实验一:Spark Java API&Spark Scala API操作
实验一:Spark Java API&Spark Scala API操作
实验说明:
1、 本次实验是第一次上机,属于验证性实验。实验报告上交截止日期为2023年2月26日上午12点之前。
2、 实验报告命名为:信2005-1班学号姓名实验一.doc。
实验环境:
操作系统: Ubuntu16.04;
Spark 版本: 2.1.0;
Hadoop 版本: 2.7.1。
实验目的:
1.了解Scala语言的基本语法
2.了解Spark Scala开发的原理
3.了解Spark Java API的使用
4.了解Spark的Scala API及Java API对数据处理的不同点
实验原理:
Spark的核心就是RDD,所有在RDD上的操作会被运行在Cluster上,Driver程序启动很多Workers,Workers在(分布式)文件系统中读取数据后转化为RDD(弹性分布式数据集),然后对RDD在内存中进行缓存和计算。
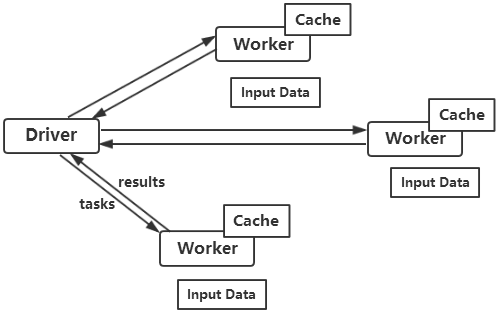
对于Spark中的API来说,它支持的语言有Scala、Java和Python,由于Scala是Spark的原生语言,各种新特性肯定是Scala最先支持的,Scala语言的优势在于语法丰富且代码简洁,开发效率高。缺点在于Scala的API符号标记复杂,某些语法太过复杂,不易上手。对Java开发者而言,也可以使用Spark Java API。
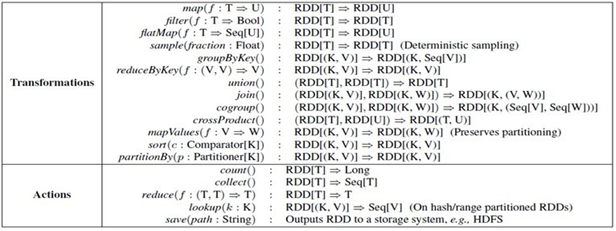
RDD有两种类型的操作 ,分别是Action(返回values)和Transformations(返回一个新的RDD)。
实验内容与要求:
某电商网站记录了大量用户对商品的收藏数据,并将数据存储在名为buyer_favorite1的文件中,数据格式以及数据内容如下:
用户ID(buyer_id),商品ID(goods_id),收藏日期(dt)
- 用户id 商品id 收藏日期
- 10181 1000481 2010-04-04 16:54:31
- 20001 1001597 2010-04-07 15:07:52
- 20001 1001560 2010-04-07 15:08:27
- 20042 1001368 2010-04-08 08:20:30
- 20067 1002061 2010-04-08 16:45:33
- 20056 1003289 2010-04-12 10:50:55
- 20056 1003290 2010-04-12 11:57:35
- 20056 1003292 2010-04-12 12:05:29
- 20054 1002420 2010-04-14 15:24:12
- 20055 1001679 2010-04-14 19:46:04
- 20054 1010675 2010-04-14 15:23:53
- 20054 1002429 2010-04-14 17:52:45
- 20076 1002427 2010-04-14 19:35:39
- 20054 1003326 2010-04-20 12:54:44
- 20056 1002420 2010-04-15 11:24:49
- 20064 1002422 2010-04-15 11:35:54
- 20056 1003066 2010-04-15 11:43:01
- 20056 1003055 2010-04-15 11:43:06
- 20056 1010183 2010-04-15 11:45:24
- 20056 1002422 2010-04-15 11:45:49
- 20056 1003100 2010-04-15 11:45:54
- 20056 1003094 2010-04-15 11:45:57
- 20056 1003064 2010-04-15 11:46:04
- 20056 1010178 2010-04-15 16:15:20
- 20076 1003101 2010-04-15 16:37:27
- 20076 1003103 2010-04-15 16:37:05
- 20076 1003100 2010-04-15 16:37:18
- 20076 1003066 2010-04-15 16:37:31
- 20054 1003103 2010-04-15 16:40:14
- 20054 1003100 2010-04-15 16:40:16
现分别使用Spark Scala API及Spark Java API对用户收藏数据,进行wordcount操作,统计每个用户收藏商品数量。
