
浏览器工作机制及资源加载
浏览器的工作机制
一句话概括起来就是:web浏览器与web服务器之间通过HTTP协议进行通信的过程。所以,C/S之间握手的协议就是HTTP协议。浏览器接收完毕开始渲染之前大致过程如下:

从浏览器地址栏的请求链接开始,浏览器通过DNS解析查到域名映射的IP地址,成功之后浏览器端向此IP地址取得连接,成功连接之后,浏览器端将请 求头信息 通过HTTP协议向此IP地址所在服务器发起请求,服务器接受到请求之后等待处理,最后向浏览器端发回响应,此时在HTTP协议下,浏览器从服务器接收到 text/html类型的代码,浏览器开始显示此html,并获取其中内嵌资源地址,然后浏览器再发起请求来获取这些资源,并在浏览器的html中显示。
离我们最近并能直接显示一个完整通信过程的工具就是Firebug了,看下图:

其中黄色的tips浮层告诉了我们www.baidu.com”的html资源从发起请求到关闭连接整个过程中每个环节的时长(域名解析 -> 建立连接 -> 发起请求 -> 等待响应 -> 接收数据),点击该请求,可以获得HTTP的headers信息,包含响应头信息与请求头信息,如:


了解浏览器加载、解析、渲染这个过程
-
了解浏览器如何进行加载,我们可以在引用外部样式文件,外部js时,将他们放到合适的位置,使浏览器以最快的速度将文件加载完毕。
-
了解浏览器如何进行解析,我们可以在构建DOM结构,组织css选择器时,选择最优的写法,提高浏览器的解析速率。
-
了解浏览器如何进行渲染,明白渲染的过程,我们在设置元素属性,编写js文件时,可以减少”重绘“”重新布局“的消耗。
这三个过程在实际进行的时候又不是完全独立,而是会有交叉。会造成一边加载,一边解析,一边渲染的工作现象
关于加载顺序:当浏览器获得一个html文件时,会”自上而下“加载,并在加载过程中进行解析渲染。
加载
即为获取资源文件的过程,不同浏览器,以及他们的不同版本在实现这一过程时,会有不同的实现效果(资源间互相阻塞),。(需要学习使用timeline来做测试,我还不太会用,学会了在上文。)
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <link rel="stylesheet" href="test.css" type="text/css" /> <script src="test.js" type="text/javascript"></script> </head> <body> <p>阻塞</p> <img src="test.jpg" /> </body> </html>
加载过程中遇到外部css文件,浏览器另外发出一个请求,来获取css文件。
遇到图片资源,浏览器也会另外发出一个请求,来获取图片资源。这是异步请求,并不会影响html文档进行加载,但是当文档加载过程中遇到js文件,html文档会挂起渲染(加载解析渲染同步)的线程,不仅要等待文档中js文件加载完毕,还要等待解析执行完毕,才可以恢复html文档的渲染线程。
原因:JS有可能会修改DOM,最为经典的document.write,这意味着,在JS执行完成前,后续所有资源的下载可能是没有必要的,这是js阻塞后续资源下载的根本原因。
办法:可以将外部引用的js文件放在</body>前。
虽然css文件的加载不影响js文件的加载,但是却影响js文件的执行,即使js文件内只有一行代码,也会造成阻塞。
原因:可能会有 var width = $('#id').width(),这意味着,js代码执行前,浏览器必须保证css文件已下载和解析完成。这也是css阻塞后续js的根本原因。
办法:当js文件不需要依赖css文件时,可以将js文件放在头部css的前面。
当然除了,<link href="" />这种形式,内部<style></style>这种样式定义,在考虑阻塞时也要考虑。
以上对于代码布局对文档加载的影响是比较基础的,随着浏览器的升级,以及js技术的应用,html的发展,web性能也会逐渐提高。
列举一下,以后可以逐一扩充一下:
-
不要在外部调用的js文件中调用运行时间较长的函数,如果一定要用,可以使用setTimeout函数。
为什么呢?
