记录一则enq: TX - row lock contention的分析过程
2018-03-23 04:18 AlfredZhao 阅读(2750) 评论(0) 收藏 举报故障描述:与客户沟通,初步确认故障范围大概是在上午的8:30-10:30之间,反应故障现象是Tomcat的连接数满导致应用无法连接,数据库alert中无明显报错,需要协助排查原因。
1.导入包含故障时刻的数据
为了便于后续分析,我向客户索要了从昨天下午13:00到今天18:00的awrdump,导入到自己的实验环境进行分析。生产环境导出awrdump:
@?/rdbms/admin/awrextr
测试环境导入awrdump:
SYS@jyzhao1 >select * from dba_directories;
SYS@jyzhao1 >create directory jy as '/home/oracle/awrdump';
SYS@jyzhao1 >select * from dba_directories;
SYS@jyzhao1 >!mkdir -p /home/oracle/awrdump
SYS@jyzhao1 >@?/rdbms/admin/awrload
省略部分输出..
... Dropping AWR_STAGE user
End of AWR Load
2.创建m_ash表,明确故障时刻
创建m_ash表:--create table
create table m_ash20180322 as select * from dba_hist_active_sess_history where dbid=&dbid;
输入生产库对应的dbid,完成创建分析表。
select to_char(sample_time, 'yyyy-mm-dd hh24:mi'), count(1)
FROM m_ash20180322
group by to_char(sample_time, 'yyyy-mm-dd hh24:mi')
order by 1;
根据生成的数据生成折线图如下:
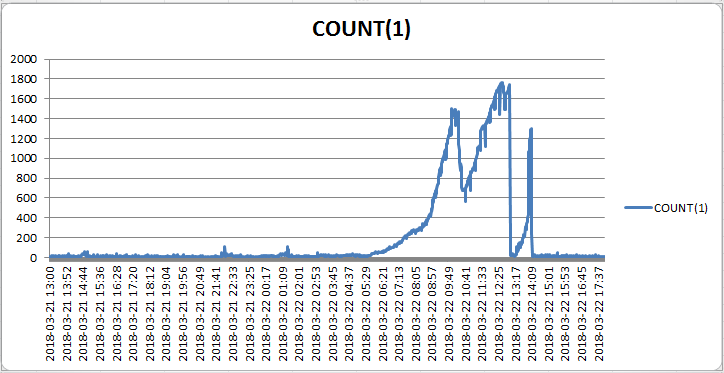
可以从图中明确故障时刻,即在10:00、12:30、14:10这三个时刻会话都明显上升(积压),看来客户的反馈时间点并没有包含所有异常时刻。
另外,引用下maclean的诊断脚本,可以看到核心意思差不多,只是进一步将instance_number区分开细化:
--验证导出的ASH时间范围:
select
t.dbid, t.instance_number, min(sample_time), max(sample_time), count(*) session_count
from m_ash20180322 t
group by t.dbid, t.instance_number
order by dbid, instance_number;
--确认问题发生的精确时间范围:
select
dbid, instance_number, sample_id, sample_time, count(*) session_count
from m_ash20180322 t
group by dbid, instance_number, sample_id, sample_time
order by dbid, instance_number, sample_time;
3.确定异常时刻的top n event
确定每个采样点的top n event,下面也是参考maclean的脚本。 比如我这里以2018-03-22 09:59:00 - 2018-03-22 10:00:00为例:select t.dbid,
t.sample_id,
