二、编写MapReduce程序清洗信件内容数据
二、编写MapReduce程序清洗信件内容数据
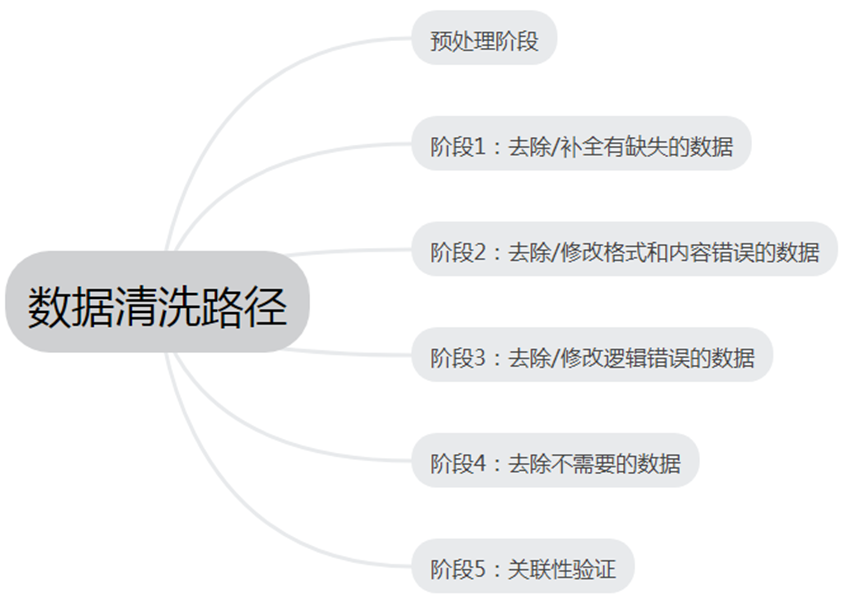
数据清洗概述
数据清洗是对数据进行重新审查和校验的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。
数据清洗从名字上也看的出就是把“脏”的“洗掉”,指发现并纠正数据文件中可识别的错误的最后一道程序,包括检查数据一致性,处理无效值和缺失值等。因为数据仓库中的数据是面向某一主题的数据的集合,这些数据从多个业务系统中抽取而来而且包含历史数据,这样就避免不了有的数据是错误数据、有的数据相互之间有冲突,这些错误的或有冲突的数据显然是我们不想要的,称为“脏数据”。我们要按照一定的规则把“脏数据”“洗掉”,这就是数据清洗。而数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取。不符合要求的数据主要是有不完整的数据、错误的数据、重复的数据三大类。数据清洗是与问卷审核不同,录入后的数据清洗一般是由计算机而不是人工完成。
分析需求
通过爬虫,我们可以得到咨询和投诉的详细页面。
页面内容如下,需要提取出对我们有用的信息
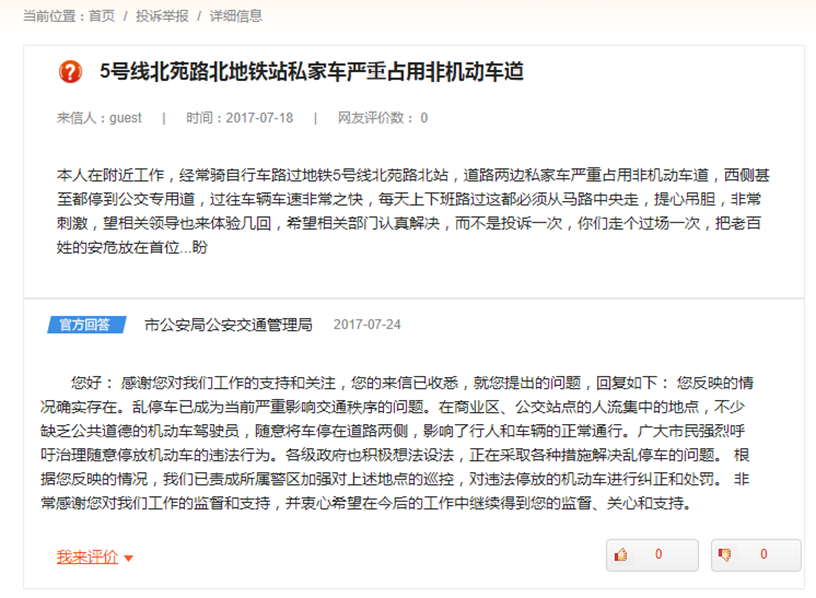
当然,判断字段是否对我们有用,判断依据是根据需求来定的。后续做的一些需求,会用到哪些字段,此处就会采集哪些字段。
这一节我们会使用MapReduce,对这些网页进行清洗,获取网页中的问题类型,标题,来信人,时间,网友评论数,信息内容,官方回答的机构,时间和回答的内容。
搭建解析框架
1.切换目录到/data/目录下,创建名为edu2的目录
- cd /data/
- mkdir /data/edu2
2.切换目录到/data/edu2目录下,使用wget命令,下载项目所依赖的lib包
- cd /data/edu2
将pachongjar.zip压缩包,解压缩。
- unzip
3.打开eclipse,新建Java Project
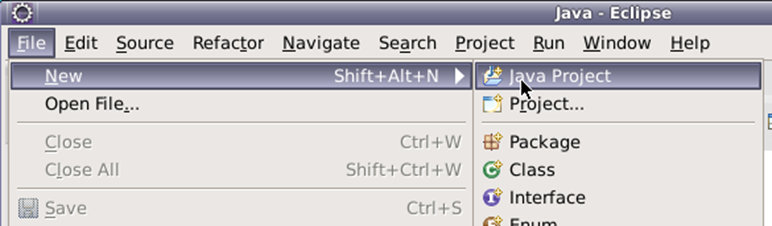
将项目命名为qingxi2
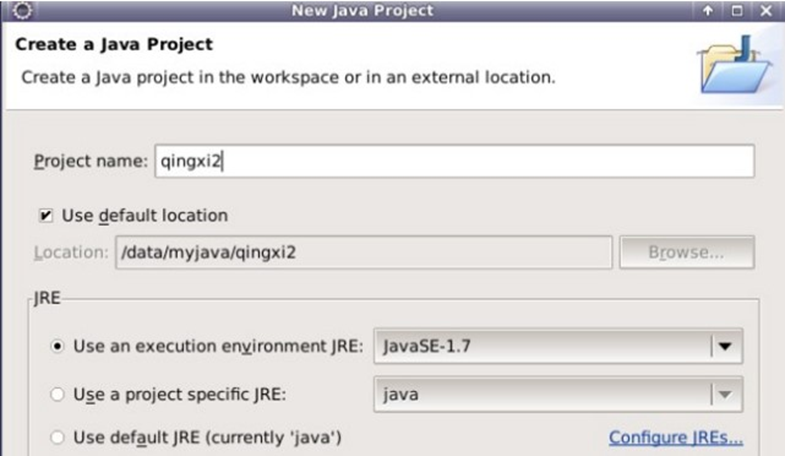
4.右键项目名,新建一个目录,命名为libs用于存储项目依赖的jar包
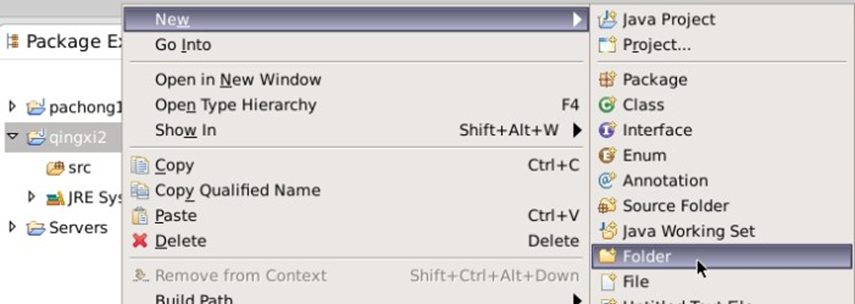
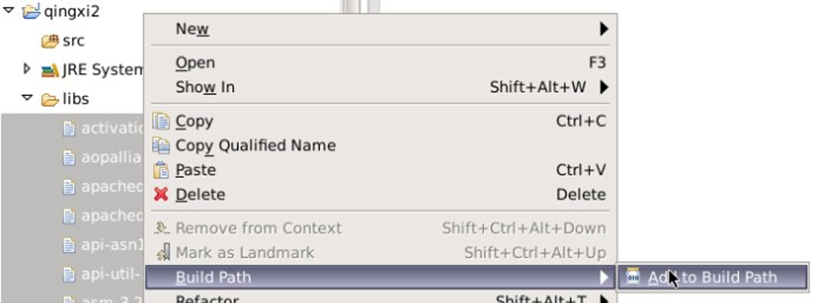
将/data/edu2/pachongjar目录下,所有的jar包,拷贝到项目下的libs目录下。
选中libs下,所有的jar文件,依次点击“Build Path” => "Add to Build Path"
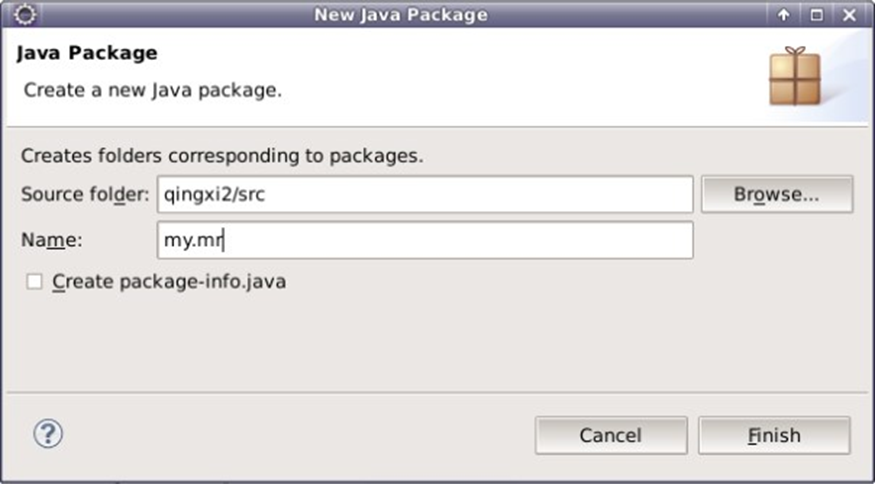
5.右键src,点击 "New" => "Package",新建一个包

将包命名为my.mr
右键包名,依次点击“New” => “Class”
填写类名,本实验需要创建三个类,分别命名为FileInput,FileRecordReader,QingxiHtml。
这样清洗过程的框架搭建完毕,下面开始编写代码实现功能。
编写MapReduce代码
1.执行jps,查看hadoop相关进程是否已经启动。
- jps
若未启动,则需启动hadoop
- cd /apps/hadoop/sbin
- ./start-all.sh
2.切换目录到/data/edu2目录下,使用wget命令,下载爬取到的北京市政府百姓信件内容。
- cd /data/edu2
- wget http://192.168.1.100:60000/allfiles/second/edu2/govhtml.tar.gz
将govhtml.tar.gz解压缩
- tar xzvf govhtml.tar.gz
在hdfs上创建目录,名为/myedu2,并将/data/edu2/govhtml下的数据,上传到hdfs中。
- hadoop fs -mkdir -p /myedu2/in
- hadoop fs -put /data/edu2/govhtml/* /myedu2/in
*此处也可以将自己爬取到的电商评论数据,上传到hdfs上。
3.(1) 打开FileRecordReader页面,编写代码,完成对网页源码的读取,主要目的是将一个网页的全部代码转成一行让mapreduce读取分析,这样mapreduce就可以把一个网页的分析结果作为一行输出,即每个网页抓取的字段为一行。
- package my.mr;
