python爬取博客园信息用于归档--excel篇
之所以要写代码进行爬取,是因为我太懒了,呜呜呜,如果能天天躺着刷手机谁会打代码~~
今天上午归档的时候归了半个多小时我就不想归档了,就在图书馆摸鱼,摸着摸着就萌生了写爬虫的想法;
下面介绍一下这个爬虫
1.导入库
第一步就是导入所需要的库 equests, xlwt,BeautifulSoup,urllib.request,这些库包含了爬虫的解析库,还有excel的操作库,可以pip进行安装。
import requests, xlwt from bs4 import BeautifulSoup import urllib.request
2.建立存储容器
url_list1 = [] # 用于存放标题和url url_list2 = [] #用于存放日期 url_list3 = [] #用于存放详情界面
3.进行列表界面的爬取,列表界面可以爬取题目,链接,日期。这次写爬虫有一个深刻教训,爬取内容尽量在一个div里边进行爬取,起初题目和时间不在一个div里边,导致爬的题目和日期数目对不上位,一个错误卡了我两个小时。
在定义爬取页数的时候,要从1开始进行爬,因为博客园它并不是直接就到了列表页,我们操作博客园是首页中点击下一页才会有列表页。所以如果从0开始爬是会首页爬一次,列表页第一页爬一次,就一定会重复的所以我们爬的时候要range(1:)
还有就是word文件导不出来的问题,研究之后发现是因为word命名格式不支持最起初的命名方法,所以我改变了一下爬取的路径,换了一个word命名支持的string,就ok了。还有就是在word文件导不出来的时候 ,建议把模板文件和excel文件打开的状态下run。
# 获取列表页中的所有博客url,标题,链接,日期; def get_url(html): soup = BeautifulSoup(html, 'lxml') # lxml是解析方式,第三方库 blog_url_list1 = soup.find_all('div', class_='postTitle') for i in blog_url_list1: url_list1.append([i.find('a').text, i.find('a')['href']]) #获取列表日期,时间 blog_url_list2 = soup.find_all('div', class_='postDesc') for i in blog_url_list2: s = i.text[9:19] # print(s) url_list2.append(s) #开始爬取 for page in range(1, 10): #定义要爬取的页面数 url = 'http://www.cnblogs.com/linmob/default.html?page={}'.format(page) # print(url) get_url(get_content(url))
4.详情页进行详细内容的爬取
#详情页中内容进行分步爬取 lens = len(url_list1) for j in range(0, lens): url=url_list1[j][1] req=urllib.request.Request(url) resp=urllib.request.urlopen(req) html_page=resp.read().decode('utf-8') soup=BeautifulSoup(html_page,'html.parser') #print(soup.prettify()) div=soup.find(id="cnblogs_post_body") url_list3.append([div.get_text()])
5.生成表格
newTable = '韩佳作.xls' #生成的excel名称 wb = xlwt.Workbook(encoding='utf-8') # 打开一个对象 ws = wb.add_sheet('blog') # 添加一个sheet headData = ['博客标题', '链接','时间','详细内容'] # 写标题 for colnum in range(0, 4): #定义的四列名称 ws.write(0, colnum, headData[colnum], xlwt.easyxf('font:bold on')) # 第0行的第colnum列写入数据headDtata[colnum],就是表头,加粗 index = 1 #lens = len(url_list1) # 写内容 # print(len(url_list1),len(url_list2)) print(url_list2) for j in range(0, lens): ws.write(index, 0, url_list1[j][0]) ws.write(index, 1, url_list1[j][1]) ws.write(index, 2, url_list2[j]) ws.write(index, 3, url_list3[j][0]) index += 1 # 下一行 wb.save(newTable) # 保存