- 浏览器GUI渲染线程
- javascript引擎线程
- 浏览器定时器触发线程(setTimeout)
- 浏览器事件触发线程
- 浏览器http异步请求线程(
.jpg<link />这类请求)
原因:浏览器有以上五个常驻线程
发现第3个线程,我们便知道,如果在js内使用setTimeout()那么会调用另一个线程。
注意:这里也涉及到 阻塞 的现象,当js引擎线程(第二个)进行时,会挂起其他一切线程,这个时候3、4、5这三类线线程也会产生不同的异步事件(这句话不懂啊),由于 javascript引擎线程为单线程,所以代码都是先压到队列,采用先进先出的方式运行,事件处理函数,timer函数也会压在队列中,不断的从队头取出事件,这就叫:javascript-event-loop。
-
现代浏览器存在 prefetch 优化,浏览器会另外开启线程,提前下载js、css文件,需要注意的是,预加载js并不会改变dom结构,他将这个工作留给主加载。
- 预加载网页,利用空余时间来提前加载该网页的后续网页。
<link rel="prefetch" href="http://">
- 为js脚本添加defer属性,使得浏览器不等js脚本加载执行完,就加载后面的图片。既然图片资源都已经加载出来了,就不要在js内写document.write啦。
<script defer="true" src="JavaScript.js" type="text/javascript"/>
解析
解析的概念有些多,需要另写一篇文章。于是我就先简单的写一下。
-
html文档解析生成解析树即dom树,是由dom元素及属性节点组成,树的根是document对象。
DOM:文档对象模型的缩写,是html文档的对象表示,作为html的外部接口供js调用。
document.getElementById('test').style.display="none";//通过dom接口将id为test的display值设为none。
-
css解析将css文件解析为样式表对象。该对象包含css规则,该规则包含选择器和声明对象。

- js解析因为文件在加载的同时也进行解析,详看js加载部分。
渲染
即为构建渲染树的过程,他是原来DOM树的可视化表示,构建这棵树是为了以正确的顺序绘制文档内容。
渲染树和DOM树的关系,不可见的dom元素(<head>…</head> display=none)不会被插入渲染树中。还有像一些节点的位置为绝对或浮动定位(需要css知识理解),这些节点会在文本流之外,因此会在两棵树上的不同位置,渲染树标识出真实的位置,并用一个占位结构标识出他们原来的位置。
渲染最大的一个困难就是为每一个dom节点计算符合他的最终样式。
- 为每一个元素查找到匹配的样式规则,需要遍历整个规则表。关于遍历规则表的方法,我之前理解错啦。
正解:遍历是自右向左,也就是先查询到p元素,再找到上一级id为test的元素。之前的理解正好相反。这样发现,遍历的效率好低。
#test p{ color:#999999}
为什么:可以去看之前css解析时,生成的样式对象,遍历的顺序,自然是从树的低端向上遍历。
计算样式的一些困难:
- 样式数据是非常大的结构,保存这样是的数据是很耗内存的。
- 选择器迭代太深,造成太多的无用遍历。
- 样式规则涉及非常复杂的级联,定义了规则的层次(理解:
<head>里引用的外部样式表,会被局部样式表中同一属性的设置取代。还有例如body内对font的设置本来会应用于孩子元素,但是如果body的孩子元素定义font属性,则会被后者取代)。
解决办法:共享样式数据。(元素可以共享样式数据的条件就是他们的状态是”一致“的。)
JS 和 CSS 的位置对其他资源加载顺序的影响
JS 和 CSS 在页面中的位置,会影响其他资源(指 img 等非 js 和 css 资源)的加载顺序,究其原因,有三个值得注意的点:
- JS 有可能会修改 DOM. 典型的,可能会有
document.write. 这意味着,在当前 JS 加载和执行完成前,后续所有资源的下载有可能是没必要的。这是 JS 阻塞后续资源下载的根本原因。 - JS 的执行有可能依赖最新样式。比如,可能会有
var width = $('#id').width(). 这意味着,JS 代码在执行前,浏览器必须保证在此 JS 之前的所有 css(无论外链还是内嵌)都已下载和解析完成。这是 CSS 阻塞后续 JS 执行的根本原因。 - 现代浏览器很聪明,会进行 prefetch 优化。性能是如此重要,现代浏览器在竞争中,在 UI update 线程之外,还会开启另一个线程,对后续 JS 和 CSS 提前下载(注意,仅提前下载,并不执行)。有了 prefetch 优化,这意味着,在不存在任何阻塞的情况下,理论上 JS 和 CSS 的下载时机都非常优先,和位置无关。
以上三点可简述为三条基本定律:
- 定律一:资源是否下载依赖 JS 执行结果。
