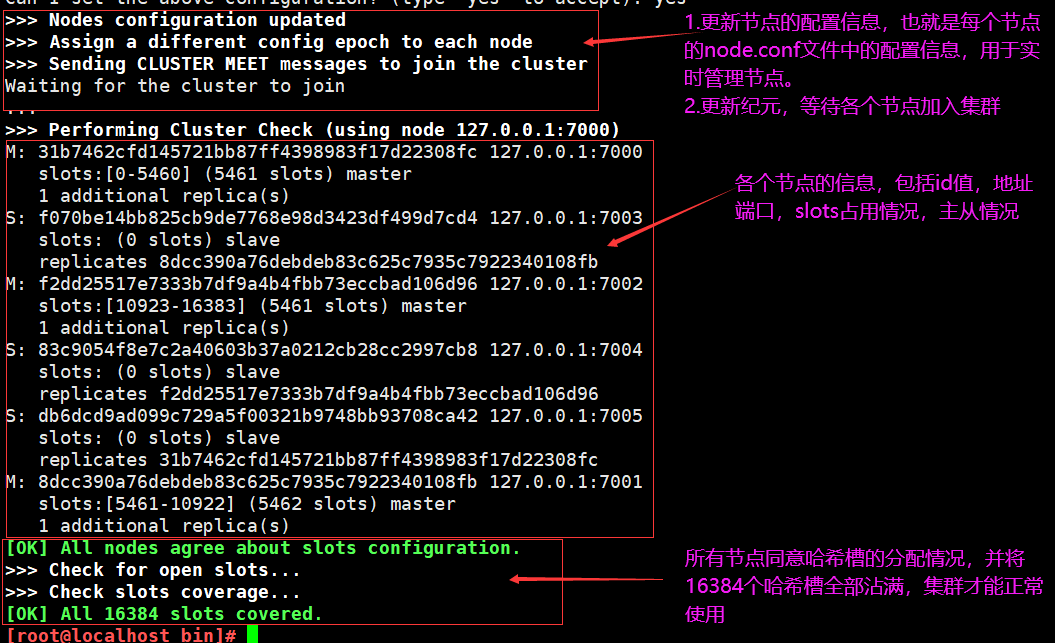
集群创建完毕,可以使用客户端访问任意的节点,如果set和get值slot值不一致,将会返回error moved得错误信息指定 应该访问节点,从而客户端再次访问正确得节点。

为了避免这种转移,应该将这些key得节点位置进行缓存,一次找到对应key值对应得节点。这种缓存只会在集群发节点配置变化的情况下才会变化,例如对节点进行重新分片或者增删了节点。
集群故障转移
主节点发生故障后,同sentinel一样,集群会进行故障转移,将其从节点升级为主节点,保证该节点对应的slot范围可用。但是故障转移可能发生写丢失, 这是由于节点先返回客户端再进行从节点复制造成的,但是由于两个操作间隔极小所以数据丢失的可能性也较小,但是再大量写入并发时候节点故障还是非常有可能造成写丢失。
再客户端中使用CLUSTER NODES,查看该集群的节点信息,如下,
127.0.0.1:7000> CLUSTER NODES f070be14bb825cb9de7768e98d3423df499d7cd4 127.0.0.1:7003@17003 slave 8dcc390a76debdeb83c625c7935c7922340108fb 0 1584519338144 4 connected 31b7462cfd145721bb87ff4398983f17d22308fc 127.0.0.1:7000@17000 myself,master - 0 1584519337000 1 connected 0-5460 f2dd25517e7333b7df9a4b4fbb73eccbad106d96 127.0.0.1:7002@17002 master - 0 1584519339000 3 connected 10923-16383 83c9054f8e7c2a40603b37a0212cb28cc2997cb8 127.0.0.1:7004@17004 slave f2dd25517e7333b7df9a4b4fbb73eccbad106d96 0 1584519339558 5 connected db6dcd9ad099c729a5f00321b9748bb93708ca42 127.0.0.1:7005@17005 slave 31b7462cfd145721bb87ff4398983f17d22308fc 0 1584519338000 6 connected 8dcc390a76debdeb83c625c7935c7922340108fb 127.0.0.1:7001@17001 master - 0 1584519339154 2 connected 5461-10922
注意7002端口信息,下面将7002端口redis服务强制下线,查看集群自动啊故障转移
[root@localhost tests]# redis-cli -p 7002 debug segfault # 发送debug segfault信息下线 再次查看节点信息 127.0.0.1:7000> CLUSTER nodes f070be14bb825cb9de7768e98d3423df499d7cd4 127.0.0.1:7003@17003 slave 8dcc390a76debdeb83c625c7935c7922340108fb 0 1584520172000 4 connected 31b7462cfd145721bb87ff4398983f17d22308fc 127.0.0.1:7000@17000 myself,master - 0 1584520171000 1 connected 0-5460 f2dd25517e7333b7df9a4b4fbb73eccbad106d96 