四、利用Sqoop导出Hive分析数据到MySQL库
四、利用Sqoop导出Hive分析数据到MySQL库
Sqoop概述
Sqoop是一款开源的工具,主要用于在Hadoop生态系统(Hadoop、Hive等)与传统的数据库(MySQL、Oracle等)间进行数据的传递,可以将一个关系型数据库中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导入到关系型数据库中。
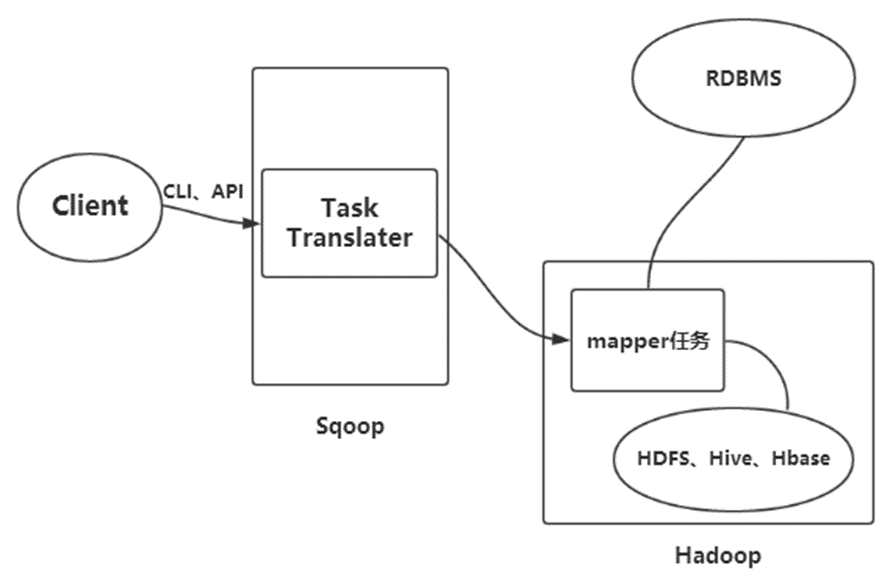
Sqoop导入原理:
在导入开始之前,Sqoop使用JDBC来检查将要导入的表。他检索出表中所有的列以及列的SQL数据类型。这些SQL类型(varchar、integer)被映射到Java数据类型(String、Integer等),在MapReduce应用中将使用这些对应的Java类型来保存字段的值。Sqoop的代码生成器使用这些信息来创建对应表的类,用于保存从表中抽取的记录。Sqoop启动的MapReduce作业用到一个InputFormat,他可以通过JDBC从一个数据库表中读取部分内容。
Hadoop提供的DataDriverDB InputFormat能为查询结果进行划分传给指定个数的map任务。为了获取更好的导入性能,查询会根据一个“划分列”来进行划分。Sqoop会选择一个合适的列作为划分列(通常是表的主键)。在生成反序列化代码和配置InputFormat之后,Sqoop将作业发送到MapReduce集群。Map任务将执行查询并将ResultSet中的数据反序列化到生成类的实例,这些数据要么直接保存在SequenceFile文件中,要么在写到HDFS之前被转换成分割的文本。Sqoop不需要每次都导入整张表,用户也可以在查询中加入到where子句,以此来限定需要导入的记录。
Sqoop导出原理:
Sqoop导出功能的架构与其导入功能非常相似,在执行导出操作之前,Sqoop会根据数据库连接字符串来选择一个导出方法。一般为JDBC。然后,Sqoop会根据目标表的定义生成一个Java类。这个生成的类能够从文本文件中解析记录,并能够向表中插入合适类型的值。接着会启动一个MapReduce作业,从HDFS中读取源数据文件,使用生成的类解析记录,并且执行选定的导出方法。
准备环境
1.首先切换到/data目录下,创建名为edu4的目录
- cd /data
- mkdir /data/edu4
再切换目录到/data/edu4目录下,下载实验所需的文件。
- cd /data/edu4
- wget http://192.168.1.100:60000/allfiles/second/edu4/govdata
- wget http://192.168.1.100:60000/allfiles/second/edu4/govnums
2.输入jps,查看hadoop是否已经启动
- jps
若未启动,则执行启动Hadoop命令
- cd /apps/hadoop/sbin
- ./start-all.sh
启动MySQL服务(数据库密码为:zhangyu)
- sudo service mysql start
查看MySQL服务是否已经启动
- sudo service mysql status
3.启动Hive
- hive
在Hive中创建数据库名为edu4,并切换到edu4下
- create database edu4;
- use edu4;
在Hive中创建govdata表,
- create table govdata(
- leixing string,
- biaoti string,
- laixinren string,
- shijian string,
- number int,
- problem string,
- offic string,
- officpt string,
- officp string
- ) row format delimited
- fields terminated by '\t';
将/data/edu4/govdata评论数据导入到Hive的govdata表中
- load data local inpath '/data/edu4/govdata' into table govdata;
需求一,将Hive表中数据,导入到MySQL
统计govdata中,统计每年的信件数量,并将结果导到mysql中。
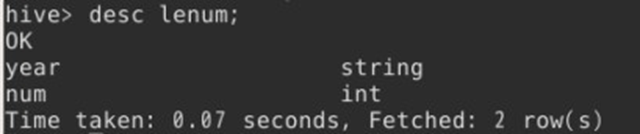
1.首先在Hive中,创建一张表,命名为lenum,用于存储统计结果。
- create table lenum(
- year string,
- num int
- )
- row format delimited
- fields terminated by '\t'
- stored as textfile;
lenum表,有两个字段:设备类型及设备数量
2.在Hive中,统计每年信件数量,并将结果临时存储在hive中的lenum表中。
- insert into table lenum
- select
- substr(shijian,0,4) as dt,
- count(1) as num
- from govdata
- group by substr(shijian,0,4)
- order by num;
查看lenum表。
- select * from lenum;
3.新打开一个命令行终端,连接Mysql(密码:strongs)
- mysql -u root -p