- 定律二:JS 执行依赖 CSS 最新渲染。
- 定律三:现代浏览器存在 prefetch 优化。
有了这三条定律,再来看克军的测试,就很清晰了:
a,b – head里出现外联js,无论如何放,css文件都不能和body里的请求并行
根据定律一和定律三,可以知道上面的结论不够正确。比如:
1 <head> 2 <link rel="stylesheet" href="mock.php?css1&sleep=2"> 3 <script src="mock.php?js&sleep=3"></script> 4 <link rel="stylesheet" href="mock.php?css2&sleep=4"> 5 </head> 6 <body> 7 <link rel="stylesheet" href="mock.php?css3&sleep=5"> 8 <img src="test.gif"> 9 </body>
在 Chrome 下的瀑布图是:
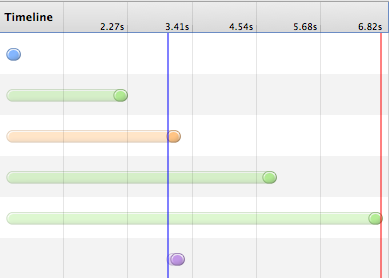
黄色条是 js 的,可以看出 img 的延时下载是由定律一决定的。
定律三则决定了所有 js/css 都是并行开始下载的。在 Firefox 10 下,prefetch 非常强悍,对 img 也会预加载,瀑布图如下:

调整一下 sleep 时间,还可以观察到定律二的威力:
1 <head> 2 <link rel="stylesheet" href="mock.php?css1&sleep=3"> <!-- 修改 sleep 值,使其大于 js 的 --> 3 <script src="mock.php?js&sleep=2"></script> 4 <link rel="stylesheet" href="mock.php?css2&sleep=4"> 5 </head> 6 <body> 7 <link rel="stylesheet" href="mock.php?css3&sleep=5"> 8 <img src="test.gif"> 9 </body>
瀑布图立刻发生了变化:
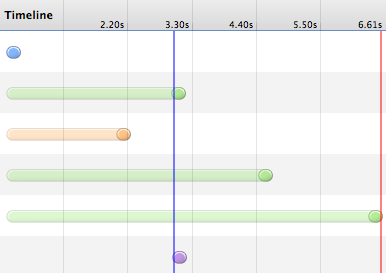
因为定律一,决定 img 的下载在 js 执行后。又因为定律二,决定 js 的执行在第一个 css 后。于是最后在瀑布图上体现出来,就是 img 的下载在第一个 css 后。
再来看克军的第二个结论:
c – head里的内联js只要在所有外联css前面,css文件可以和body里的请求并行(图2)
d – head里的内联js只要在任一外联css后面,css文件就不能和body里的请求并行(图1)
这个是定律二的威力。结论 c 是正确的,因为没有 css 会影响 js 的执行。结论 d 则不够正确。img 等其他资源,会在 js 前面的 css 下载完成后,以及 js 执行后,立刻开始下载。与头部中,js 位置之后的 css 没关系。
克军的其他结论都是对的,不多说。
注意1:Firefox 10 的 prefetch 有点奇怪,有时会对 img 进行 prefetch,有时则不会。有兴趣的可以进一步寻找规律。
注意2:上面的三个定律,是黑盒猜测,有兴趣的可以去阅读浏览器的源码,应该能找到更深层次的原因。
注意3:本文没有考虑 defer, async 属性的影响,这是另一个故事。
js 程序执行与顺序实现详解
JavaScript是一种描述型脚本语言,它不同于java或C#等编译性语言,它不需要进行编译成中间语言,而是由浏览器进行动态地解析与执行。如果 你不能理解javaScript语言的运行机制,或者简单地说,你不能掌握javascript的执行顺序,那你就犹如伯乐驾驭不了千里马,让千里马脱缰 而出,四处乱窜。
那么JavaScript是怎么来进行解析的吗?它的执行顺序又是如何的呢?在了解这些之前,我们先来认识几个重要的术语:
1、代码块
JavaScript中的代码块是指由<script>标签分割的代码段。例如:
<script type="text/javascript"> alert("这是代码块一"); </script> <script type="text/javascript"> alert("这是代码块二"); </script>
JS是按照代码块来进行编译和执行的,代码块间相互独立,但变量和方法共享。什么意思呢? 举个例子,你就明白了:
<script type="text/javascript"> alert(str);//因为没有定义str,所以浏览器会出错,下面的不能运行 alert("我是代码块一");//没有运行到这里 var test = "我是代码块一变量"; </script> <script type="text/javascript"> alert("我是代码块二"); //这里有运行到 alert(test); //弹出"我是代码块一变量" </script>
