
Python Map、Filter、reduce、zip、enumerate
1、Map
Map会将⼀个函数映射到⼀个输⼊列表的所有元素上。
map(function_to_apply, list_of_inputs)
普通方法:
items=[1, 2, 3, 4, 5]
squared=[]
for i in items:
squared.append(i**2)
map方法
items = [1, 2, 3, 4, 5]
squared = list(map(lambda x: x ** 2, items))
map不尽可以参数list_of_inputs用于参数输入,还可以用于函数输入!
def multiply(x):
return (x * x)
def add(x):
return (x + x)
funcs = [multiply, add]
for i in range(5):
value = list(map(lambda x: x(i), funcs))
print(value)
2、Filter
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
filter(function, iterable)
-
function -- 判断函数。
-
iterable -- 可迭代对象。
#过滤出列表中的所有奇数 #!/usr/bin/python3 def is_odd(n): return n % 2 == 1 tmplist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) newlist = list(tmplist) print(newlist) #[1, 3, 5, 7, 9]
3、reduce
reduce的工作过程是 :在迭代序列的过程中,首先把 前两个元素(只能两个)传给 函数,函数加工后,然后把 得到的结果和第三个元素 作为两个参数传给函数参数, 函数加工后得到的结果又和第四个元素 作为两个参数传给函数参数,依次类推。
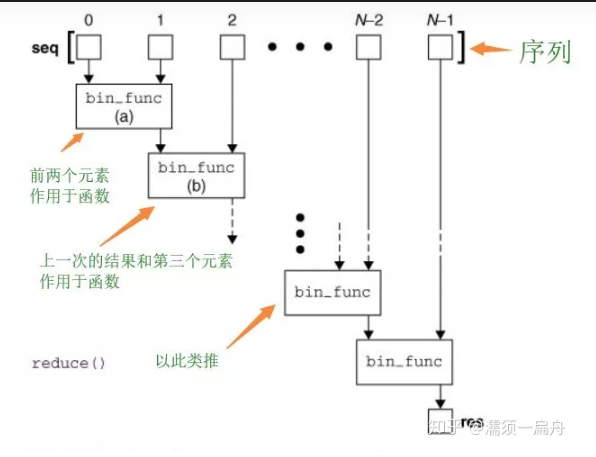
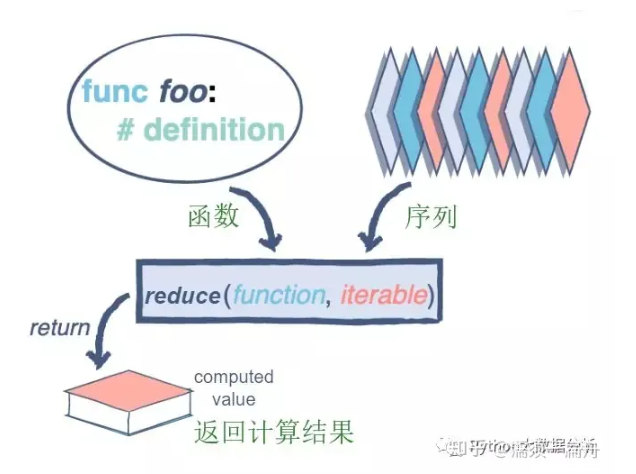
reduce(function, iterable[, initializer])
- function:代表函数
- iterable:序列
- initializer:初始值(可选)
# 导入reduce
from functools import reduce
# 定义函数
def f(x,y):
return x*y
# 定义序列,含1~10的元素
items = range(1,11)
# 使用reduce方法
result = reduce(f,items)
print(result)
4、zip
4.1 zip()函数
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用*号操作符,可以将元组解压为列表。
*zip 方法在 Python 2 和 Python 3 中的不同:在 Python 3.x 中为了减少内存,zip() 返回的是一个对象。如需展示列表,需手动 list() 转换;如需展示字典,需手动 dict() 转换。
语法
zip([iterable, ...])
参数说明:iterable(一个或多个迭代器)
返回值
- 返回元祖列表
实例
# 定义三个列表
a = [1, 2, 3]
b = [4, 5, 6]
c = [4, 5, 6, 7, 8]
# 打包为元组的列表,而且元素个数与最短的列表一致
a_b = zip(a, b)
# 输出zip函数的返回对象类型
print("a_b类型%s" % type(a_b))
# 输出a_b
print(list(a_b)) #[(1, 4), (2, 5), (3, 6)]
print(dict(a_b)) # {1: 4, 2: 5, 3: 6}
# 输出a_b
print(list(a_c)) # [(1, 4), (2, 5), (3, 6)],以短的为准
4.2 zip(*zipped)
zip(*zipped)中的 *zipped参数,可以list数组,也可以是zip()函数返回的对象。
可以理解为,zip是连接组合多个可迭代对象。zip(*)是讲迭代对象内部多个元素组合。
# 声明一个列表
nums = [['a1', 'a2', 'a3'], ['b1', 'b2', 'b3']]
# 参数为list数组时,是压缩数据,相当于zip()函数
iters = zip(*nums)
# 输出zip(*zipped)函数返回对象的类型
print("type of iters is %s" % type(iters))
# 因为zip(*zipped)函数返回一个zip类型对象,所以我们需要对其进行转换
# 在这里,我们将其转换为字典
print(dict(iters))#{'a1': 'b1', 'a2': 'b2', 'a3': 'b3'}
5、enumerate
enumerate(iteration, start)函数默认包含两个参数,其中iteration参数为需要遍历的参数,比如字典、列表、元组等,start参数为开始的参数,默认为0(不写start那就是从0开始)。enumerate函数有两个返回值,第一个返回值为从start参数开始的数,第二个参数为iteration参数中的值。
enumerate(sequence, [start=0])
- sequence -- 一个序列、迭代器或其他支持迭代对象。
- start -- 下标起始位置的值。
>>> seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons, start=1)) # 下标从 1 开始
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
seq = ['one', 'two', 'three']
for i, element in enumerate(seq):
print(i,element)
0 one
1 two
2 three

 浙公网安备 33010602011771号
浙公网安备 33010602011771号