深度学习四:从循环神经网络入手学习LSTM及GRU
循环神经网络
简介
循环神经网络(Recurrent Neural Networks, RNN) 是一类用于处理序列数据的神经网络。之前的说的卷积神经网络是专门用于处理网格化数据(例如一个图像)的神经网络,而循环神经网络专门用于处理序列数据(例如\(x^{(1)},x^{(2)},···,x^{(T)},\))的神经网络。
应用场景
一些要求处理序列输入的任务,例如:
- 语音识别(speech recognition)
- 时间序列预测(time series prediction)
- 机器翻译(machine translation)
- 手写识别(handwriting recognition)
RNN产生的原因
通常我们人类思考,不会从是每一秒都要从一件事的开始进行思考。就像你正在读这篇文章,你所理解的每一个词都是从之前的基础上来的。你永远不会把之前的词丢掉从新开始思考。也就是说思考都是持续性的。
而我们之前讨论的传统的神经网络是做不到让思考持续性的,这是它们的一个主要的问题。而RNN的出现,就是为了解决这一个问题。也就是让思考具有持续性!
符号
在正式讨论之前,我们先明确一些符号和概念:
- \(x^{(t)}\) :是在时刻 t 包含的向量,即时刻 t 的输入
- \(\tau\):序列长度
- 时间步:time step,这不是现实中的时间,而是序列数据的每一次的输入。时间步索引表示序列中的位置。
简单RNN结构
Simple Recurrent Network(SRN) 是 Elman 在 1990 年提出的,所以又叫ELem Network,基本结构如下:
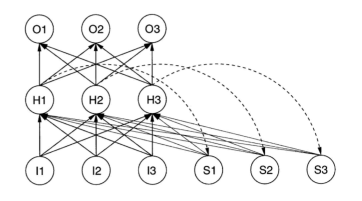
可以看出,和传统的神经网络结构相比,RNN最大的不同在于它的隐藏层节点(H1,H2,H3)和记忆单元(S1,S2,S3)(“context” layer)之间存在直接连接(虚线)。
也就是:
- 说每一次隐藏节点输出的时候,出了传递激活后的信息到下一层,还会被复制到记忆单元中。
- 隐藏层节点除了和输入节点(I1,I2,I3)之间存在连接以外,还和 context layer 之间存在直接连接(实线)。即隐藏层同时接收来自输入层和 context layer 的输入
- context layer 无限期的保留状态信息。每次网络接收一个输入都会用 context layer 来记住产生输出所需要的信息。
从上述信息中可以看出,循环神经网络名字中循环的由来,即网络本身是一个循环的序列结构。
