编译器:TPU-MLIR环境构建及使用指南(一)
编译器:TPU-MLIR
TPU-MLIR是一种专用于处理器的TPU编译器。该编译器项目提供了一个完整的工具链,可以将来自不同深度学习框架(PyTorch, ONNX, TFLite和Caffe)的各种预训练神经网络模型转换为高效的模型文件(bmodel/cvimodel),以便在SOPHON TPU上运行。通过量化到不同精度的bmodel/cvimodel,优化了模型在sophon计算TPU上的加速和性能。这使得可以将与对象检测、语义分割和对象跟踪相关的各种模型部署到底层硬件上以实现加速。
-
支持多种深度学习框架
目前支持的框架包括PyTorch、ONNX、TFLite和Caffe。来自其他框架的模型需要转换为ONNX模型。有关将其他深度学习架构的网络模型转换为ONNX的指导,请参考ONNX官方网站:https://github.com/onnx/tutorials。 -
用户友好的操作
通过开发手册和相关部署案例了解TPU-MLIR的原理和操作步骤,可以从头开始进行模型部署。熟悉Linux命令和模型编译量化命令对于动手实践是足够的。 -
简化量化部署步骤
模型转换需要在SOPHGO提供的docker中执行,主要包括两个步骤:使用model_transform.py将原始模型转换为MLIR文件,使用model_deploy.py将MLIR文件转换为bmodel格式。bmodel是可以在SOPHGO TPU硬件上加速的模型文件格式。 -
适应多种架构和硬件模式
量化的bmodel模型可以在PCIe和SOC模式下运行在TPU上进行性能测试。
AI编译器的流程
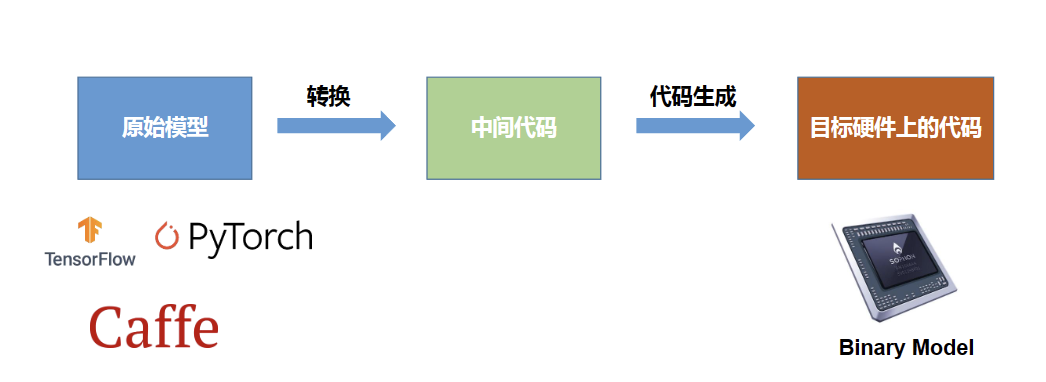
SophonSDK是算能科技基于其自主研发的 AI 芯片所定制的深度学习 SDK,涵盖了神经网络推理阶段所需的模型优化、高效运行支持等能力,为深度学习应用开发和部署提供易用、高效的全栈式解决方案。
基础工具包:
• tpu-nntc 负责对第三方深度学习框架下训练得到的神经网络模型进行离线编译和优化,生成最终运行时需要的BModel。目前支持Caffe、Darknet、MXNet、ONNX、PyTorch、PaddlePaddle、TensorFlow等。
• libsophon 提供BMCV、BMRuntime、BMLib等库,用来驱动VPP、TPU等硬件,完成图像处理、张量运算、模型推理等操作,供用户进行深度学习应用开发。
• sophon-mw 封装了BM-OpenCV、BM-FFmpeg等库,用来驱动VPU、JPU等硬件,支持RTSP流、GB28181流的解析,视频图像编解码加速等,供用户进行深度学习应用开发。
