


Pytorch nn.Linear的基本用法与原理详解
Pytorch nn.Linear的基本用法与原理详解
原文:Pytorch nn.Linear的基本用法与原理详解_iioSnail的博客-CSDN博客
nn.Linear的基本定义
nn.Linear定义一个神经网络的线性层,方法签名如下:
torch.nn.Linear(in_features, # 输入的神经元个数 out_features, # 输出神经元个数 bias=True # 是否包含偏置 )
Linear其实就是对输入
其中
使用演示:
from torch import nn import torch model = nn.Linear(2, 1) # 输入特征数为2,输出特征数为1 input = torch.Tensor([1, 2]) # 给一个样本,该样本有2个特征(这两个特征的值分别为1和2) output = model(input) output tensor([-1.4166], grad_fn=<AddBackward0>)
我们的输入为[1,2],输出了[-1.4166]。可以查看模型参数验证一下上述的式子:
# 查看模型参数 for param in model.parameters(): print(param) Parameter containing: tensor([[ 0.1098, -0.5404]], requires_grad=True) Parameter containing: tensor([-0.4456], requires_grad=True)
可以看到,模型有3个参数,分别为两个权重和一个偏执。计算可得:
实战
假设我们的一次输入三个样本A,B,C(即batch_size为3),每个样本的特征数量为5:
A: [0.1,0.2,0.3,0.3,0.3] B: [0.4,0.5,0.6,0.6,0.6] C: [0.7,0.8,0.9,0.9,0.9]
则我们的输入向量
X = torch.Tensor([ [0.1,0.2,0.3,0.3,0.3], [0.4,0.5,0.6,0.6,0.6], [0.7,0.8,0.9,0.9,0.9], ]) X
tensor([[0.1000, 0.2000, 0.3000, 0.3000, 0.3000], [0.4000, 0.5000, 0.6000, 0.6000, 0.6000], [0.7000, 0.8000, 0.9000, 0.9000, 0.9000]])
定义线性层, 我们的输入特征为5,所以 in_feature=5,我们想让下一层的神经元个数为10,所以 out feature=10, 则模型参数为:
model = nn.Linear(in_features=5, out_features=10, bias=True)
经过线性层,其实就是做了一件事,即:
具体表示则为:
其中
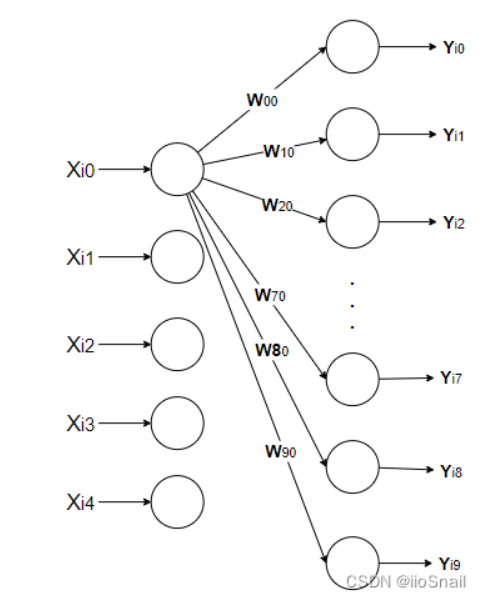
注意: 这里图有点问题, 应该是
因为有三个样本,所以相当于依次进行了三次
model(X).size() # torch.Size([3, 10])
Pytorch版本线性回归模型
import torch from torch import nn from torch import optim import numpy as np from matplotlib import pyplot as plt # 1. 定义数据 x = torch.rand([50,1]) y = x*3 + 0.8 #2 .定义模型 class Lr(nn.Module): def __init__(self): super(Lr,self).__init__() # 因为简单的一维线性回归x的特征只有1,我们要预测的y也只有一个特征 self.linear = nn.Linear(1,1) # 定义前向传播过程 def forward(self, x): out = self.linear(x) return out # 2. 实例化模型,loss,和优化器 model = Lr() criterion = nn.MSELoss() optimizer = optim.SGD(model.parameters(), lr=1e-3) #3. 训练模型 for i in range(30000): out = model(x) #3.1 获取预测值 loss = criterion(y,out) #3.2 计算损失 optimizer.zero_grad() #3.3 梯度归零 loss.backward() #3.4 计算梯度 optimizer.step() # 3.5 更新梯度 if (i+1) % 20 == 0: print('Epoch[{}/{}], loss: {:.6f}'.format(i,30000,loss.data)) #4. 模型评估 model.eval() #设置模型为评估模式,即预测模式 predict = model(x) predict = predict.data.numpy() plt.scatter(x.data.numpy(),y.data.numpy(),c="r") plt.plot(x.data.numpy(),predict) plt.show()


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本