python爬虫框架——scrapy
scrapy
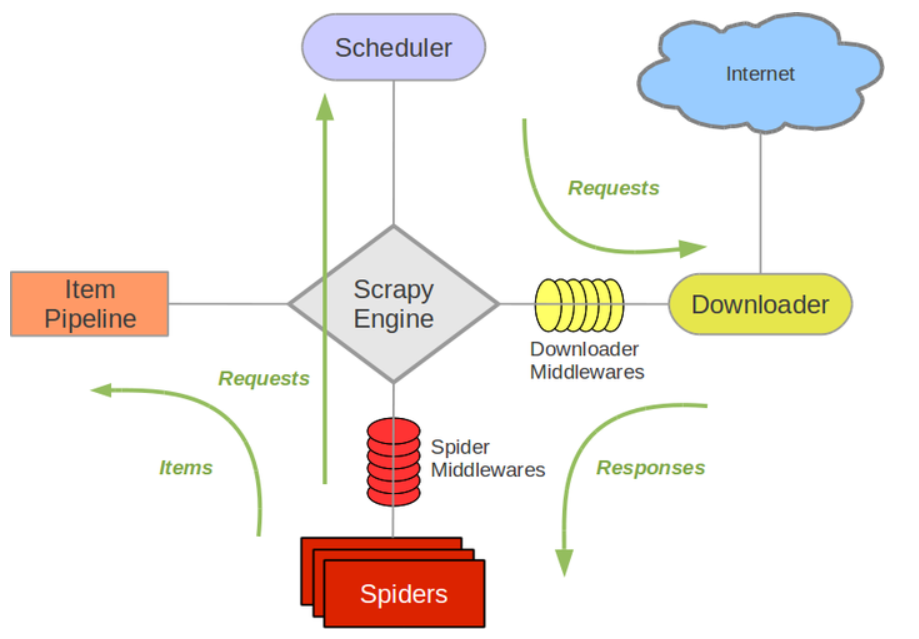
- Scrap Engine(引擎)
负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件,是整个爬虫的调度中心。
- 调度器( Scheduler)
调度器接收从引擎发送过来的 request,并将他们加入到爬取队列,以便之后引擎请求他们时提供给引擎。初始的爬取URL和后续在页面中获取的待爬取的URL将放入调度器中,等待引擎得统一调度爬取。同时调度器会自动去除重复的URL(如果特定的URL不需要去重也可以通过设置实现,如ρost请求的URL)
- 下载器( Downloader)
下载器负责获取页面数据并提供给引擎,而后将获取得response信息提供给 spider。
- Spiders爬虫
Spider是编写的类,作用如下:
- 编写用于分析 response并提取item即获取到的item)
- 分析页面中得url,提交给 Scheduler调度器继续爬取。
由于网站页面内容结构不同,一个spider一般负责处理一个(或一些)特定的网站。多个网站可以使用多个spider分别进行爬取。
- Item pipeline
页面中饿内容被提取出来封装到一个数据结构中,即一个item,每一个item被发送到项目管道( Pipeline),并经过设置好次序的pipeline程序处理这些数据,最后将存入本地文件或存入数据库持久化。
item pipeline的一些典型应用
- 处理HTML数据
- 验证爬取的数据(检查item包含某些字段)
- 查重(或丢弃)
- 将爬取结果保存到数据库中
- 下载器中间件(Downloader middlewares)
下载器中间件是在引擎和下载器之间的特定钩子(specific hook),在下载进行下载前,以及下载完成返回数据的阶段进行拦截,处理请求和响应。它提供了一个简便的机制,通过插入自定义代码来扩展 Scrapy功能,通过设置下载器中间件可以实现爬虫自动更换 user-agent、实现IP代理功能等功能。
- Spider中间件( Spider middlewares)
Spider中间件,是在引擎和 Spider之间的特定钩子,处理 spider的输入response和输出(items或 requests)
安装
scrapy使用Twisted基于事件的高效异步网络框架来处理网络通信,可以加快下载速度,使用pip安装scrapy时会自动解决安装依赖,在windows下如果安装Twisted出现问题,手动下载编译好的Twisted包安装即可。
- 安装wheel支持:pip install wheel
- 安装scrapy框架:pip install scrapy
基本使用
创建项目
scrapy提供了命令快速的创建一个项目,自动生成项目框架
scrapy startproject <pro_name> . # 在当前目录创建项目
创建后项目目录如下:
pro_name/ # 项目目录 scrapy.cfg # 必要的配置文件 pro_name/ # 项目全局目录 spiders/ # 爬虫类 __init__.py __init__.py items.py # item,定义数据结构储存数据 middlewares.py # 中间键类 pipelines.py # 管道 setting.py # 全局重要的设置 setting中的设置 BOT_NAME = 'spider_name' # 爬虫名 SPIDER_MODULES = ['pro_name.spiders'] # 爬虫模块 USER_AGENT # UA,配置 ROBOTSTXT_OBEY = False # 是否遵从robots协议 # CONCURRENT_REQUESTS = 32 # 最大请求数,默认16 # COOKIES_ENABLED = False # 一般登录时候使用cookie # DEFAULT_REQUEST_HEADERS = { # 可定义请求头 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', } # 两个中间件,指定为模块中的类,将会自动按照优先级依次调用 # SPIDER_MIDDLEWARES = { # 中间键类们,key为模块位置,value为优先级,越小越优先 'pro_name.middlewares.Pro_nameSpiderMiddleware': 543, } # DOWNLOADER_MIDDLEWARES = { 'pro_name.middlewares.Pro_nameDownloaderMiddleware': 543, } ITEM_PIPELINES = { # 管道处理,指定处理类,按照顺序调用 'wuhan.pipelines.PeoplePipeline': 300, }
Item
item可以看作是一个储存数据的数据结构, 定义我们需要爬取内容的数据字段用于储存数据并将每一条数据封装为一个Item对象,再由scrapy核心交由pipelines依次处理即可。假如我们需要爬取的每一条招聘内容,包含了公司名,工作地点,薪资等字段数据,我们可以定义一个数据结构Item去储存这些数据
import scrapy class workItem(scrapy.Item): cp_name = scrapy.Field() # class scrapy.Field(dict): 继承于dict cp_addr = scrapy.Field() salary = scrapy.Field()
该类继承scrapy中的内部类,定义的属性值为一个scrapy.Field()实例,实际为一个字典对象。
爬虫类
爬虫类中分为两部分工作,提供想要爬取的url和解析返回的response信息。scrapy提供了模块快速的创建一个模板。scrapy genspider -t basic name domain.com -t指定模板的类型为basic,name为创建的py文件名,执行后将会在spider目录中生成文件name.py文件,文件内容如下。