t.sample_time,
t.instance_number,
t.event,
t.session_state,
t.c session_count
from (select t.*,
rank() over(partition by dbid, instance_number, sample_time order by c desc) r
from (select /*+ parallel 8 */
t.*,
count(*) over(partition by dbid, instance_number, sample_time, event) c,
row_number() over(partition by dbid, instance_number, sample_time, event order by 1) r1
from dba_hist_active_sess_history t
where sample_time >
to_timestamp('2018-03-22 09:59:00',
'yyyy-mm-dd hh24:mi:ss')
and sample_time <
to_timestamp('2018-03-22 10:00:00',
'yyyy-mm-dd hh24:mi:ss')
) t
where r1 = 1) t
where r < 3
order by dbid, instance_number, sample_time, r;

其他异常时刻,输入对应的变量值:
select t.dbid,
t.sample_id,
t.sample_time,
t.instance_number,
t.event,
t.session_state,
t.c session_count
from (select t.*,
rank() over(partition by dbid, instance_number, sample_time order by c desc) r
from (select /*+ parallel 8 */
t.*,
count(*) over(partition by dbid, instance_number, sample_time, event) c,
row_number() over(partition by dbid, instance_number, sample_time, event order by 1) r1
from dba_hist_active_sess_history t
where sample_time >
to_timestamp('&begin_sample_time',
'yyyy-mm-dd hh24:mi:ss')
and sample_time <
to_timestamp('&end_sample_time',
'yyyy-mm-dd hh24:mi:ss')
) t
where r1 = 1) t
where r < 3
order by dbid, instance_number, sample_time, r;
2018-03-22 12:29:00
2018-03-22 12:30:00

2018-03-22 14:09:00
2018-03-22 14:10:00
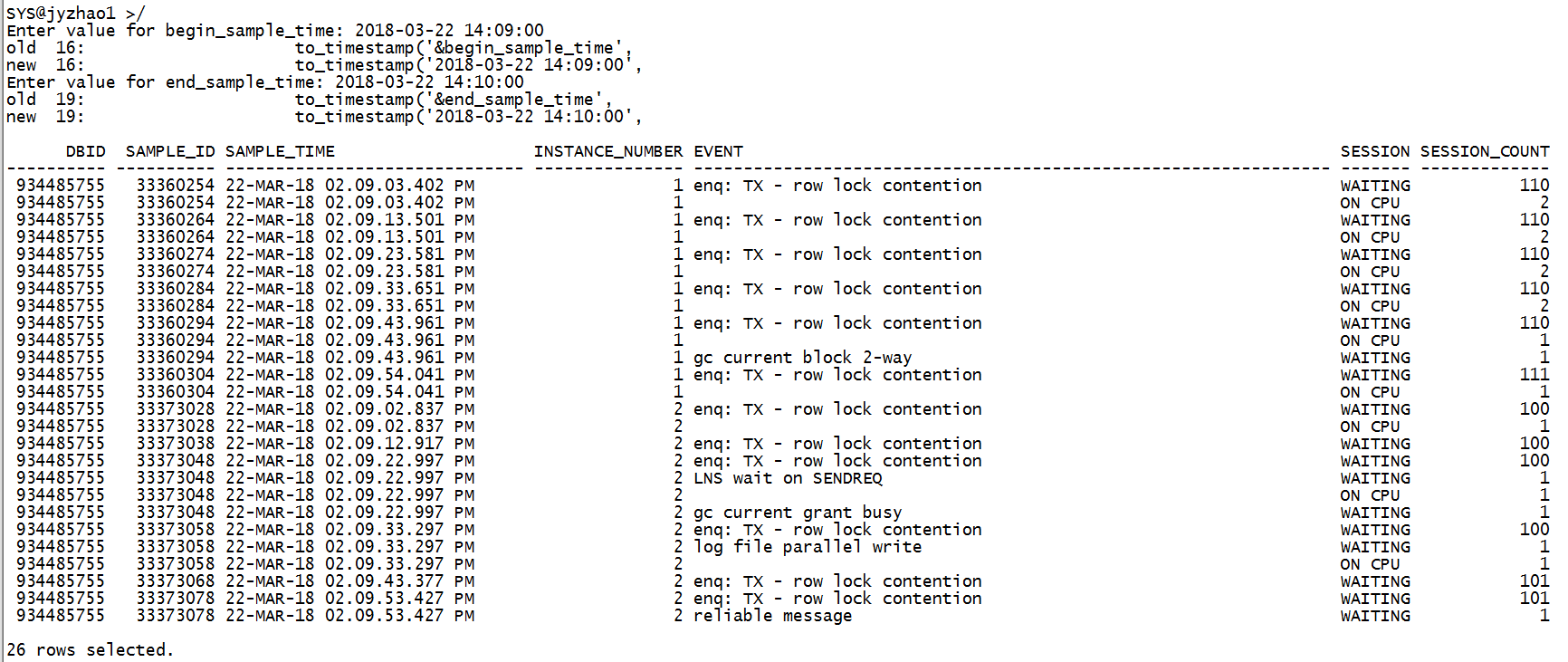
综上,3个连接数堆积的异常时刻TOP event都是 “enq: TX - row lock contention”。
4.确定最终的top holder
使用maclean的脚本,观察每个采样点的等待链:select
level lv,
connect_by_isleaf isleaf,
