python爬虫 --- urllib
urllib包
urllib是python3中的一个标准库,它是一个工具包模块,使用该模块我们可以模仿浏览器向服务器发送请求,并获得返回结果数据进行处理。
urllib包分级简单,在该包下5个模块
- urllib.request :用于打开和读写url
- urllib.response:将获取后的内容进行封装为一个类文件对象,方便使用
- urllib.error包含了由 urllibreques引起的异常
- urllib.parse用于解析url
- urllib.robotparser分析 robots. txt文件
Python2中提供了urlb和urlib2两个库,urllib提供较为底层的接口, urllib2对 urllib进行了进一步封装。
Python3中将urllib2合并到了urllib中,并更名为标准库urllib包。
urllib. request模块
模块定义了在 基本和摘要式身份验证、重定向、cookies等应用中打开url(主要是HTTP)的函数和类。通过这些内置的函数和类去完成请求消息的构建和发送请求。
urlopen函数
该函数用于访问指定的url, 并得到response结果。
import urllib from http.client import HttpResponse url = "" res: HttpResponse = urllib.request.urlopen(url, data=None, timeout=socket._GLOBAL_DEFAULT_TIMEOUT) with res: with res: print(res, type(res)) print(res.getcode(), # 获取状态码 res.reason, # OK, 状态码说明 res.geturl(), # 访问的真实的url,发生了重定向。 res.headers, # 头信息 res.info(), res.read(), # Httresponse对象使用socket.makefile方法构建为一个类文件对象 sep="\n") # 可以使用文件对象的几乎所有方法
data如果不指定,使用get方法进行请求,指定后使用会使用post方法请求,并携带data中的数据进行发送,还可以设置访问超时时间,ca安全文件等信息。但是直接通过urlopen的参数无法自定义头信息内容,例如指定请求的方法和user-agent信息,这就需要我们自定义的Requset对象。
Request请求类
Request类,对提供的简单url请求信息进行封装,构建请求头等信息,实例化后获得一个请求对象,并可以为该对象添加请求头信息等内容。如果直接使用urlopen 对一个url进行请求,实际上会先将请求内容(指定的url)封装为一个Request对象,添加一些必要的头信息后在进行请求,以保证服务器接受该请求。
urlopen方法的url参数可以是一个url字符串,也可以是一个Request对象。通过Request类我们自己构建请求对象,并设置该请求对象的头信息,包括user-agent等信息。
Request初始化方法如下:
class Request: def __init__(self, url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None): # url # data: 携带的数据,get方法携带的查询字符串或post方法提交的数据。 # header: 头信息,为一个字典 # method: 指定请求的方法
from urllib.request import Request headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64)"} req = Request(url, headers=headers, method="get") # req.add_header("user-Agent", ""Mozilla/5.0 (Windows NT 10.0; WOW64)") 也可调用该方法添加 res = urlopen(req, timeout=10) # 使用请求对象进行请求,得到response对象
Handler的使用
在request模块中,还有一个重要的角色,就是各种handler, 在该模块中定义了10多种handler类型,分别实现不同的功能,默认情况下,程序会自动加载某些handler去做日常的处理,如果需要更多功能实现,可以为程序添加handler。
urlopen函数
urlopen是常用的请求函数,源码核心逻辑如下
opener = None def urlopen(url, data=None, timeout=socket._GLOBAL_DEFAULT_TIMEOUT, *, cafile=None, capath=None, cadefault=False, context=None): global _opener if cafile or capath or cadefault: # 省略若干........ opener = build_oNonepener(https_handler) elif context: https_handler = HTTPSHandler(context=context) opener = build_opener(https_handler) elif _opener is None: _opener = opener = build_opener() else: opener = _opener return opener.open(url, data, timeout)