- import java.io.BufferedReader;
- import java.io.InputStreamReader;
- import java.io.IOException;
- import org.apache.hadoop.fs.FSDataInputStream;
- import org.apache.hadoop.fs.FileSystem;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.InputSplit;
- import org.apache.hadoop.mapreduce.JobContext;
- import org.apache.hadoop.mapreduce.RecordReader;
- import org.apache.hadoop.mapreduce.TaskAttemptContext;
- import org.apache.hadoop.mapreduce.lib.input.FileSplit;
- public class FileRecordReader extends RecordReader<text,text>{
- private FileSplit fileSplit;
- private JobContext jobContext;
- private Text currentKey = new Text();
- private Text currentValue = new Text();
- private boolean finishConverting = false;
- @Override
- public void close() throws IOException {
- @Override
- public Text getCurrentKey() throws IOException, InterruptedException {
- return currentKey;
- }
- @Override
- public Text getCurrentValue() throws IOException,
- InterruptedException {
- return currentValue;
- }
- @Override
- public float getProgress() throws IOException, InterruptedException {
- float progress = 0;
- if(finishConverting){
- progress = 1;
- }
- return progress;
- }
- @Override
- public void initialize(InputSplit arg0, TaskAttemptContext arg1)
- throws IOException, InterruptedException {
- this.fileSplit = (FileSplit) arg0;
- this.jobContext = arg1;
- String filename = fileSplit.getPath().getName();
- this.currentKey = new Text(filename);
- }
- @Override
- public boolean nextKeyValue() throws IOException, InterruptedException {
- if(!finishConverting){
- int len = (int)fileSplit.getLength();
- // byte[] content = new byte[len];
- Path file = fileSplit.getPath();
- FileSystem fs = file.getFileSystem(jobContext.getConfiguration());
- FSDataInputStream in = fs.open(file);
- //根据实际网页的编码格式修改
- // BufferedReader br = new BufferedReader(new InputStreamReader(in,"gbk"));
- BufferedReader br = new BufferedReader(new InputStreamReader(in,"utf-8"));
- String line="";
- String total="";
- while((line= br.readLine())!= null){