connect_by_iscycle iscycle,
t.dbid,
t.sample_id,
t.sample_time,
t.instance_number,
t.session_id,
t.sql_id,
t.session_type,
t.event,
t.session_state,
t.blocking_inst_id,
t.blocking_session,
t.blocking_session_status
from m_ash20180322 t
where sample_time >
to_timestamp('2018-03-22 09:59:00',
'yyyy-mm-dd hh24:mi:ss')
and sample_time <
to_timestamp('2018-03-22 10:00:00',
'yyyy-mm-dd hh24:mi:ss')
start with blocking_session is not null
connect by nocycle
prior dbid = dbid
and prior sample_time = sample_time
/*and ((prior sample_time) - sample_time between interval '-1'
second and interval '1' second)*/
and prior blocking_inst_id = instance_number
and prior blocking_session = session_id
and prior blocking_session_serial# = session_serial#
order siblings by dbid, sample_time;
结果如下:
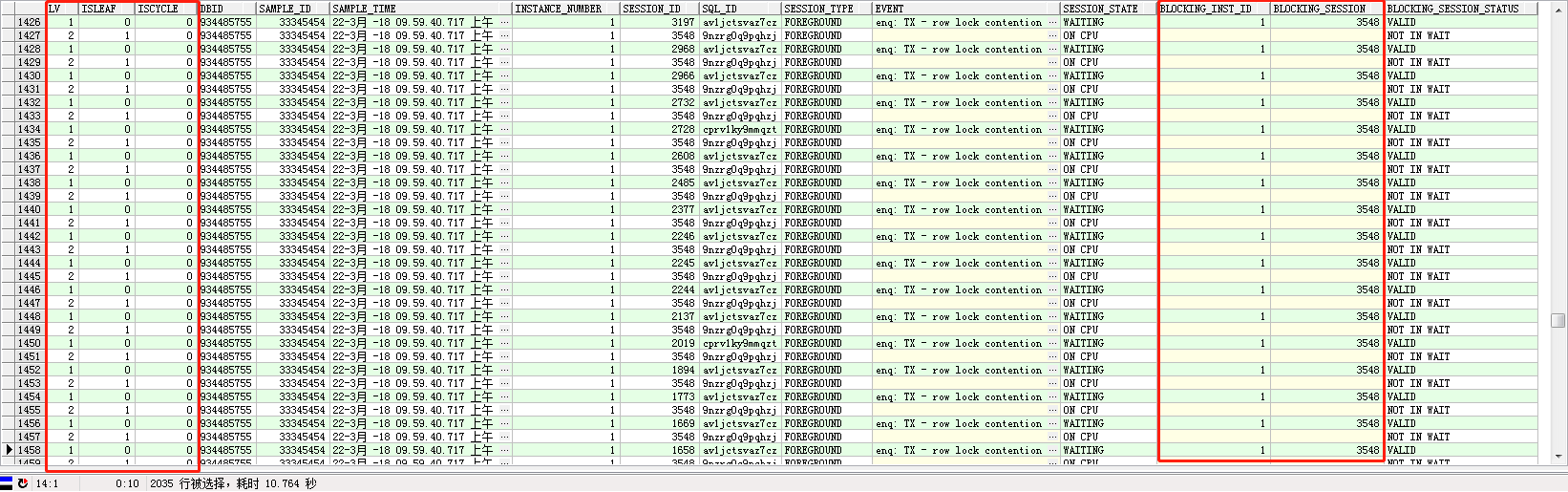
进一步筛选,将isleaf=1的叶(top holder)找出来:
--基于上一步的原理来找出每个采样点的最终top holder:
select t.lv,
t.iscycle,
t.dbid,
t.sample_id,
t.sample_time,
t.instance_number,
t.session_id,
t.sql_id,
t.session_type,
t.event,
t.seq#,
t.session_state,
t.blocking_inst_id,
t.blocking_session,
t.blocking_session_status,
t.c blocking_session_count
from (select t.*,
row_number() over(partition by dbid, instance_number, sample_time order by c desc) r
from (select t.*,
count(*) over(partition by dbid, instance_number, sample_time, session_id) c,
row_number() over(partition by dbid, instance_number, sample_time, session_id order by 1) r1
from (select /*+ parallel 8 */
level lv,
connect_by_isleaf isleaf,
connect_by_iscycle iscycle,
t.*
from m_ash20180322 t
where sample_time >
to_timestamp('2018-03-22 09:59:00',