经过各种的参数判断,最终都选择使用了build_opener函数去创建一个opener对象,返回值是其open方法的返回值,也就是将来的response。创建opener是发送请求前的准备工作。
opener对象
继续跟踪open方法
def open(self, fullurl, data=None, timeout=socket._GLOBAL_DEFAULT_TIMEOUT): # 如果url是字符串,构建一个Request对象,是Request对象则直接使用 if isinstance(fullurl, str): req = Request(fullurl, data) else: req = fullurl if data is not None: req.data = data req.timeout = timeout protocol = req.type # pre-process request meth_name = protocol+"_request" for processor in self.process_request.get(protocol, []): meth = getattr(processor, meth_name) req = meth(req) # 这里我们看到response,这个函数发送了请求并得到了返回的数据,最后经过封装将response进行返回 response = self._open(req, data) # 这里我们看到response,这个函数真正的发送了请求得到了服务 # post-process response meth_name = protocol+"_response" for processor in self.process_response.get(protocol, []): meth = getattr(processor, meth_name) response = meth(req, response) return response
opener对象的open方法发送了该请求,并得到了response返回。如果继续跟踪获取返回值的opener的_open方法,可以看到内部开始调用注册到这个opener上的handler,然后根据每个handle设置的优先级先后调用。
urlopen函数实际是调用opener对象的方法进行请求, opener对象通过build_opener函数创建。
def build_opener(*handlers): # 实例化opener对象,准备为其添加handler并返回 opener = OpenerDirector() # 默认的handler,可以通过函数的参数添加新的handler, default_classes = [ProxyHandler, UnknownHandler, HTTPHandler, HTTPDefaultErrorHandler, HTTPRedirectHandler, FTPHandler, FileHandler, HTTPErrorProcessor, DataHandler] if hasattr(http.client, "HTTPSConnection"): default_classes.append(HTTPSHandler) skip = set() # 遍历默认handles和函数参数中提供的handles,如果我们提供handler类型和默认列表中handler的子类 # 或实例对象,则将默认列表中的handler剔除。使用我们提供的handler。 for klass in default_classes: for check in handlers: if isinstance(check, type): if issubclass(check, klass): skip.add(klass) elif isinstance(check, klass): skip.add(klass) for klass in skip: default_classes.remove(klass) # 从默认列表中剔除 # 遍历剔除后default_classes和给定的handler,使用opener.add_handler方法将其添加到opener对象中 for klass in default_classes: opener.add_handler(klass()) for h in handlers: if isinstance(h, type): # 如果是类,实例化一个handler对象添加 h = h() opener.add_handler(h) return openerdef build_opener(*handlers): # 实例化opener对象,准备为其添加handler并返回 opener = OpenerDirector() # 默认的handler,可以通过函数的参数添加新的handler, default_classes = [ProxyHandler, UnknownHandler, HTTPHandler, HTTPDefaultErrorHandler, HTTPRedirectHandler, FTPHandler, FileHandler, HTTPErrorProcessor, DataHandler] if hasattr(http.client, "HTTPSConnection"): default_classes.append(HTTPSHandler) skip = set() # 遍历默认handles和函数参数中提供的handles,如果我们提供handler类型和默认列表中handler的子类 # 或实例对象,则将默认列表中的handler剔除。