完整代码
import requests, xlwt from bs4 import BeautifulSoup import urllib.request url_list1 = [] # 用于存放标题和url url_list2 = [] #用于存放日期 url_list3 = [] #用于存放详情界面 # 获取源码 def get_content(url): html = requests.get(url).content return html # 获取列表页中的所有博客url,标题,链接,日期; def get_url(html): soup = BeautifulSoup(html, 'lxml') # lxml是解析方式,第三方库 blog_url_list1 = soup.find_all('div', class_='postTitle') for i in blog_url_list1: url_list1.append([i.find('a').text, i.find('a')['href']]) #获取列表日期,时间 blog_url_list2 = soup.find_all('div', class_='postDesc') for i in blog_url_list2: s = i.text[9:19] # print(s) url_list2.append(s) #开始爬取 for page in range(1, 10): #定义要爬取的页面数 url = 'http://www.cnblogs.com/linmob/default.html?page={}'.format(page) # print(url) get_url(get_content(url)) #详情页中内容进行分步爬取 lens = len(url_list1) for j in range(0, lens): url=url_list1[j][1] req=urllib.request.Request(url) resp=urllib.request.urlopen(req) html_page=resp.read().decode('utf-8') soup=BeautifulSoup(html_page,'html.parser') #print(soup.prettify()) div=soup.find(id="cnblogs_post_body") url_list3.append([div.get_text()]) newTable = '韩佳作.xls' #生成的excel名称 wb = xlwt.Workbook(encoding='utf-8') # 打开一个对象 ws = wb.add_sheet('blog') # 添加一个sheet headData = ['博客标题', '链接','时间','详细内容'] # 写标题 for colnum in range(0, 4): #定义的四列名称 ws.write(0, colnum, headData[colnum], xlwt.easyxf('font:bold on')) # 第0行的第colnum列写入数据headDtata[colnum],就是表头,加粗 index = 1 #lens = len(url_list1) # 写内容 # print(len(url_list1),len(url_list2)) print(url_list2) for j in range(0, lens): ws.write(index, 0, url_list1[j][0]) ws.write(index, 1, url_list1[j][1]) ws.write(index, 2, url_list2[j]) ws.write(index, 3, url_list3[j][0]) index += 1 # 下一行 wb.save(newTable) # 保存
懒还是第一生产力啊,同时希望我在接下来的概率论和毛概考试起飞~~~~
最后的效果图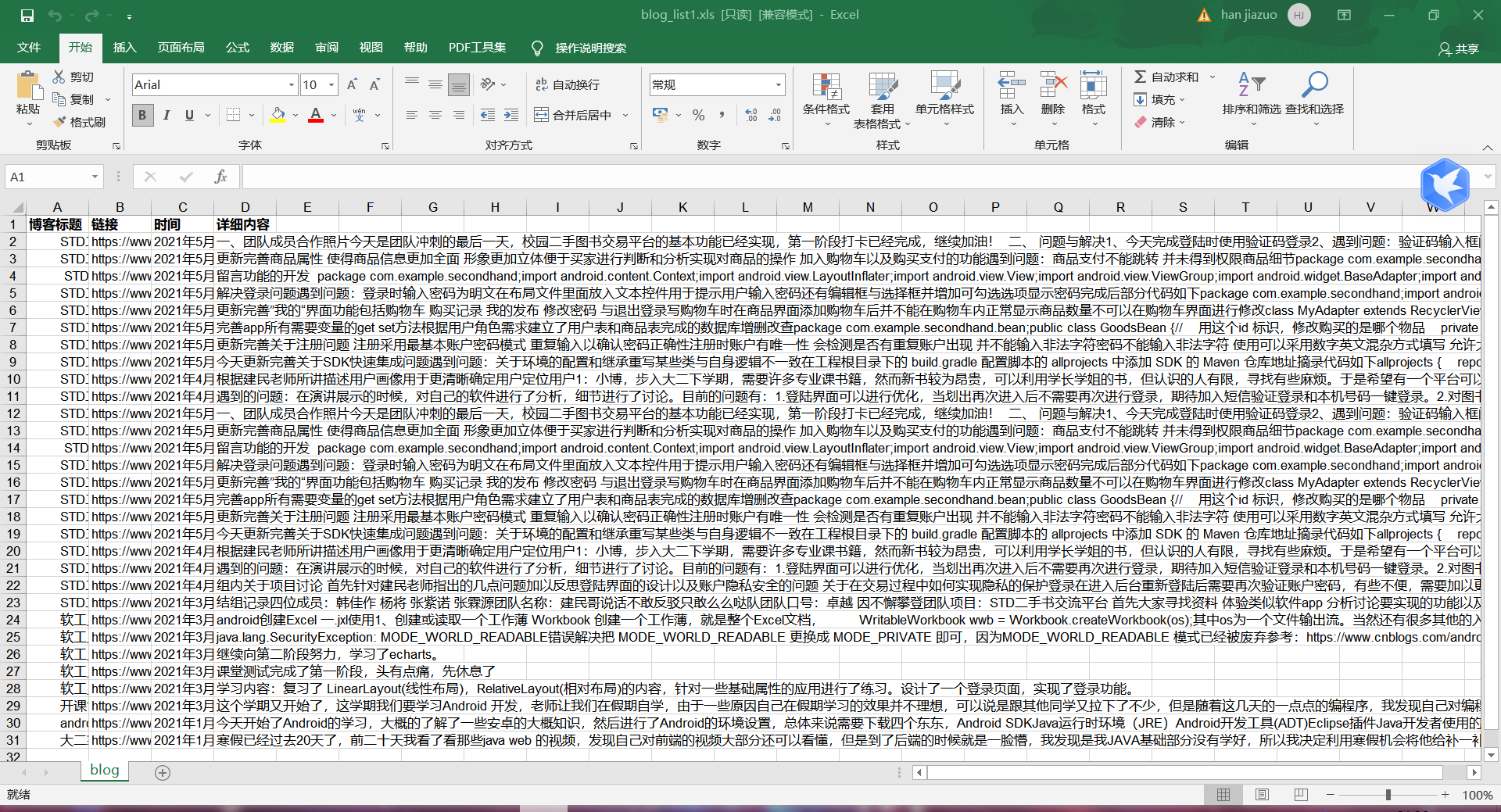

 浙公网安备 33010602011771号
浙公网安备 33010602011771号