• sophon-sail 提供了支持Python/C++的高级接口,是对BMRuntime、BMCV、BMDecoder、BMLib等底层库接口的封装,供用户进行深度学习应用开发。
高阶工具包:
• tpu-mlir 为TPU编译器工程提供一套完整的工具链,可以将不同框架下预训练的神经网络,转化为可以在算能TPU上高效运行的二进制文件BModel。目前直接支持的框架包括tflite、onnx和Caffe。
• tpu-perf 为模型性能和精度验证提供了一套完整工具包。
• tpu-kernel 是芯片底层开发接口,既可以调用专用指令实现深度学习业务逻辑的加速,又可以调用通用指令实现客制的各种算法加速。
github的TPU-MLIR代码
sophon-sail 用户手册
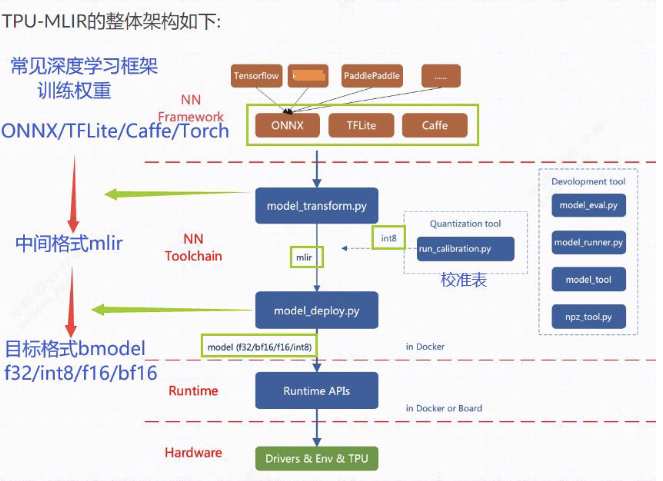
目前直接支持的框架有PyTorch、ONNX、TFLite和Caffe。其他框架的模型需要转换成ONNX模型。如何将其他深 度学习架构的网络模型转换成ONNX, 可以参考ONNX官网ONNX官网。
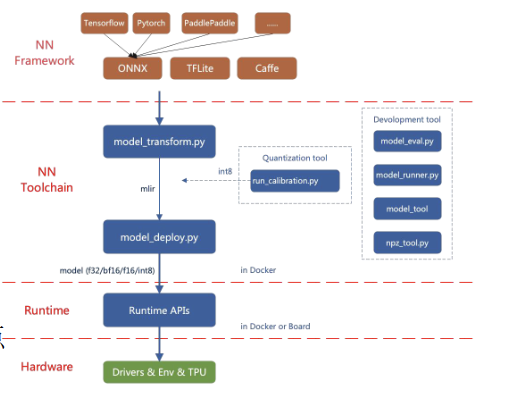
模型转换需要在指定的docker执行, 主要分两步, 一是通过 model_transform.py 将原始模型 转换成mlir文件, 二是通过 model_deploy.py 将mlir文件转换成bmodel。
如果要转INT8模型, 则需要调用 run_calibration.py生成校准表, 然后传给 model_deploy.py。如果INT8模型不满足精度需要, 可以调用
run_qtable.py 生成量化表, 用来决定哪些层采用浮点计算,然后传给 model_deploy.py 生成混精度模型。
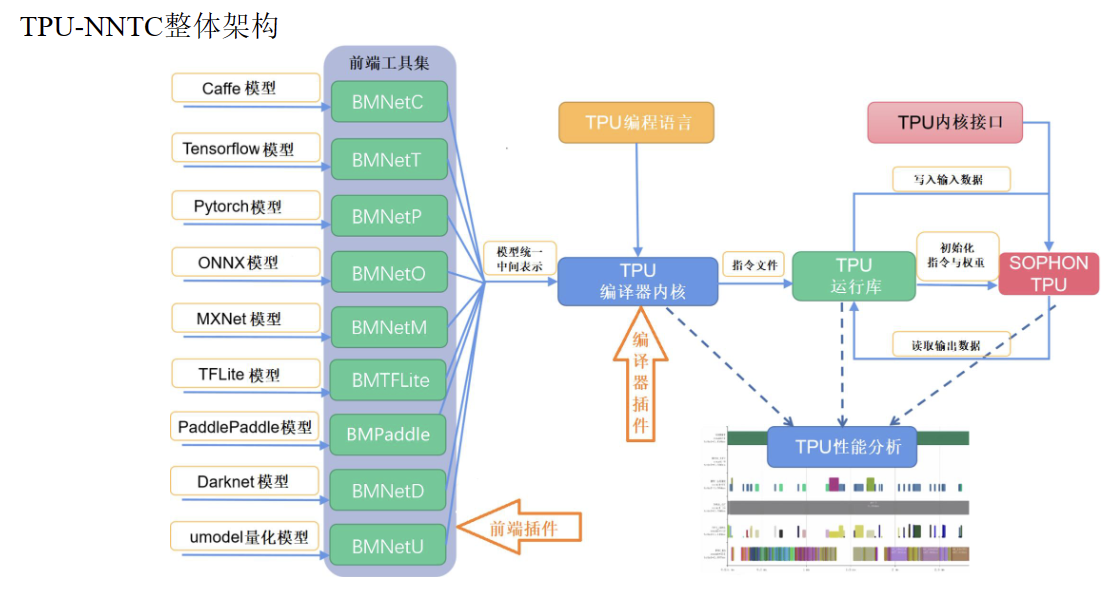
TPU-NNTC针对不同深度学习框架需要不同的前端
编译命令:
BMNetC: 面向Caffe model的BMCompiler前端
BMNetT: 面向TensorFlow model的BMCompiler前端
BMNetM: 面向MxNet model的BMCompiler前端
BMNetP: 面向PyTorch model的BMCompiler前端
BMNetD: 面向Darknet model的BMCompiler前端
BMNetO: 面向ONNX model的BMCompiler前端
BMPaddle: 面向PaddlePaddle model的BMCompiler前端
资料:
- 官网 我自己的这篇文章总结了官网的前两章内容·引言&编译器概述


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)