使用我们提供的handler。 for klass in default_classes: for check in handlers: if isinstance(check, type): if issubclass(check, klass): skip.add(klass) elif isinstance(check, klass): skip.add(klass) for klass in skip: default_classes.remove(klass) # 从默认列表中剔除 # 遍历剔除后default_classes和给定的handler,使用opener.add_handler方法将其添加到opener对象中 for klass in default_classes: opener.add_handler(klass()) for h in handlers: if isinstance(h, type): # 如果是类,实例化一个handler对象添加 h = h() opener.add_handler(h) return opener
handler
通过阅读源码,我们可以使用build_opner(handler) 传入自己的handler去构建opener,那么如何去构建一个自己handler。
urllib 定义了近20个handler类,每个handler分别实现自己的功能,而只需要将这个需要的handler添加到opener中即可。这些内置的handler基本可以满足我们的日常需求。在urllib.request模块中定义了这些handler。
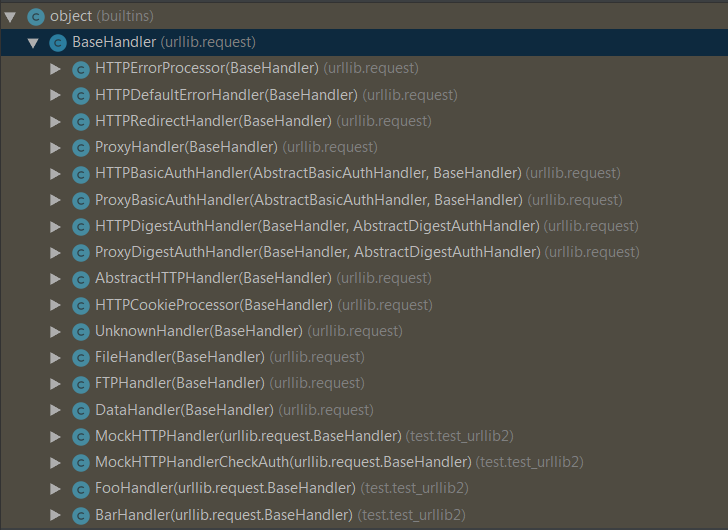
proxy代理
代理是指在访问某一个站点时候,自己不直接访问,而是通过一个中间人代理去访问,代理得到结果后再把结果给我们,这样我们自己的ip地址就不会暴露给该站点,这也是常用的反反爬措施。urllib中使用Proxyhandler去实现代理。我们只需要创建一个ProxyHandler对象。
from urllib import request url = "http://www.baidu.com" proxy_handler = request.ProxyHandler( {'http': 'http://120.78.236.100:8080'} # 配置好的代理ip地址 ) opener = request.build_opener(proxy_handler) response = opener.open(url)
ProxyHandler的实例化参数要求必须为字典,key为指定的协议,value为完整的地址。同样的,如果已经有opener对象,想为其添加handler可以使用opener的add_handler方法
opener = build_opener() # 先创建在添加 opener.add_handler(proxy_handler)
handler的优先级
优先级直接决定了opener上的这些handler的调用顺序,在handler类的类属性上指定了其优先级值handler_order,ProxyHandler通常经量靠前,所以其默认值为100, 而用于错误处理HTTPErrorProcessor优先级总是位于最后默认为1000。实现这个handler实例的优先级大小排序,只需要实现一个大小比较的方法即可。源码:
class BaseHandler: handler_order = 500 def __lt__(self, other): if not hasattr(other, "handler_order"): # Try to preserve the old behavior of having custom classes # inserted after default ones (works only for custom user # classes which are not aware of handler_order). return True return self.handler_order < other.handler_order
在基类上实现了__lt__方法,handler实例的大小比较将会调用该方法,从而通过handler_order的值来进行判断。所以可以有 ProxyHandler() < HTTPErrorProcessor()成立(__lt__只对实例生效,而不是ProxyHandler <HTTPErrorProcessor)。如果我们需要进行优先级调整,只需要Hander.handler_order指定为合适的值即可。
urllib.parse模块
该模块主要进行url的解析问题,例如拼接url和对url进行编码
urlencode
def urlencode(query,doseq=False, safe='',encoding=None, errors=None,quote_via=quote_plus)
urlencode方法用于解决url的编码问题,解码则使用unquote方法,url进行发送前都会进行编码。主要是因为url中的查询字符串以k1=v1&k2=v2的形式发送时候,k和v中包含有特殊的元字符=或者&,导致接受方将字符串分解错误,所以编码以解决字符冲突问题,同时还解决了多字节字符和元字符冲突,例如中文。
