

IMDB电影排行爬取分析
一.打开IMDB电影T250排行可以看见250条电影数据,电影名,评分等数据都可以看见
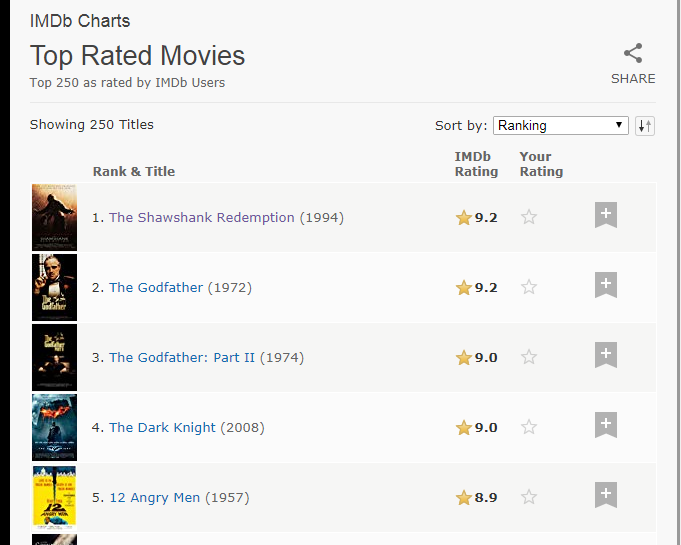
按F12进入开发者模式,找到这些数据对应的HTML网页结构,如下所示
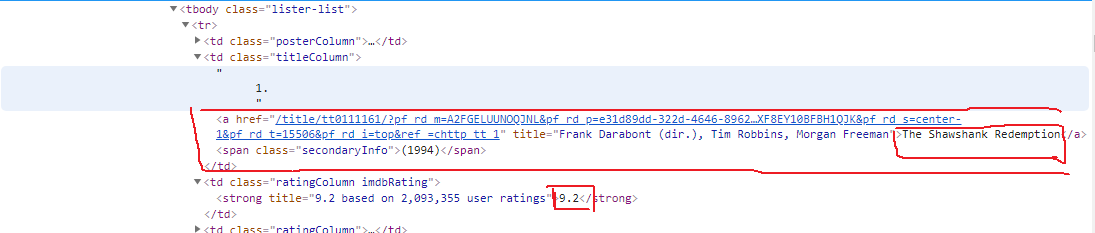
可以看见里面有链接,点击链接可以进入电影详情页面,这可以看见导演,编剧,演员信息

同样查看HTML结构,可以找到相关信息的节点位置

演员信息可以在这个页面的cast中查看完整的信息

HTML页面结构
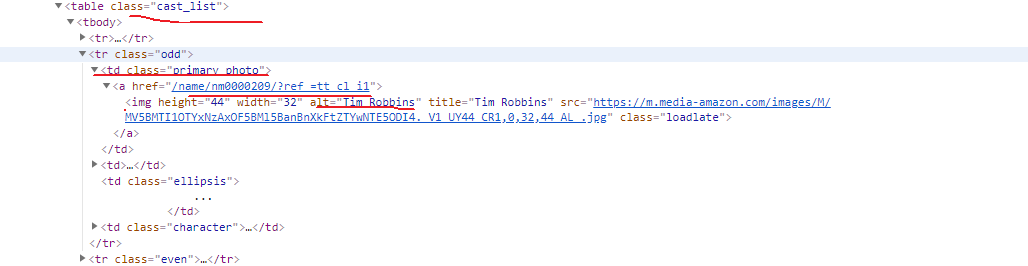
分析完整个要爬取的数据,现在来获取首页250条电影信息
1.整个爬虫代码需要使用的相关库
import re import pymysql import json import requests from bs4 import BeautifulSoup from requests.exceptions import RequestException
2.请求首页的HTML网页,(如果请求不通过可以添加相关Header),返回网页内容
def get_html(url): response=requests.get(url) if response.status_code==200: #判断请求是否成功 return response.text else: return None
3.解析HTML
def parse_html(html): #进行页面数据提取 soup = BeautifulSoup(html, 'lxml') movies = soup.select('tbody tr') for movie in movies: poster = movie.select_one('.posterColumn') score = poster.select_one('span[name="ir"]')['data-value'] movie_link = movie.select_one('.titleColumn').select_one('a')['href'] #电影详情链接 year_str = movie.select_one('.titleColumn').select_one('span').get_text() year_pattern = re.compile('\d{4}') year = int(year_pattern.search(year_str).group()) id_pattern = re.compile(r'(?<=tt)\d+(?=/?)') movie_id = int(id_pattern.search(movie_link).group()) #movie_id不使用默认生成的,从数据提取唯一的ID movie_name = movie.select_one('.titleColumn').select_one('a').string #使用yield生成器,生成每一条电影信息 yield { 'movie_id': movie_id, 'movie_name': movie_name, 'year': year, 'movie_link': movie_link, 'movie_rate': float(score) }
4.我们可以保存文件到txt文本
def write_file(content): with open('movie12.txt','a',encoding='utf-8')as f: f.write(json.dumps(content,ensure_ascii=False)+'\n') def main(): url='https://www.imdb.com/chart/top' html=get_html(url) for item in parse_html(html): write_file(item) if __name__ == '__main__': main()
5.数据可以看见

6.如果成功了,可以修改代码保存数据到MySQL,使用Navicat来操作非常方便先连接到MySQL
db = pymysql.connect(host="localhost", user="root", password="********", db="imdb_movie") cursor = db.cursor()
创建数据表
CREATE TABLE `top_250_movies` ( `id` int(11) NOT NULL, `name` varchar(45) NOT NULL, `year` int(11) DEFAULT NULL, `rate` float NOT NULL, PRIMARY KEY (`id`) )
接下来修改代码,操作数据加入数据表
def store_movie_data_to_db(movie_data): sel_sql = "SELECT * FROM top_250_movies \ WHERE id = %d" % (movie_data['movie_id']) try: cursor.execute(sel_sql) result = cursor.fetchall() except: print("Failed to fetch data") if result.__len__() == 0: sql = "INSERT INTO top_250_movies \ (id, name, year, rate) \ VALUES ('%d', '%s', '%d', '%f')" % \ (movie_data['movie_id'], movie_data['movie_name'], movie_data['year'], movie_data['movie_rate']) try: cursor.execute(sql) db.commit() print("movie data ADDED to DB table top_250_movies!") except: # 发生错误时回滚 db.rollback() else: print("This movie ALREADY EXISTED!!!")
运行
def main(): url='https://www.imdb.com/chart/top' html=get_html(url) for item in parse_html(html): store_movie_data_to_db(item) if __name__ == '__main__': main()
查看Navicat,可以看到保存到mysql的数据。
