Efficient Estimation of Word Representations in Vector Space 论文笔记
Mikolov T , Chen K , Corrado G , et al. Efficient Estimation of Word Representations in Vector Space[J]. Computer ence, 2013.
源码:https://github.com/danielfrg/word2vec
文章目的
本文的目的是提出学习高质量的词向量(word2vec)的方法,这些方法主要利用在十亿或者百万词汇的数据集上。因此作者提出了两个新颖的模型(CBOW,Skip-gram)来计算连续向量表示,表示的质量用词的相似度来衡量,将结果与之前表现最好的神经网络网络模型进行比较。
作者试图用新的模型结构来最大化向量操作,并且保留单词之间的线性规律。同时讨论了训练时间和准确率如何依赖于单词向量的维度及训练数据量。
结论
- 新的模型降低了计算复杂度,提高了准确率(从160亿单词的数据集中学习高质量的单词向量)
- 这些向量在测试集上为度量语法和语义提供了最先进的性能。
背景
一些NLP系统和任务把词作为原子单元,词与词之间没有相似度,是作为词典的下标表示的,这种方法有几个好处:简单,鲁棒,在大数据集上训练的简单模型比小数据集上训练的复杂模型好。最广为流传的是用于统计语言模型的N元模型,今天,它可以训练几乎所有数据的n元模型。
这些简单的技术在很多任务上有限制。因此简单的改进这些基本的技术并不能带来显著的效果提升,必须关注更先进的技术。
Model Architectures
之前许多研究人员提出了许多不同类型的模型,例如LSA和LDA。在本文中,作者主要研究了神经网络学习的单词分布式表示。
为了比较不同模型的计算复杂度,提出了如下的模型训练复杂度:
- E:训练迭代次数
- T:训练集中的单词数量
- Q:Q被每一个模型进一步定义,具体如下。
Feedforward Neural Net Language Model(NNLM)
结构:
- Input Layer:使用one-hot编码的N个之前的单词,V是词汇表的大小
- Projection Layer:维度是\(N×D\),使用了一个共享的投影矩阵
- Hidden Layer:H表示隐藏层节点的个数
- Output Layer:V表示输出节点的个数
每个样本的计算复杂度公式如下所示:
- \(N×D\):输入层到投影的权重个数,N是上下文的长度,D是每个词的实数表示维度
- \(N×D×H\):投影层到隐藏层的权重个数
- \(H×V\):隐含层到输出层的权重个数
原本最重要的一项是\(H×V\),但是作者提出利用 hierarchical softmax 或者避免使用规则化模型来处理它。其中利用Huffman binary树来表示单词,需要评估的输出单元的个数下降了\(log_2(V)\)。因此,大多的计算复杂度来源于 \(N×D×H\) 项。
Recurrent Neural Net Language Model (RNNLM)
基于语言模型的循环神经网络主要克服前馈NNLM的缺点,比如需要确定文本的长度。RNN可以表示更复杂的模型。
结构:
- Input Layer:单词表示D和隐藏层H有相同的维度
- Hidden Layer:H表示隐藏层节点的个数
- Output Layer:V表示输出节点的个数
这种模型的特点是有循环矩阵连接隐藏层,具有时间延迟连接,这允许形成长短期记忆,过去的信息可以由隐藏状态表示,隐藏状态的更新由当前输入和前一个输入的隐藏层的状态决定
每个样本的计算复杂度公式如下所示:
- \(H×H\):输入层到隐藏层的权重个数
- \(H×V\):隐藏层到输出层的个数
同样,使用 hierarchical softmax 可以把\(H×V\)项有效地下降为\(H×log_2(V)\)项。因此大多数地复杂度来源于\(H×H\)项。
Parallel Training of Neural Networks
作者在Google的大型分布式框架DistBelief上实现了几个模型,这个框架允许我们并行地运行同一个模型的不同副本,每个副本通过一个保存所有参数的中央服务器进行参数更新。对于这种并行训练,作者使用mini-batch异步梯度下降和一个叫做Adagrad的自适应的学习率。在这个框架下,通常使用一百或者更多的副本,每一个副本在一个的数据中心的一个机器上的使用多个CPU核心。
提出的模型
作者提出了两个新的模型(New Log-linear Models)来学习单词的表示,新模型的优势主要在于减小了计算复杂度。作者发现大量的计算复杂度主要来源于模型中的非线性隐藏层。
两个新的模型采用相似的模型结构,都有 Input层、Projection层和Output层。
Continuous Bag-of-Words Model
输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。
和NNLM相比去掉了非线性隐藏层,并且投射层共享给所有的单词(不单单是投射矩阵的共享)。因此,所有单词都会投影到一个D维的向量上(加和平均)。
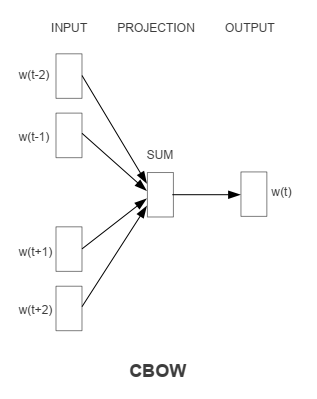
计算复杂度是:
Continuous Skip-gram Model
输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。
使用当前的单词作为输入,输入到一个投影层,然后会预测当前单词的上下文。
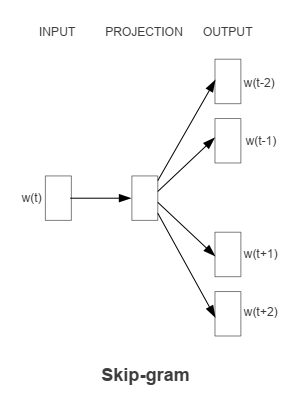
计算复杂度是:
- C:单词之间的最大距离
Comments
关于这两个模型的具体分析可以参考这篇论文:Rong X . word2vec Parameter Learning Explained[J]. Computer ence, 2014.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号