- total =total+line+"\n";
- }
- br.close();
- in.close();
- fs.close();
- currentValue = new Text(total);
- finishConverting = true;
- return true;
- }
- return false;
- }
- }
- </text,text>
(2)打开FileInput ,编写代码,用以调用FileRecordReader 中重写的方法。
- package my.mr;
- import java.io.IOException;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.InputSplit;
- import org.apache.hadoop.mapreduce.RecordReader;
- import org.apache.hadoop.mapreduce.TaskAttemptContext;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- public class FileInput extends FileInputFormat<Text,Text>{
- @Override
- public RecordReader<Text, Text> createRecordReader(InputSplit arg0, TaskAttemptContext arg1) throws IOException,
- InterruptedException {
- // TODO Auto-generated method stub
- RecordReader<Text,Text> recordReader = new FileRecordReader();
- return recordReader;
- }
- }
(3)打开QingxiHtml编写代码,代码所实现的需求,是使用MapReduce解析网页,最终输出格式化的文本文件。
首先来看MapReduce通用的框架结构样式。
- public class QingxiHtml {
- public static void main(String[] args) throws IOException,
- ClassNotFoundException, InterruptedException {
- }
- public static class doMapper extends Mapper<Object, Text, Text, Text> {
- @Override
- protected void map(Object key, Text value, Context context)
- throws IOException, InterruptedException {
- }
- }
- public static class doReducer extends Reducer<Text, Text, Text, Text>{
- @Override
- protected void reduce(Text key, Iterable<Text> values, Context context)
- throws IOException, InterruptedException {
- }
- }
- }
通过分析可以知道,此处只用Map任务即可实现具体功能,所以可以省去Reduce任务。
4.Main主函数。这里的main函数也是通用的结构
- public static void main(String[] args) throws IOException,
- ClassNotFoundException, InterruptedException {
- Job job = Job.getInstance();
- job.setJobName("QingxiHtml");
- job.setJarByClass(QingxiHtml.class);
- job.setMapperClass(doMapper.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(Text.class);
- job.setInputFormatClass(FileInput.class);
- Path in = new Path("hdfs://localhost:9000//myedu2/in");
- Path out = new Path("hdfs://localhost:9000//myedu2/out/1");
