
第三次作业
一、
Github地址:https://github.com/ioklkiol/WordCount
结对伙伴的博客作业地址:https://www.cnblogs.com/qinhesheng/p/10647992.html
二、结对过程:这次作业我与结对伙伴商量之后结成了队伍,并一起商议了作业思路以及任务分工,结对伙伴对这次任务的主要思路和代码部分做出了主要贡献。以下是我们工作时的照片:

3、PSP表格:
|
PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
Planning |
计划 |
20 | 20 |
|
· Estimate |
· 估计这个任务需要多少时间 |
20 | 20 |
|
Development |
开发 |
650 | 910 |
|
· Analysis |
· 需求分析 (包括学习新技术) |
200 | 300 |
|
· Design Spec |
· 生成设计文档 |
40 | 60 |
|
· Design Review |
设计复审 (和同事审核设计文档) |
10 | 10 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
30 | 30 |
|
· Design |
· 具体设计 |
70 | 60 |
|
· Coding |
· 具体编码 |
200 | 350 |
|
· Code Review |
· 代码复审 |
50 | 30 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
50 | 70 |
|
Reporting |
报告 |
40 | 70 |
|
· Test Report |
· 测试报告 |
20 | 30 |
|
· Size Measurement |
· 计算工作量 |
10 | 10 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
10 | 30 |
|
合计 |
710 | 1000 |
四、解题思路描述
1.首先把文件内容读出来
2.用字符串的str.Length属性统计文件的字符数
3.用正则表达式判断是否为有效单词
4.用List统计文件的单词总和有效行数
5.用List和Dictionary统计文件中各单词的出现次数并排序
五、设计实现过程
主要流程:
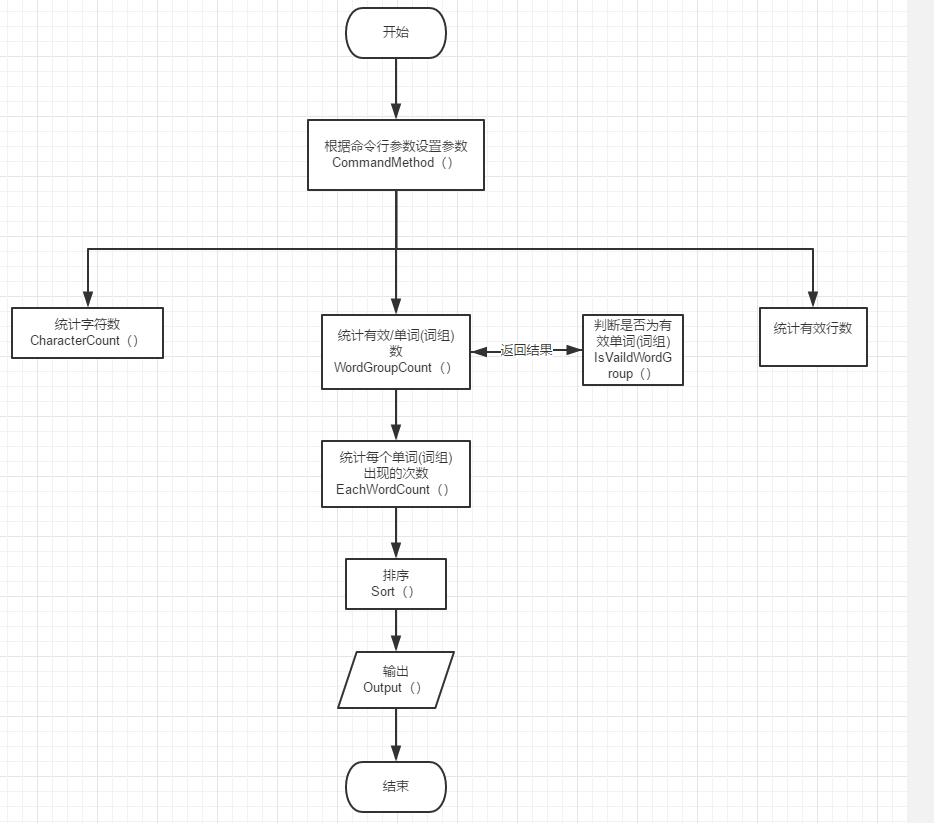
WordGroupCount函数:

六、代码规范
我们为了本次合作编程过程统一,做出了如下规范:
1、 统一使用4个空格缩进
2、 每个“{”和“}”都独占一行,一行不会出现多个语句。
3、 变量名不用单个字母而用本意的英语单词,。
4、 尽量不出现以大小写区分的变量,以免混淆。
5、 不使用以下划线区分的变量,以免混淆。。
6、 注释要精简且准确解释该部分代码。
七、代码互审
我负责的代码比较简单的部分,而结对伙伴的代码交由我多次检测运行之后,也是没有问题的。
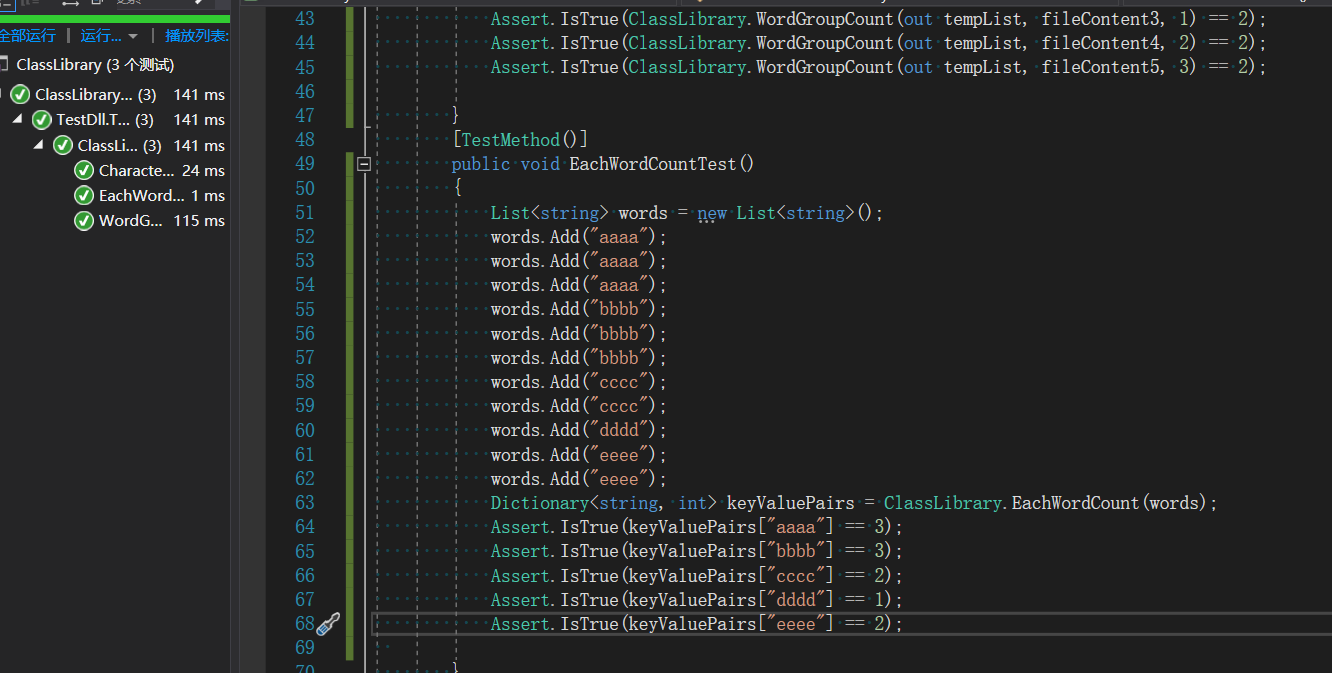
八、单元测试

九、效能分析

可以看出主要的改进空间在WordCount(之后更名为WordGroupCount)函数上,该函数调用了一个判断是否为有效单词的函数,这个函数是通过判断ASCII码来实现的,用了10分钟改为用正则表达式实现
十、代码说明

此函数用于得到一个有效单词(词组)的List

该函数用用于统计各个单词(词组)出现的次数,返回一个Dictionary,单词(词组)的名称为Key,出现的次数为Value
十一、感受
这次的作业我们认为效果是1+1<2的。对于我来说,我个人的能力相对于我的结对伙伴要弱了很多,且两人的能力方面没有出现互补的情况,因此很难达到各自发挥擅长的能力以解决两人遇到的问题,在两人合作商议问题的时候也难以快速找到关键点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号