# -*- coding: utf-8 -*- import scrapy class DomainSpider(scrapy.Spider): name = 'spider_name' # 爬虫名 allowed_domains = ['domain.com'] # 爬 取的内容必须在这些域下,否则爬取 start_urls = ['http://domain.com/'] # 起始的url # 下载器下载了目标页面的内容,封装为response对象并注入到response参数中, def parse(self, response): # 返回的response值,类型为scrapy.http.response.html.HtmlResponse pass # 使用参数注解方便了解该对象的方法
parse方法中负责对response中的内容进行数据处理,一般包括数据数据提取和url提取,数据使用Item进行封装,url继续交由调度器进行再次继续进行访问。
解析response
返回的数据被scrapy封装为一个HtmlResponse对象,他是一个response对象的一个子类。
def parse(self, response): print(response.text, response.body, response.headers) # 文本内容和头信息
为了方便页面内容的提取,scrapy包装了lxml,并可以通过调用response的方法直接调用,并通过xpath语法进行提取。直接调用xpath方法即可
def parse(self, response): tag = response.xpath("//xpath") # tag为提取html的标签封装的xpath对象,可以继续调用xpath
同样还支持css选择器,调用css方法即可
def parse(self, response): css_tag = respons.css("li a::text")
Item封装数据
from ..items import WorkItem # 使用相对导入 def parse(self, response): # 使用xpath 或者 css选择器提取到了内容 cp_name = response.xpath("//cp_name").extract() cp_addr = response.xpath("//cp_addr").extract() salary = response.xpath("//salary").extract() # 实例化item对象 item = WorkItem item["cp_name"] = cp_name # 将数据对应封装到item对象属性中。 item["cp_addr"] = cp_addr item["salary"] = salary return [item] # return值将会交给pipeline处理,需要一个可迭代对象 # yield item # 或者使用yield每次返回一个item,返回一个可迭代对象即可 # 该数据也可以通过命令直接保存到指定的文件中 # 命令行执行 scrapy crwal -h 查看帮助 # --output 或者 -o "path/to/" 存入指定的文件 # 例如 scrapy crawl -o "tmp/data/work.json" # 支持的文件格(json,csv, xml, marshal, pickle)
pipeline
每一个pipeline会依次处理返回的每一个item数据,多个pipeline同时存在可以设置优先级。使用pipeline只需要将对应pipeline类在setting列表中注册并指定优先级即可,scrapy将会依次调用这些pipeline工作。
在项目文件中有pipeline.py文件,在内部可根据需要定义pipeline。定义完成必须在setting.py的pipelines列表中声明即可。
- 开启并添加pipeline
ITEM_PIPELINES = {'pro_name.pipelines.TestPipeline':500} # 指定这个pipeline的模块位置进行注册
- 自定义pipeline
每一个pipeline类可以定以下方法,如果指定,scrapy将在对应的时刻调用这些方法执行啊。
class AaaPipeline(object): def __init__(self): # pipeline创建时候调用一次 print("init +++++++++++++++") def open_spider(self, spider): print("open_spider ++++++++++++++++++") # spider开启时调用一次 print(spider, type(spider)) # 该spider对象即为spider文件中的DomainSpider对象 return "open ====" def process_item(self, item, spider): # 必须定义该方法 # 处理一条条item的方法 # spider类中的parse方法每返回一条item数据,该方法调用一次。 print(item) print(spider, type(spider)) return item def close_spider(self, spider): # spider关闭时候调用 print("close_spider ++++++++++++++++++") print(spider, type(spider)) return "close ===="
process_item方法负责对每个item对象进行处理,可以将数据保存存到磁盘或者数据库中,open_spider和close_spider方法通常用于创建和关闭数据库连接或者文件对象等操作。
url提取
我们需要从页面中提取下一页的url,再次进行爬取,在之前的parse函数中完成这个任务。