- FileInputFormat.addInputPath(job, in);
- FileOutputFormat.setOutputPath(job, out);
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- }
①定义Job
②设置Job参数
③设置Map任务
④设置Reduce任务
⑤定义任务的输出类型
⑥设置任务的输入输出目录
⑦提交执行
5.再来看Map任务,实现Map任务,必须继承org.apache.hadoop.mapreduce.Mapper类,并重写类里的map方法。
通过调用编写FileInput.class文件,将每个网页源码转化为一行字段输入。通过map任务,取得每行字段,并通过JXDocument 类,对网页源码进行解析,获取网页中的字段。
将相关字段以‘\t’分隔连接成一行,最终使用context.write类,输出到htfs上。
- @Override
- protected void map(Object key, Text value, Context context)
- throws IOException, InterruptedException {
- String htmlStr = value.toString();
- JXDocument Document = new JXDocument(htmlStr);
- if (htmlStr.indexOf("mail_track_h2") > 0) {
- try {
- //类型
- String leixing = Document
- .sel("//span[@class='font12 gray']/a[2]/text()")
- .get(0).toString();
- //标题
- String biaoti = Document
- .sel("//h2[@class='mail_track_h2']/text()").get(0)
- .toString();
- //来信人
- String leixinren = Document
- .sel("//p[@class='font12 gray time_mail']/span[1]/text()")
- .get(0).toString().replaceAll("来信人:", "");
- //时间
- String shijian = Document
- .sel("//p[@class='font12 gray time_mail']/span[2]/text()")
- .get(0).toString().replaceAll("时间:", "");
- //网友同问的数量或者网友评价的数量
- String number = Document
- .sel("//p[@class='font12 gray time_mail']/span[3]/allText()")
- .get(0).toString().replace("网友同问: ", "").replace("网友评价数: ", "");
- //信件内容
- String problem = Document
- .sel("//span[@class='font14 mail_problem']/text()")
- .get(0).toString();
- if (htmlStr.indexOf("margin-bottom:31px") > 0) {
- //回答部门
- String offic = Document
- .sel("//div[@class='con_left float_left']/div[2]/span[1]/text()")
- .get(0).toString();
- //回答时间
- String officpt = Document
- .sel("//div[@class='con_left float_left']/div[2]/span[2]/text()")
- .get(0).toString();
- //回答内容
- String officp = Document
- .sel("//div[@class='con_left float_left']/div[2]/p[1]/text()")
- .get(0).toString();
- String dataout = leixing + "\t" + biaoti + "\t"
- + leixinren + "\t" + shijian + "\t" + number