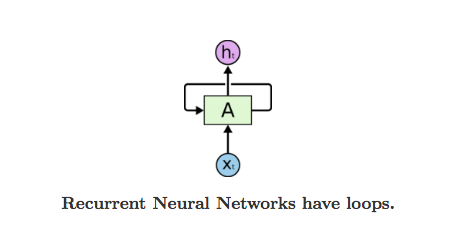
我们可以用这样的图来简洁的表示 SRN。其中 \(A\) 表示一个神经网络结构块。\(x_t\) 表示输如,\(h_t\) 表示输出。在这个图中神经网络的基本结构被压缩了,从 \(x_t\) 到 \(A\) 的一条线实际上是上面的从输入节点到输出节点的全部连接。同样的 \(A\) 到 \(h_t\) 也是一样。而且下图中忽略掉了 context layer 的存在。
如果我们再进一步思考,会发现上面的图和普通的神经网络好像又没有什么区别。因为我们可以把上面的图展平成一个等价的前馈结构,从而更好的观察神经网络的结构。这相当于一个共享权重的网络结构。
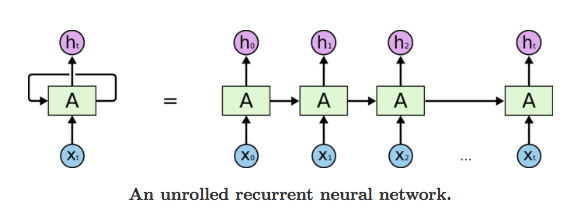
这种链状的性质表明循环神经网络与序列和列表密切相关。RNN 也正是用于处理此类数据的神经网络的自然结构。
RNN中的反向传播
在循环神经网络中应用反向传播被称为 通过时间反向传播 backpropagation through time(BPTT),如下图所示:

我们可以反向传播一个 time step, 也可以反向传播固定数目的 time steps,也可以直接反向传播到序列的最开始。
之后应该还需单独写一篇文章来分析BPTT,现在还不太会推导实现。
其他的RNN结构
- 有的时候,我们会在输入层和输出层之间添加直接的连接,又叫 shortcut。如下图所示:
- Jordan Networks:在输出层添加一个返回到隐藏层的连接。
长期依赖的问题
RNN的优势之一就是它可以把之前的信息和当前的信息相互关联。例如,使用视频中先前的帧可以帮助理解当前的帧。如果RNN可以永远做到这一点那是最好的,但是在实际应用中,RNN好像不能永远保留所有的先前信息。
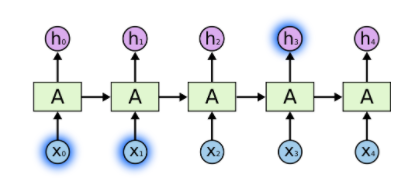
有时候,我们只需要利用很少的先前信息就可以执行当前的任务。例如,我们考虑一个基于之前的单词预测之后的单词的语言模型。如果我们想预测 “the clouds are in the sky“ 这句话中的最后一个单词,我们不需要知道特别多的信息就能知道最后一个单词是天空。在这种情况下,当相关的信息和需要预测的地方差距很小的时候,RNN 可以迅速的学习并利用之前的信息。过程如下图所示:
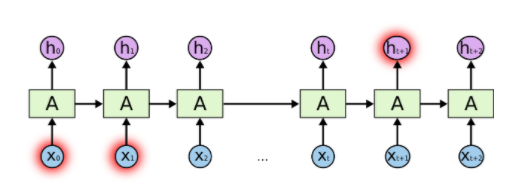