import scrapy class Spider(scrapy.Spider): name = "domain" start_utl = "" allowed_domain = [] def parse(self, response): urls = response.xpath("//div[@class='paginator']/span[@class='next']/a/@href") .re(r'start=/d+') # 匹配url使用正则过滤 # 将每个url拼接为为全路径,并封装为Request对象返回 yield from (scrapy.Request(response.urljoin(url)) for url in urls)
提取的url只需要将其封装为scrapy.Request对象进行返回,scrapy将会将其作为请求交给调度器,并由下载器再次发送请求。调度器对url自动有去重功能,重复的url提交给调度器,将会自动去重。
多页面定向爬取
如果该网站有多个网页需要进行爬取,但是页面的内容结构差异较大,这样一个parse函数将不能够很好的解析统一的解析。我们需要对页面进行分类。通过url的差异,使得不同类的内容执行不同解析parse函数,各自完成解析。
实现这个功能,scrapy提供了另一个模板-crawl,如同basic模板的创建方式
scrapy genspider -t crawl name domian.com进行创建,创建后内容如下:
import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule class $classname(CrawlSpider): # CrawlSpider是Spider的子类 name = '$name' allowed_domains = ['$domain'] start_urls = ['http://$domain/'] # 定义了一个规则,从response页面中提取指定的链接,链接可以匹配allow="Items/",将会爬取链接页面执行会执行callback函数 # rules = ( Rule(LinkExtractor(allow=r'Items/',), callback='parse_item', follow=True), 。。。 ) def parse_item(self, response): item = {} #item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get() #item['name'] = response.xpath('//div[@id="name"]').get() #item['description'] = response.xpath('//div[@id="description"]').get() return item
scrapy.spider.crawl.CrawlSpider是scrapy.spider.Spider的子类,增强了功能,在其中可以使用LinkExtractor,Rule
Rule的规则
- rules元组中可以定义多条规则,每一条规则映射一个callback用于处理
- LinkExtractor对象用于过滤url,其中参数包括:
- allow参数传入一个正则字符串或者多个正则字符串组成可迭代对象,该正则字符串只会匹配页面的中的
<a>中的href属性的值。将会提取页面中所有的href进行匹配。 - deny:于allow相反,匹配的拒绝访问
- allow_domain:允许域
- deny_domain:拒绝域
- follow:是否继续跟进链接。
爬取执行过程
执行爬虫开始爬取过程,从打印的日志中可以看到相关的信息。scrapy list 可以列出当前存在的爬虫名,使用scrapy crwal spider_name开始爬取
c:\\users\username\python\aaa> scrapy crawl spider_name # 执行命令,开始scrapy进行爬取 2020-03-31 11:31:32 [scrapy.utils.log] INFO: Scrapy 1.8.0 started (bot: aaa) # 加载的库 2020-03-31 11:31:32 [scrapy.utils.log] INFO: Versions: lxml 4.4.2.0, libxml2 2.9.5, csssel ect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 19.10.0, Python 3.6.6 (v3.6.6:4cf1f54eb7, J un 27 2018, 03:37:03) [MSC v.1900 64 bit (AMD64)], pyOpenSSL 19.1.0 (OpenSSL 1.1.1d 10 Se p 2019), cryptography 2.8, Platform Windows-10-10.0.18362-SP0 # 爬虫的初始化配置值,例如user_agent信息。 2020-03-31 11:31:32 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'aaa', 'NEWSP IDER_MODULE': 'aaa.spiders', 'SPIDER_MODULES': ['aaa.spiders'], 'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safar i/537.36'} 2020-03-31 11:31:32 [scrapy.extensions.telnet] INFO: Telnet Password: 8e9ba500a3d20796 # 中间件信息,这里没有使用,加载了默认的几个中间件 2020-03-31 11:31:32 [scrapy.middleware] INFO: Enabled extensions: ['scrapy.extensions.corestats.CoreStats', 'scrapy.extensions.telnet.TelnetConsole', 'scrapy.extensions.logstats.LogStats'] # 