host = "http://www.baidu.com/" query_str = parse.urlencode({"tag": "中国"}) en_url = host + "?" + query_str print(en_url) # http://www.baidu.com/?tag=%E4%B8%AD%E5%9B%BD 编码 print(parse.unquote(en_url)) # http://www.baidu.com/?tag=中国 解码
上面直接拼接目标字符串后访问该url,也可以通过urlopen的data参数自动进行拼接,但是拼接前同样需要将数据进行编码。
上面的方式通常是使用get方法以查询字符串的方式提交数据,编码后的数据包含在url中。如果使用post方法提交,提交的数据 content-type : application/x-www-form-urlencoded,同样需要编码再作为消息体传输。
res = urlopen(url, data=parse.enconde("tag":"中国").encode()) # data将会被编码为tag=%E4%B8%AD%E5%9B%BD,由于制定了data,将会以post方法提交数据,data数据在请求体中
urljoin
两个url拼接时候如果连续出现host的内容,以后面的url为主,前面所有内容将会被覆盖。即遇到新的host重新计算。否则直接进行普通的url拼接即可。allow_fragments参数表示是否拼接锚点的内容
# urllib.parse.urljoin(base, url, allow_fragments=True) form urllib.parse import urljoin print(urljoin('http://www.baidu.com', 'abc.html')) print(urljoin('http://www.baidu.com', 'https://bing.cn/abc.html')) # http://www.baidu.com/abc.html # https://pythonsite.com/FAQ.html
urlparse和urlunparse
根据一个url的组成规则,scheme://username:password@host/path?query#fragment, urlparse函数会将这些内容进行切分,返回一个切分后的结果对象
def urlparse(url, scheme='', allow_fragments=True) # 示例 print(urlparse("https://www.baidu.com/search?tag='中国'#comment")) # 结果,按照各部分进行切分。 # ParseResult(scheme='https', netloc='www.baidu.com', path='/search', params='', query="tag='中国'", fragment='comment')
urlunparse的作用则是按照此方式拼接。
忽略CA认证
当我们使用https协议去访问网站时,数据传输是经过加密,这样可可以防止数据再传输的过程中(包括服务器或者客户端)被他人窃取,篡改信息,而加密则使用ssl协议完成,即https = http + ssl。关于CA证书详细的书名介绍参照https://www.cnblogs.com/handsomeBoys/p/6556336.html。
https连接过程
- 客户端发送请求到服务器端
- 服务器端返回证书和公开密钥,公开密钥作为证书的一部分而存在
- 客户端验证证书和公开密钥的有效性,如果有效,则生成共享密钥并使用公开密钥加密发送到服务器端
- 服务器端使用私有密钥解密数据,并使用收到的共享密钥加密数据,发送到客户端
- 客户端使用共享密钥解密数据
- SSL加密建立………
由于https使用中间机构去保证该证书的安全性。则该证书颁发机构必须得到服务端和客户端同时认可,如果客户端不信任该机构的颁发的证书,将会拒绝进行数据的加密CA认证。在某些安全性要求不高的情况下我们可以忽略CA认证信息,即使没有被客户端接受任然进行数据通信,urllib包中的函数提供了该功能。
假如我们访问一个非权威CA机构认证的网站,客户端的ssl协议会默认拒绝该CA机构的认证文件。
import urllib url = "https://www.12306.cn/mormhweb/" # 使用了https,就需要CA认证,但是客户端不认可该CA机构 res = urllib.request.urlopen(url) with res: printt(res.read()) # ssl.CertificateError:hostname 'www.12306.cn' don't match either of ...
上面程序将会报ssl.CertificateError,即由于客户端的拒绝而认证失败。忽略CA认证可使用以下方法。
import urllib import ssl # 导入ssl context = ssl._create_unverified_context() # 创建忽略不信任的证书的信息 url = "https://www.12306.cn/mormhweb/" res = urllib.request.urlopen(url, context=context) # 访问时携带该信息,证书返回后将会忽略,可以正常访问 with res: printt(res.read())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号