- + "\t" + problem + "\t" + offic + "\t"
- + officpt + "\t"+ officp;
- System.out.println(dataout);
- Text oneLines = new Text(dataout);
- context.write(oneLines, new Text(""));
- } else {
- String dataout = leixing + "\t" + biaoti + "\t"
- + leixinren + "\t" + shijian + "\t" + number
- + "\t" + problem;
- System.out.println(dataout);
- Text oneLines = new Text(dataout);
- context.write(oneLines, new Text(""));
- }
- } catch (XpathSyntaxErrorException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }
- }
- }
完整代码如下
- package my.mr;
- import java.io.IOException;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import cn.wanghaomiao.xpath.exception.XpathSyntaxErrorException;
- import cn.wanghaomiao.xpath.model.JXDocument;
- public class QingxiHtml {
- public static class doMapper extends Mapper<object, text,="" text=""> {
- public static final IntWritable one = new IntWritable(1);
- public static Text word = new Text();
- @Override
- protected void map(Object key, Text value, Context context)
- throws IOException, InterruptedException {
- String htmlStr = value.toString();
- JXDocument Document = new JXDocument(htmlStr);
- if (htmlStr.indexOf("mail_track_h2") > 0) {
- try {
- String leixing = Document
- .sel("//span[@class='font12 gray']/a[2]/text()")
- .get(0).toString();
- String biaoti = Document
- .sel("//h2[@class='mail_track_h2']/text()").get(0)
- .toString();
- String leixinren = Document
- .sel("//p[@class='font12 gray time_mail']/span[1]/text()")
- .get(0).toString().replaceAll("来信人:", "");
- String shijian = Document
- .sel("//p[@class='font12 gray time_mail']/span[2]/text()")
- .get(0).toString().replaceAll("时间:", "");
- String number = Document
- .sel("//p[@class='font12 gray time_mail']/span[3]/allText()")
- .get(0).toString().replace("网友同问: ", "").replace("网友评价数: ", "");
- String problem = Document
- .sel("//span[@class='font14 mail_problem']/text()")
- .get(0).toString();
- if (htmlStr.indexOf("margin-bottom:31px") > 0) {
- String offic = Document
- .sel("//div[@class='con_left float_left']/div[2]/span[1]/text()")