实验步骤:
1.在Linux上创建/data/spark4目录,用于存储实验所需的数据。
- mkdir -p /data/spark4
切换到/data/spark4目录下,并从下载实验数据buyer_favorite1(自行生成)及spark-assembly-1.6.0-hadoop2.6.0.jar。
- cd /data/spark4
- wget http://192.168.1.100:60000/allfiles/spark4/buyer_favorite1
- wget http://192.168.1.100:60000/allfiles/spark4/spark-assembly-1.6.0-hadoop2.6.0.jar
2.使用jps查看Hadoop以及Spark的相关进程是否已经启动,若未启动则执行启动命令。
- jps
- /apps/hadoop/sbin/start-all.sh
- /apps/spark/sbin/start-all.sh
将Linux本地/data/spark4/buyer_favorite文件,上传到HDFS上的/myspark4目录下。若HDFS上/myspark4目录不存在则创建。
- hadoop fs -mkdir -p /myspark4
- hadoop fs -put /data/spark4/buyer_favorite1 /myspark4
3.打开已安装完Scala插件的Eclipse,新建一个Scala项目。
将项目命名为spark4。
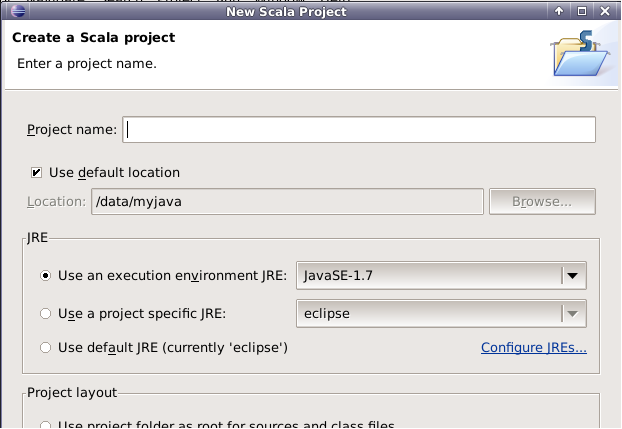
在spark4项目下新建包名,命名为my.scala。
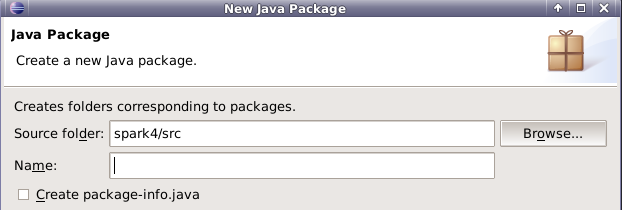
右键点击包名, 新建scala Object。
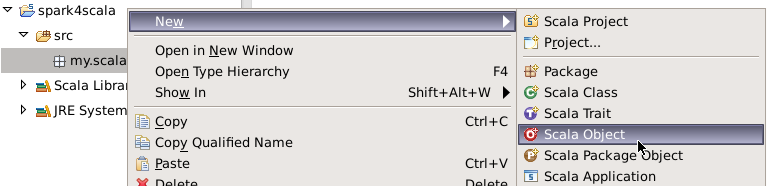
将scala object命名为ScalaWordCount。
4.右键项目,创建一个文件夹,名为lib。
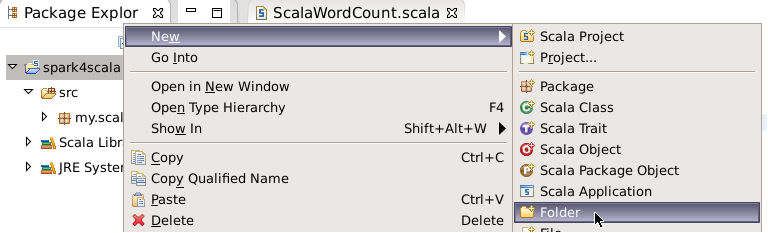
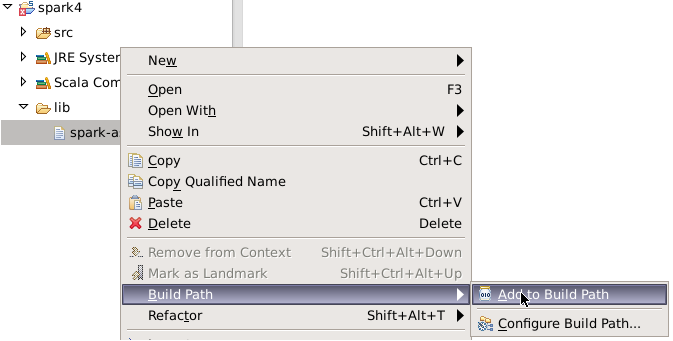
将Linux上的/data/spark4/spark-assembly-1.6.0-hadoop2.6.0.jar文件,拷贝到lib目录下。右键jar包,点击Build Path=>Add to Build Path。
5.在Eclipse中,打开ScalaWordCount.scala文件。编写Scala语句,并统计用户收藏数据中,每个用户收藏商品数量。
- package my.scala
- import org.apache.spark.SparkConf
- import org.apache.spark.SparkContext
- object ScalaWordCount {
- def main(args: Array[String]) {
- val conf = new SparkConf()
- conf.setMaster("local")
- .setAppName("scalawordcount")
- val sc = new SparkContext(conf)
- val rdd = sc.textFile("hdfs://localhost:9000/myspark4/buyer_favorite1")
- rdd.map(line => (line.split("\t")(0), 1))
- .reduceByKey(_ + _)
- .collect()
- .foreach(println)
- sc.stop()
- }
- }
第一步:创建Spark的配置对象sparkConf,设置Spark程序运行时的配置信息;
第二步:创建SparkContext对象,SparkContext是Spark程序所有功能的唯一入口,无论采用Scala、Java还是Python都必须有一个SparkContext;
第三步:根据具体的数据来源,通过SparkContext来创建RDD;
第四步:对初始的RDD进行Transformation级别的处理。(首先将每一行的字符串拆分成单个的单词,然后在单词拆分的基础上对每个单词实例计数为1;最后,在每个单词实例计数为1的基础上统计每个单词在文件出现的总次数)。
6.在Eclipse中执行代码

在控制界面console中查看的输出结果。
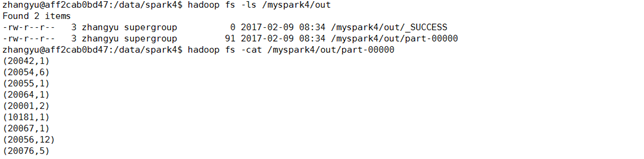
- (用户id 收藏商品数量)