'yyyy-mm-dd hh24:mi:ss')
and sample_time <
to_timestamp('2018-03-22 10:00:00',
'yyyy-mm-dd hh24:mi:ss')
start with blocking_session is not null
connect by nocycle
prior dbid = dbid
and prior sample_time = sample_time
/*and ((prior sample_time) - sample_time between interval '-1'
second and interval '1' second)*/
and prior blocking_inst_id = instance_number
and prior blocking_session = session_id
and prior
blocking_session_serial# = session_serial#) t
where t.isleaf = 1) t
where r1 = 1) t
where r < 3
order by dbid, sample_time, r;
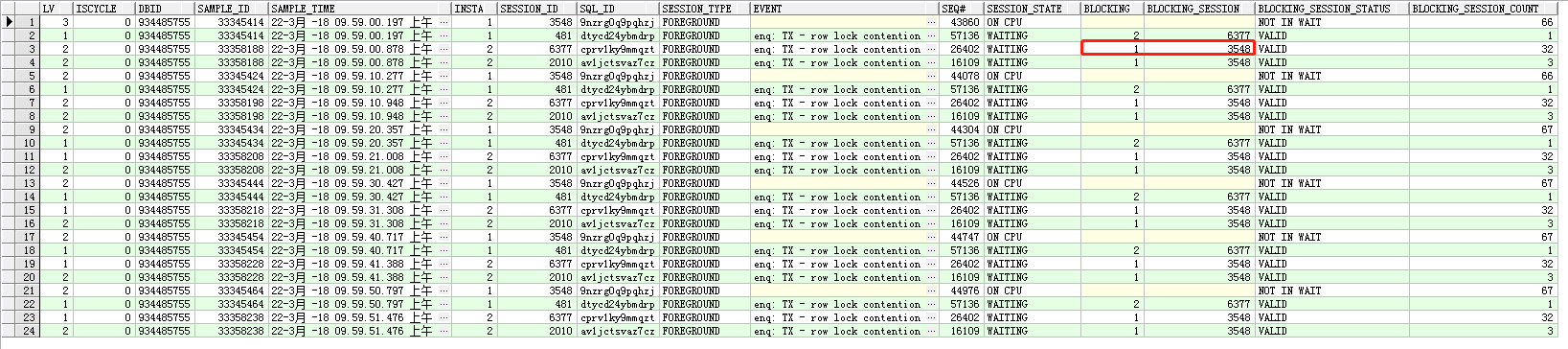
对其他异常时段进行分析:
2018-03-22 12:29:00
2018-03-22 12:30:00
2018-03-22 14:09:00
2018-03-22 14:10:00
-- top holder: DIY sample_time
select t.lv,
t.iscycle,
t.dbid,
t.sample_id,
t.sample_time,
t.instance_number,
t.session_id,
t.sql_id,
t.session_type,
t.event,
t.seq#,
t.session_state,
t.blocking_inst_id,
t.blocking_session,
t.blocking_session_status,
t.c blocking_session_count
from (select t.*,
row_number() over(partition by dbid, instance_number, sample_time order by c desc) r
from (select t.*,
count(*) over(partition by dbid, instance_number, sample_time, session_id) c,
row_number() over(partition by dbid, instance_number, sample_time, session_id order by 1) r1
from (select /*+ parallel 8 */
level lv,
connect_by_isleaf isleaf,
connect_by_iscycle iscycle,
t.*
from m_ash20180322 t
where sample_time >
to_timestamp('&begin_sample_time',
'yyyy-mm-dd hh24:mi:ss')
and sample_time <
to_timestamp('&end_sample_time',
'yyyy-mm-dd hh24:mi:ss')
start with blocking_session is not null
connect by nocycle
prior dbid = dbid
and prior sample_time = sample_time