上面的代码中代码块一中运行报错,但不影响代码块二的执行,这就是代码块间的独立性,而代码块二中能调用到代码一中的变量,则是块间共享性。、
2、声明式函数与赋值式函数
JS中的函数定义分为两种:声明式函数与赋值式函数。
<script type="text/javascript"> function Fn(){ //声明式函数 } var Fn = function{ //赋值式函数 } </script>
声明式函数与赋值式函数的区别在于:在JS的预编译期,声明式函数将会先被提取出来,然后才按顺序执行js代码。
3、预编译期与执行期
事实上,JS的解析过程分为两个阶段:预编译期(预处理)与执行期。
预编译期JS会对本代码块中的所有声明的变量和函数进行处理(类似与C语言的编译),但需要注意的是此时处理函数的只是声明式函数,而且变量也只是进行了声明但未进行初始化以及赋值。
<script type="text/javascript"> Fn(); //执行结果:"执行了函数2",同名函数后者会覆盖前者 function Fn(){ //函数1 alert("执行了函数1"); } function Fn(){ //函数2 alert("执行了函数2"); } </script>
<script type="text/javascript"> Fn(); //执行结果:"执行了声明式函数",在预编译 //期声明函数及被处理了,所以即使Fn()调用函数 //放在声明函数前也能执行。 function Fn(){ //声明式函数 alert("执行了声明式函数"); } var Fn = function(){ //赋值式函数 alert("执行了赋值式函数"); } </script>
//代码块一 <script type="text/javascript"> alert(str);//浏览器报错,但并没有弹出信息窗 </script> //代码块二 <script type="text/javascript"> alert(str); //弹窗"undefined" var str = "aaa"; </script> //js在预处理期对变量进行了声明处理,但是并没有进 //行初始化与赋值,所以导致代码块二中的变量是unfiened的 //,而代码一中的变量是完全不存在的,所以浏览器报错。
理解了上面的几个术语,相信大家对JS的运行机制已经有了个大概的印象了,现在我们来看个例子:
<script type="text/javascript"> Fn(); //浏览器报错:"undefined" </script> <script type="text/javascript"> function Fn(){ //函数1 alert("执行了函数1"); } </script>
为什么运行上面的代码浏览器会报错呢?声明函数不是会在预处理期就会被处理了吗,怎么还会找不到Fn()函数呢?其实这是一个理解误点,我们上面 说了JS引擎是按照代码块来顺序执行的,其实完整的说应该是按照代码块来进行预处理和执行的,也就是说预处理的只是执行到的代码块的声明函数和变量,而对 于还未加载的代码块,是没法进行预处理的,这也是边编译边处理的核心所在。
现在,让我们来总结整理下:
step 1. 读入第一个代码块。
step 2. 做语法分析,有错则报语法错误(比如括号不匹配等),并跳转到step5。
step 3. 对var变量和function定义做“预编译处理”(永远不会报错的,因为只解析正确的声明)。
step 4. 执行代码段,有错则报错(比如变量未定义)。
step 5. 如果还有下一个代码段,则读入下一个代码段,重复step2。
step6. 结束。
而根据HTML文档流的执行顺序,需要在页面元素渲染前执行的js代码应该放在<body>前面的<script>代码块 中,而需要在页面元素加载完后的js放在</body>元素后面,body标签的onload事件是在最后执行的。
<script type="text/javascript"> alert("first"); function Fn(){ alert("third"); } </script> <body onload="Fn()"> </body> <script type="text/javascript"> alert("second"); </script>
http://blog.163.com/seo_luofeng/blog/static/176575024201242412342680/
http://www.jianshu.com/p/e141d1543143
http://www.51testing.com/html/38/225738-220986.html
http://www.cnblogs.com/dongfengyuxy/p/5850105.html