然而,有的时候我们需要更多的先前信息。例如,我们还是考虑一个基于之前的单词预测之后的单词的语言模型。我们想预测下面这句话的最后一个单词。“I grew up in France… I speak fluent French.” 相邻的单词可以告诉我们可能要填入一个语言的名称,但是我们不知道要填入哪一个语言。我们需要继续向先前的信息中寻找,直到找到 France。 这之前的差距可能会非常的巨大。在这种情况下,RNN 就不能够学习到什么有用的东西了。过程如下图所示:
上面的问题就是我们要讨论的长期依赖(long-term dependency)问题。也就是说RNN是具备长期依赖问题的!
门控网络
门控网路(Gated Network)是学习 LSTM 之前必须明白的一个基本网络结构。因为门控的理念是 LSTM 的核心。
如下图所示,这是一个简单的二阶门控网络 Second Order(or Gated)Network:从图中可以看出,门控的意思就是通过一个类似于开关的结构控制输入和相应的权重来配对。如果我们有26个字母要来识别的话,就会有26套权重。
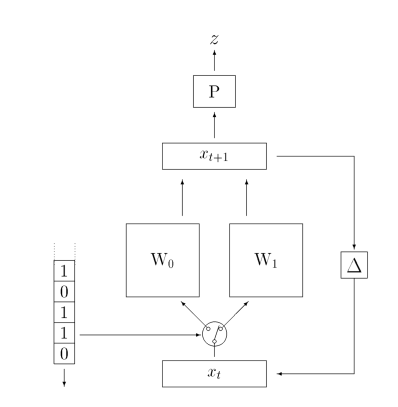
这个门控网络主要是被设计来处理语言识别的,例如,一次扫描一个字符序列,然后将序列分类为接受或拒绝。:
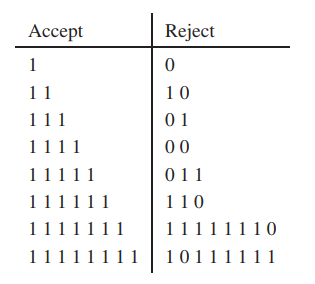
这样的问题可以转换为一个有限状态机来理解,如下所示,右下角就是对应的有限状态自动机,左边是一个二维图 表示。叉表示初始状态,如果输入为 1 ,将会向右上角走,如果为 0,会往左下角走。如果最终停在了斜线的右侧就表示为 Accept,如果停在了左侧就表示为 Reject。
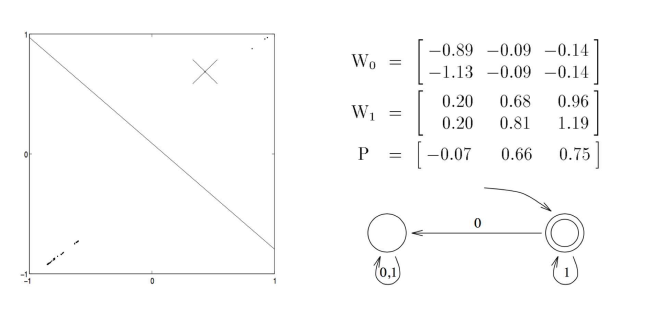
下面我们再来看一个更加复杂的语言识别任务,如下图所示,如果连续出现 3 个及以上数量的 0 就 Reject:

这个任务的有限状态自动机和图可以表示为下面的形式
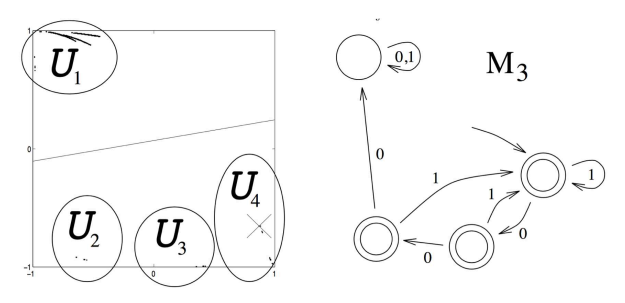
如果语言识别的任务再复杂一些呢?
我们下面来看一下 Chomsky Hierarchy ,这涉及到了更加复杂集中语言识别任务,根据前面的字母预测下一个字母是什么:
例如,我们要识别这样的一个字符串,abaabbabaaabbbaaaabbbbabaabbaaaaabbbbb...
对于这样的一个任务,第一个 b 的位置其实是很难预计的,但是如果已经给出了 b 那么后续的 b 和后续的第一个 a 是可以被预测出来的。下面的 Elem Network 就可以实现这个预测:
