


python学习——爬取数据到mysql
承接上文,上次把数据爬取到了excel中,这次在上次代码的基础上进行修改,将数据直接上传到mysql中

# -*- coding:utf-8 -*- import requests from bs4 import BeautifulSoup import urllib.request, urllib.error import pymysql # mysql数据导入需要的包 import re # 影片链接 findlink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,表示规则 # 影片图片链接 findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) # re.S使换行符包含在字符中 # 片名 findTitle = re.compile(r'<span class="title">(.*?)</span>') # 影片评分 findRate = re.compile(r'<span class="rating_num" property="v:average">(.*?)</span>') # 评价人数 findJudge = re.compile(r'<span>(\d*)人评价</span>') # 概况 findIng = re.compile(r'<span class="inq">(.*)</span>') # 找到影片内容 findBd = re.compile(r'<p class="">(.*?)</p>', re.S) db = pymysql.connect(host='localhost', user='root', password='jia237106-', db='db2', charset='utf8') cursor = db.cursor() def askUrl(url): # 模拟浏览器头部 head = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36"} request = urllib.request.Request(url, headers=head) html = "" try: response = urllib.request.urlopen(request) html = response.read().decode("utf-8") except urllib.error.URLError as e: if hasattr(e, "code"): print(e.code) if hasattr(e, "reason"): print(e.reason) return html def getData(baseurl): datalist = [] for i in range(0, 10): url = baseurl + str(i * 25) html = askUrl(url) # 逐一解析数据 soup = BeautifulSoup(html, "html.parser") for item in soup.find_all('div', class_="item"): # 查找符合要求的字符串 data = [] # 保存一部电影所有信息,列表 item = str(item) # 影片链接 link = re.findall(findlink, item)[0] # re库通过正则表达式查找指定字符串 data.append(link) imgSrc = re.findall(findImgSrc, item)[0] data.append(imgSrc) titles = re.findall(findTitle, item) # 片名可能只有一个中文名 if (len(titles) == 2): ctitle = titles[0] data.append(ctitle) ftitle = titles[1].replace("/", "") data.append(ftitle) else: data.append(titles[0]) data.append(' ') # 外文名留空 rate = re.findall(findRate, item)[0] data.append(rate) judge = re.findall(findJudge, item)[0] data.append(judge) ing = re.findall(findIng, item) if (len(ing) != 0): ing = ing[0].replace("。", "") data.append(ing) else: data.append(' ') bd = re.findall(findBd, item)[0] bd = re.sub('<br(\s+)?/>(\s+)?', " ", bd) # 去掉<br/> bd = re.sub('/', " ", bd) data.append(bd.strip()) # 去掉空格 datalist.append(data) return datalist def saveDB(datalist): for i in range(0, 250): data = datalist[i]
# sql语句尽量用三引号,获取数据的方式不变 sql = '''insert into movie values(%s,%s,%s,%s,%s,%s,%s,%s)''' cursor.execute(sql, data) db.commit() if __name__ == '__main__': url = "https://movie.douban.com/top250?start=" datalist = getData(url) saveDB(datalist)
效果
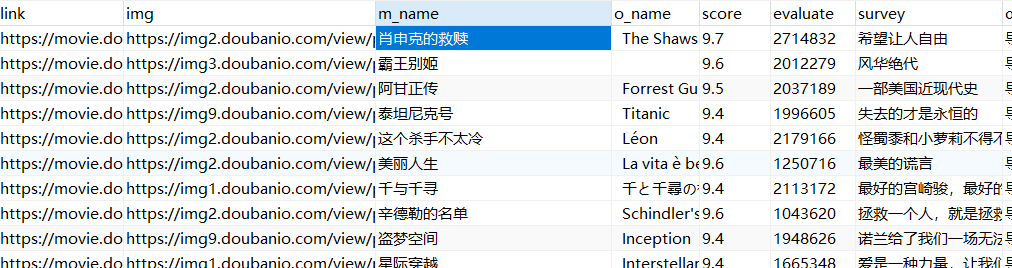


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· DeepSeek在M芯片Mac上本地化部署
2021-10-16 Java学习二十三--新课程添加