下载器中间件downloadermiddlewares信息 2020-03-31 11:31:32 [scrapy.middleware] INFO: Enabled downloader middlewares: ['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware', 'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware', 'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware', 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware', 'scrapy.downloadermiddlewares.retry.RetryMiddleware', 'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware', 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware', 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware', 'scrapy.downloadermiddlewares.cookies.CookiesMiddleware', 'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware', 'scrapy.downloadermiddlewares.stats.DownloaderStats'] # spidermiddlewares 2020-03-31 11:31:32 [scrapy.middleware] INFO: Enabled spider middlewares: ['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware', 'scrapy.spidermiddlewares.offsite.OffsiteMiddleware', 'scrapy.spidermiddlewares.referer.RefererMiddleware', 'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware', 'scrapy.spidermiddlewares.depth.DepthMiddleware'] # 至此,配置信息和中间件信息加载完毕,开始执行爬取内容 # pipeline 初始化,执行了__init__方法,这是我们自己打印的内容 init +++++++++++++++ 2020-03-31 11:31:32 [scrapy.middleware] INFO: Enabled item pipelines: ['aaa.pipelines.AaaPipeline'] # pipeline中open_spider方法执行,spider对象已被创建,即parse方法所属spider类 2020-03-31 11:31:32 [scrapy.core.engine] INFO: Spider opened open_spider ++++++++++++++++++ <TestspiserSpider 'testspider' at 0x1e9d2784198> <class 'aaa.spiders.testspiser.Testspiser Spider'> 2020-03-31 11:31:32 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), s craped 0 items (at 0 items/min) 2020-03-31 11:31:32 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1 :6023 2020-03-31 11:31:32 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <G ET http://www.douban.com/> from <GET http://douban.com/> 2020-03-31 11:31:32 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <G ET https://www.douban.com/> from <GET http://www.douban.com/> 2020-03-31 11:31:33 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.douban.com/ > (referer: None) # parse解析方法执行 200 ================== # process_item方法执行。 {'age': 123, 'name': 'abc'} <TestspiserSpider 'testspider' at 0x1e9d2784198> <class 'aaa.spiders.testspiser.Testspiser Spider'> 2020-03-31 11:31:33 [scrapy.core.scraper] DEBUG: Scraped from <200 https://www.douban.com/ > {'age': 123, 'name': 'abc'} # 关闭爬虫,执行pipeline中的close_spider方法 2020-03-31 11:31:33 [scrapy.core.engine] INFO: Closing spider (finished) close_spider ++++++++++++++++++ <TestspiserSpider 'testspider' at 0x1e9d2784198> <class 'aaa.spiders.testspiser.Testspiser