/*and ((prior sample_time) - sample_time between interval '-1'
second and interval '1' second)*/
and prior blocking_inst_id = instance_number
and prior blocking_session = session_id
and prior
blocking_session_serial# = session_serial#) t
where t.isleaf = 1) t
where r1 = 1) t
where r < 3
order by dbid, sample_time, r;
发现所有的异常时刻最终阻塞都是实例1的sid为3548的session,不再赘述。
5.总结
从第四步可以看到,top holder都是实例1,会话3548. 比如可以看到实例1的481会话被实例2的6377会话阻塞,然后实例2的6377会话又被实例1的3548会话阻塞。 通过sql_id可以查询到sql文本:select * from dba_hist_sqltext where sql_id = '&sql_id';
可以看到实例1的3548会话当前正在执行的SQL只是一个查询语句,当前会话状态是ON CPU,所以推测该会话之前有DML的事物未提交导致阻塞。
去查询该会话的DML操作时,也有update和insert操作,但是update操作已经无法找到对应SQL文本。
select t.event, t.*
from m_ash20180322 t
where instance_number = 1
and session_id = 3548
and t.sql_opname <> 'SELECT';
其实从ash也可以看到关于3548阻塞的信息,甚至从addm的建议中也会有类似建议:
Rationale
The session with ID 3548 and serial number 8795 in instance number 1 was
the blocking session responsible for 52% of this recommendation's
benefit.
Rationale
The session with ID 6377 and serial number 30023 in instance number 2
was the blocking session responsible for 47% of this recommendation's
benefit.
只不过我们从底层查询,可以看到6377实际也是被3548阻塞,找到最终阻塞者。
btw,从导入的awrdump中,除了可以取awr外,同样可以支持取awrsqrpi和addmrpti以及ashrpti,非常方便:
SYS@jyzhao1 >@?/rdbms/admin/awrrpti
SYS@jyzhao1 >@?/rdbms/admin/awrsqrpi
SYS@jyzhao1 >@?/rdbms/admin/ashrpti
SYS@jyzhao1 >@?/rdbms/admin/addmrpti
6.reference
- http://feed.askmaclean.com/archives/dba_hist_active_sess_history.html转载请注明原文链接:https://www.cnblogs.com/jyzhao/p/8628184.html
👋 感谢阅读,欢迎关注我的公众号 「赵靖宇」


 浙公网安备 33010602011771号
浙公网安备 33010602011771号