127.0.0.1:7002@17002 master,fail - 1584520095526 1584520093000 3 disconnected 83c9054f8e7c2a40603b37a0212cb28cc2997cb8 127.0.0.1:7004@17004 master - 0 1584520171811 7 connected 10923-16383 db6dcd9ad099c729a5f00321b9748bb93708ca42 127.0.0.1:7005@17005 slave 31b7462cfd145721bb87ff4398983f17d22308fc 0 1584520171509 6 connected 8dcc390a76debdeb83c625c7935c7922340108fb 127.0.0.1:7001@17001 master - 0 1584520172316 2 connected 5461-10922
显示7002端口的redis节点状态为fail,并将7004端口的节点由slave作为了master,现在重启7002节点。并再次查看节点信息
f2dd25517e7333b7df9a4b4fbb73eccbad106d96 127.0.0.1:7002@17002 slave 83c9054f8e7c2a40603b37a0212cb28cc2997cb8 0 1584523225941 7 connected
重启的节点作为了从节点重启,而原来的从作为了主节点。故障转移期间集群的访问不受转移影响。
手动故障转移
Redis集群使用 CLUSTER FAILOVER命令来进行故障转移,不过要在被转移的主节点的从节点上执行该命令 ,手动故障转移比主节点失败自动故障转移更加安全,因为手动故障转移时客户端的切换是在确保新的主节点完全复制了失败的旧的主节点数据的前提下下发生的,所以避免了数据的丢失。
其基本过程如下:客户端不再链接我们淘汰的主节点,同时主节点向从节点发送复制偏移量,从节点得到复制偏移量后故障转移开始,接着通知主节点进行配置切换,当客户端在旧的master上解锁后重新连接到新的主节点上。
添加一个节点
添加一个主节点
- 启动一个实例,集群模式开启
- 使用addnode命令将其与集群中某个节点链接,将其添加到集群之中。
redis-trib.rb add-node 127.0.0.1:7006 127.0.0.1:7000
- 为新节点分配哈希槽数据。
添加一个从节点
- 启动一个实例,集群模式开启
- 使用addnode命令将其与集群中某个节点链接,将其添加到集群之中,指定添加为slave,并主节点id,使其作为其从节点
redis-trib.rb add-node --slave --master-id <master-id> 127.0.0.1:7006 127.0.0.1:7000
改变一个从节点
可以将从属于节点A的从节点改为从属于节点B,使用cluster replicas <node_id>命令,指定新的节点ID即可,
127.0.0.1:7003> cluster replicas 83c9054f8e7c2a40603b37a0212cb28cc2997cb8
移除一个节点
移除一个主节点首先需要确保这个主节点的哈希槽已被分配给其他节点,自身为空,然后执行命令移除即可
redis-trib del-node 127.0.0.1:7000 `<node-id>`
两个参数分别为集群任意节点的地址和这个集群中需要移除的节点id。
从节点迁移
- 丛节点数量较多的主节点将自己的从节点迁移为其他主节点的从节点,避免部分从节点较少的服务访问压力过大,保证系统的可用性和稳定。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号