Spider'> # 本次爬取的执行总结信息 2020-03-31 11:31:33 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 860, 'downloader/request_count': 3, 'downloader/request_method_count/GET': 3, 'downloader/response_bytes': 19218, 'downloader/response_count': 3, 'downloader/response_status_count/200': 1, 'downloader/response_status_count/301': 2, 'elapsed_time_seconds': 0.727021, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2020, 3, 31, 3, 31, 33, 388677), 'item_scraped_count': 1, 'log_count/DEBUG': 4, 'log_count/INFO': 10, 'response_received_count': 1, 'scheduler/dequeued': 3, 'scheduler/dequeued/memory': 3, 'scheduler/enqueued': 3, 'scheduler/enqueued/memory': 3, 'start_time': datetime.datetime(2020, 3, 31, 3, 31, 32, 661656)} 2020-03-31 11:31:33 [scrapy.core.engine] INFO: Spider closed (finished)
middleware
从文章开头的scrapy建构图中可以看到,scrapy提供了两个中间件,分别是SpiderMiddleware和DownloaderMiddleware,在setting.py文件中,也有对应的中间件变量
SPIDER_MIDDLEWARES = { 'name.middlewares.NameSpiderMiddleware': 543, } DOWNLOADER_MIDDLEWARES = { 'name.middlewares.NameDownloaderMiddleware': 543, }
以上配置文件中的中间件是我们自定义中间件,但是通过上面的日志文件可以看到还加载许多内置的中间件,这些中间件在固定的被加载,并按照设置的优先级顺序依次调用。中间件的作用主要是为框架提供可扩展性,让用户能够更好的根据自身需求在程序适当的位置添加处理程序。
如何添加自己的中间件
在scrapy生成的框架中,可以找到一个middleware.py文件,内部定义了两个类,并有部分初始信息,但未实现任何功能 :
# SpiderMiddleware class AaaSpiderMiddleware(object): # 不是所有的方法必须定义,如果没有定义将跳过执行 @classmethod def from_crawler(cls, crawler): # 创建spider时调用该方法 s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s def process_spider_input(self, response, spider): # 数据流入spider模块时调用,也就是下载的response信息流入spider,在经过parse函数解析前 # 返回值应为None或者报错 return None def process_spider_output(self, response, result, spider): # 从spider输出的数据将经过该方法的处理,包括两个操作。 # - 向item pipeline中注入数据时 # - 向scheduler提交的新的请求对象时 # 必须返回一个可迭代对象,字典,或者Item对象。 for i in result: yield i def process_spider_exception(self, response, exception, spider): # 当spider或者process_spider_input方法出现了异常时调用 # 返回None或者 an iterable of Request, dict or Item objects. pass def process_start_requests(self, start_requests, spider): # 第一次对入口url发起请求时会调用该方法。 for r in start_requests: yield r def spider_opened(self, spider): spider.logger.info('Spider opened: %s' % spider.name) # 打印的日志信息 # DownloaderMiddleware class AaaDownloaderMiddleware(object): # 从架构图中的位置可以看出DownloaderMiddleware的只能处理两个数据流, # Request请求和Response响应,分别对应了两个方法,process_request和process_response @classmethod def from_crawler(cls, crawler): s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s def process_request(self, request: scrapy.http.request.Request, spider): # 返回值必须为:None 或者 Response对象或者Request对象。 # 或者抛出IgnoreRequest错误,再由process_exception处理 return None def process_response(self, request, response, spider): # 返回值同上 return response def process_exception(self, request, exception, spider): # 处理上面两个方法的错误 # 返回值: # - return None: 继续释放错误 # - return Response对象或者Request对象: 压制错误 pass def spider_opened(self, spider): spider.logger.info('Spider opened: %s' % spider.name)
这两个中间件是scrapy提供的模板,自定义中间件只需要按照上面模板定义一个类,指定对应的方法即可。如果有多个中间件可以进行分别定义,每个完成各自的功能。最后在setting.py中的中间件列表中添加该类(需要从根目录开始执行模块位置),并指定该类优先级值即可,值越大,优先级越低。
添加代理
如果使用同一个ip地址快速进行爬取,容易被服务端的反爬虫机制检测到,该ip地址将会短暂的,将导致无法访问该网站。为了避免非人类的快速操作,我们可以将setting文件中的DOWNLOAD_DELAY = 3设置为一个合适的值,每次爬取后,将会间隔指定时间再次爬取内容,将会降低被封ip的风险,但是这样会严重影响爬取速度。更好的办法就是使用ip代理的方式。
ip代理是通过中间的代理服务器A访问目标网站,再由服务器A将信息发送给我们,服务器A长时间快速访问任然会导致A的IP地址被禁用,这就需要一个含有大量ip的代理池,每次随机选取进行访问,然后将所有的数据集中到我们自己的机器上。由于使用的ip众多,这样单个ip连续出现频率将会降低,不会被认定为是爬虫的操作。这样就可以在短暂的时间内大量的爬取数据而不被发现。ip代理也是常用的反反爬手段之一。
添加代理一般我们使用单独的一个middleware
class ProxyDownloaderMiddleware: proxies = [ "http://120.83.105.247:9999", ] def process_request(self, request, spider): if self.proxies: request.meta["proxy"] = random.choices(self.proxies) print(request.url, request.meta["proxy"], "===================================")
代理是在发送Request之前更换代理信息,所以在process_request方法中提前在request.meta属性中添加proxy的值,实现代理功能。
最后在setting.py中启用这个中间件模块,使其能够被调用实现代理功能。
数据存入MongoDB
我们最终提取到数据将会分装到一个个Item中,交给pipeline依次处理,例如可以将数据存入MongoDB数据库中来保存这些数据。
将数据存入MongoDB中,需要提供对应pipeline处理来自spider封装好的item信息,我们可以将写入mongo的操作看作一个独立的功能,使用单独一个pipeline完成。并且通过提供不同的MongoDB连接参数,包括服务主机地址,端口,库名等信息,来方便连接不同mongo服务。为了方便的配置这些信息,可以将这些数据写入配置文件中setting.py中,以方便对其进行修改,配置文件中的内容将会绑定到该项目中所有的spider中,如果有多个spider需要保存到同一个mongo服务中,可以配置到setting.py中配置保障配置信息共享。如果是spider独有的,可以单独在该spider类中定义这些属性,spider会优先读取类中定义的属性,如果没有,再去配置文件中查找。
import pymongo from pymongo.collection import Collection class ReviewsPipeline(object): # 创建spider时创建该mongo客户端,该方法只会在项目启动时执行一次 def open_spider(self, spider): # 从settting读取配置信息,如果spider有settings属性,将优先读取自己的settings属性 # 而不是全局配置中settings属性。 mongo_host = spider.settings.get("MONGO_HOST", "localhost") mongo_port = spider.settings.get("MONGO_PORT", 27017) mongo_collection = spider.settings.get("MONGO_COLLECTION", "default-col") db_name = spider.settings.get("MONGO_DB", "default-db") try: self.client = pymongo.MongoClient(host=mongo_host, port=mongo_port) self.collection:Collection = self.client[mongo_collection] self.db = self.collection[db_name] except Exception as e: print("connect mongodb error: ", e) raise def process_item(self, item, spider): try: self.db.insert_one(dict(item)) except Exception as e: logging.error(e) # 插入数据失败记录日志信息 return item def close_spider(self, spider): # 关闭 self.client.close()
同样的,需要使用该pipeline,需要在setting文件的PIPELINES中添加该pipeline并指定优先级信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号