- .get(0).toString();
- String officpt = Document
- .sel("//div[@class='con_left float_left']/div[2]/span[2]/text()")
- .get(0).toString();
- String officp = Document
- .sel("//div[@class='con_left float_left']/div[2]/p[1]/text()")
- .get(0).toString();
- String dataout = leixing + "\t" + biaoti + "\t"
- + leixinren + "\t" + shijian + "\t" + number
- + "\t" + problem + "\t" + offic + "\t"
- + officpt + "\t"+ officp;
- System.out.println(dataout);
- Text oneLines = new Text(dataout);
- context.write(oneLines, new Text(""));
- } else {
- String dataout = leixing + "\t" + biaoti + "\t"
- + leixinren + "\t" + shijian + "\t" + number
- + "\t" + problem;
- System.out.println(dataout);
- Text oneLines = new Text(dataout);
- context.write(oneLines, new Text(""));
- }
- } catch (XpathSyntaxErrorException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }
- }
- }
- }
- public static void main(String[] args) throws IOException,
- ClassNotFoundException, InterruptedException {
- Job job = Job.getInstance();
- job.setJobName("QingxiHtml");
- job.setJarByClass(QingxiHtml.class);
- job.setMapperClass(doMapper.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(Text.class);
- job.setInputFormatClass(FileInput.class);
- Path in = new Path("hdfs://localhost:9000//myedu2/in");
- Path out = new Path("hdfs://localhost:9000//myedu2/out/1");
- FileInputFormat.addInputPath(job, in);
- FileOutputFormat.setOutputPath(job, out);
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- }
- }
- </object,>
执行测试
1.在mapreduce类中,右键,Run As => Run on Hadoop,将任务提交到hadoop中执行
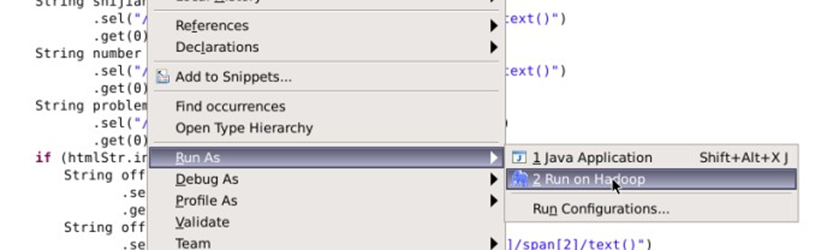
2.等待任务执行完毕。切换目录到/data/edu2/下,并在命令行界面,输入脚本,查看hdfs上/myedu2/out是否有内容输出
- cd /data/edu2/
- hadoop fs -lsr /myedu2/out
若有输出,则将hdfs输出内容,下载到linux本地
- hadoop fs -get /myedu2/out/1/*

使用vim或cat查看下载到的文件内容,可以看到结构比较清晰

3,若未在hdfs上,查看到输出结果,可以通过log日志排错。将/apps/hadoop/etc/hadoop/log4j.properties文件,拷贝到mapreduce项目的根目录下
可以看到在eclipse的console界面有执行过程的输出。
所以需要清洗的数据清洗完成,部分不需要清洗的数据不必清洗可以直接用,最后整合并归类数据,以及数据的分析和图形展示。