- (20042,1)
- (20054,6)
- (20055,1)
- (20064,1)
- (20001,2)
- (10181,1)
- (20067,1)
- (20056,12)
- (20076,5)
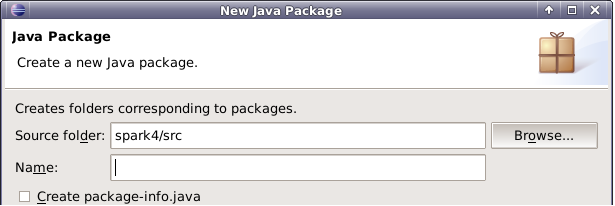
7.再次右键点击项目名,新建package,将包命名为my.java 。
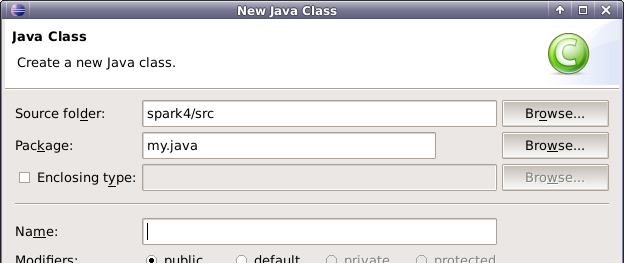
右键点击包my.java,新建Class,命名为JavaWordCount。
8.打开JavaWordCount.java文件,编写Java代码,统计用户收藏数据中,每个用户收藏商品数量。
- package my.java;
- import org.apache.spark.SparkConf;
- import org.apache.spark.api.java.JavaPairRDD;
- import org.apache.spark.api.java.JavaRDD;
- import org.apache.spark.api.java.JavaSparkContext;
- import org.apache.spark.api.java.function.FlatMapFunction;
- import org.apache.spark.api.java.function.Function2;
- import org.apache.spark.api.java.function.PairFunction;
- import scala.Tuple2;
- import java.util.Arrays;
- import java.util.List;
- import java.util.regex.Pattern;
- public final class JavaWordCount {
- private static final Pattern SPACE = Pattern.compile("\t");
- public static void main(String[] args) throws Exception {
- SparkConf sparkConf = new SparkConf().setMaster("local").setAppName("JavaWordCount");
- JavaSparkContext ctx = new JavaSparkContext(sparkConf);
- JavaRDD<String> lines = ctx.textFile("hdfs://localhost:9000/myspark4/buyer_favorite1");
- JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
- @Override
- public Iterable<String> call(String s) {
- String word[]=s.split("\t",2);
- return Arrays.asList(word[0]);
- }
- });
- JavaPairRDD<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {
- @Override
- public Tuple2<String, Integer> call(String s) {
- return new Tuple2<String, Integer>(s, 1);
- }
- });
- JavaPairRDD<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() {
- @Override
- public Integer call(Integer i1, Integer i2) {
- return i1 + i2;
- }
- });
- List<Tuple2<String, Integer>> output = counts.collect();
- System.out.println(counts.collect());
- counts.saveAsTextFile("hdfs://localhost:9000/myspark4/out");
- ctx.stop();
- }
- }
9.在Eclipse上执行Java代码,并在Java代码指定输出目录下查看实验结果。
- hadoop fs -ls /myspark4/out
- hadoop fs -cat /myspark4/out/part-00000