在mysql中,创建名为edu4out的数据库,用于存储导过来的数据
- CREATE DATABASE IF NOT EXISTS edu4out DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
- use edu4out
在Mysql中创建名为lenumsql的表,用于储蓄Hive中lenum表的数据。此表也包含两个字段时间及数量
- create table lenumsql (time varchar(10),num int);
4.再新开启一个终端模拟器,使用Sqoop命令将Hive中的lenum表导入到Mysql的lenumsql中。
- sqoop export \
- --connect jdbc:mysql://localhost:3306/edu4out?characterEncoding=UTF-8 \
- --username root \
- --password strongs \
- --table lenumsql \
- --export-dir /user/hive/warehouse/edu4.db/lenum/000000_0 \
- --input-fields-terminated-by '\t';
查看mysql中lenumsql表,数据内容
- select * from lenumsql;
这样,我们就将Hive中的lenum表数据成功导入到Mysql中了。
5.在执行导数据之前,可以进行一个测试,验证Sqoop是否可用
查看Mysql中的数据库。通过此步验证,可以测试出Sqoop以及Mysql是否可以正常连接
- sqoop list-databases \
- --connect jdbc:mysql://localhost:3306/ \
- --username root \
- --password strongs;
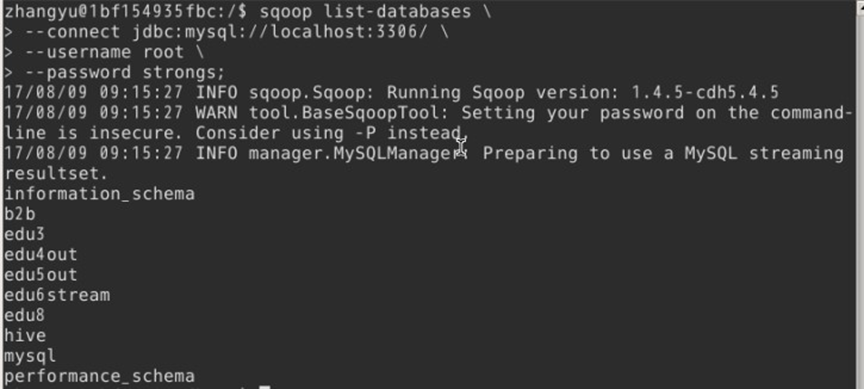
结果列出了Mysql中的所有数据库,证明Sqoop可以与Mysql正常连接。
需求二,将Hive表中数据,导入到MySQL
将hive中多久进行评论数据统计结果导入到Mysql中的dayssql表中
1.在Hive中,创建用户评论周期分析结果表typenums,包含两个字段类型及数量
- create table typenums(
- leixing string,
- num int
- )
- row format delimited
- fields terminated by '\t'
- stored as textfile;
2.对用户评论间隔时间进行统计,并将统计结果导入到Hive中的typenums表中。
- insert into table
- select
- leixing,
- count(1) as num
- from govdata
- group by leixing
- order by num desc;
查看Hive表typenums中的数据
- select * from typenums;
3.在Mysql端口创建typenum表,用于存储typenums中的数据。typenum中同样包含两个字段类型及数量
- create table typenum(leixing varchar(10),num int);
4.使用Sqoop命令将Hive的typenums表导入到Mysql的typenum里。
- sqoop export \
- --connect jdbc:mysql://localhost:3306/edu4out?characterEncoding=UTF-8 \
- --username root \
- --password strongs \
- --table typenum \
- --export-dir /user/hive/warehouse/edu4.db/typenums/000000_0 \
- --input-fields-terminated-by '\t';
查看mysql中typenum表。
- select * from typenum;
需求三,将HDFS数据导入到MySQL
将HDFS存储有政府回答问题数量统计结果数据文件govnums导入到MySQL中govnum表中
1.在HDFS上创建目录/myedu4/in,并将/data/edu4下的govnums文件上传到HDFS中的in目录下。
- hadoop fs -mkdir -p /myedu4/in
- hadoop fs -put /data/edu4/govnums /myedu4/in
2.在MySQL中,创建表govnum。表中包含两个字段用户等级名及数量
- create table govnum (govname varchar(50),num int);
3.使用Sqoop命令将HDFS中/myedu4/in/govnums导入到MySQL的govnum中。
- sqoop export \
- --connect jdbc:mysql://localhost:3306/edu4out?characterEncoding=UTF-8 \
- --username root \
- --password strongs \
- --table govnum \
- --export-dir /myedu4/in/govnums \
- --input-fields-terminated-by '\t'
查看govnum中的数据
- select * from govnum;