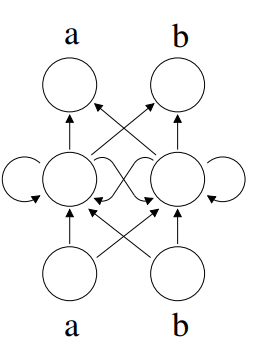
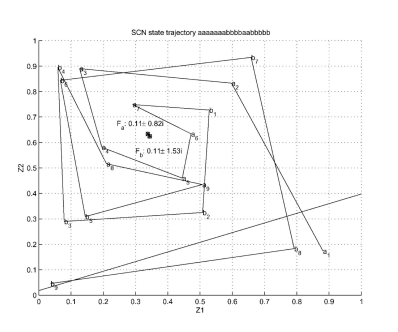
这个网络很难用有限状态自动机表示,但是我们可以用激活空间中两个固定的点(fix point)来表示,一个是吸引点,一个是排斥点,这是一个震荡的解法,也就是每一个输入都是围绕着一个 fix point 来回震荡,虚线就是我们的分割线,如下图所示:
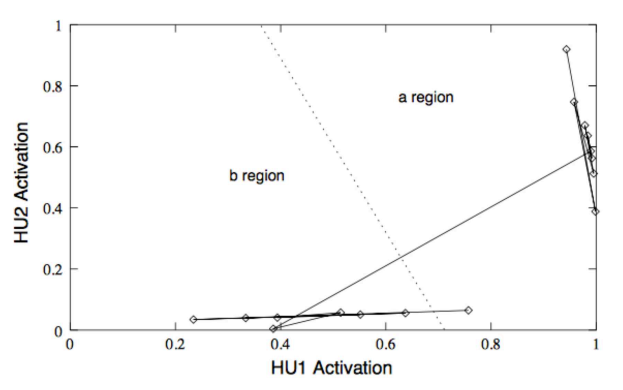
然而这个神经网络再训练的时候,有时候会有非单调的情况,这种情况下就不会再围着 fix point 震荡了,而是随着输入一直趋向于一个 fix point,如下图所示:
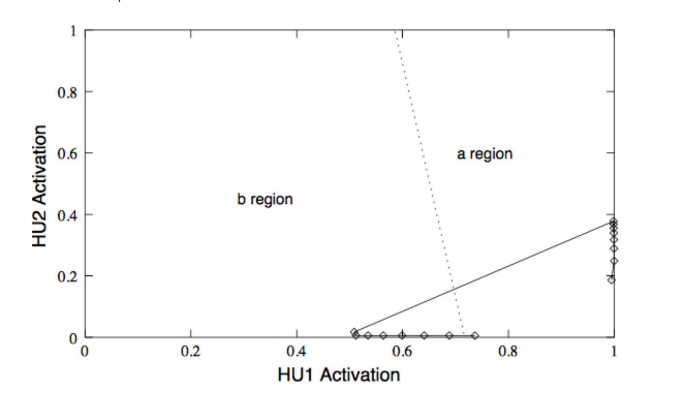
如果我们利用旋转来计算的话,如果输入是 a 就向内圈旋转,如果输入是 b 就向外圈旋转,下方的直线是输出线:
如果我们要处理的任务是根据 \(a^nb^nc^n\) 来预测,那么 solution 就可以表示为下图所示的情况,最终预测的输出线从一条线变成了一个面,下图中没有画出来,大家知道这件事就可以了:
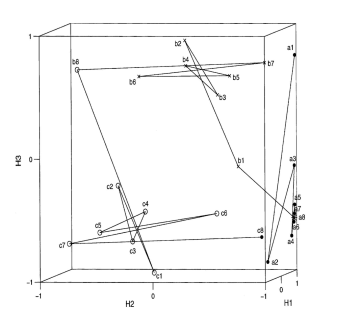
在这个图中,a b c 是向不同的方向计数来实现预测的,会产生几个星形的形状。
如果是部分单调的话,就会变成下面的样子:
LSTM
简介
长短期记忆网络(Long Short Term Memory networks,LSTM)是一种特殊的 RNN,主要用于处理长期的依赖。是由 Horchreiter 和 Schmidhuber 发明的。
LSTM 产生的原因
LSTM 被设计出来主要是为了解决长期依赖(long-term dependency)问题。也就是长时间的记住某些东西。
SRN 可以学习到中等范围的东西,但是在学习长期依赖方面有困难。
LSTM 和 GRU(后面会提到)在学习长期依赖方面要优于SRN。
LSTM的结构
在看 LSTM 的结构之前,我们再来讨论一下 RNN 的结构。
所有的循环神经网络都由重复的链式神经网络结构构成的。在标准的 RNN 中重复的神经网络通常会采用一个十分简单的结构,例如一个单独的 tanh 层。如下图所示:
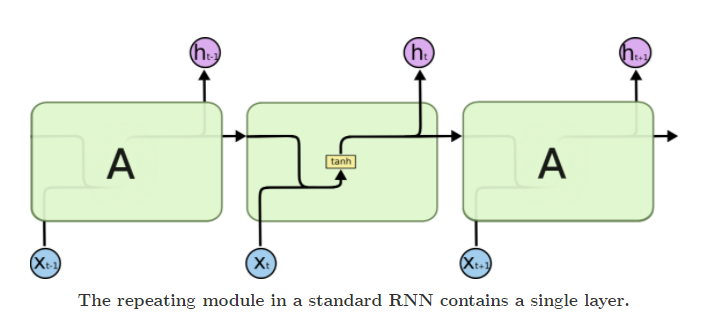
在明确了上面的传统的 RNN 的结构图之后呢,我们来仔细研究一下 LSTM 的结构图。
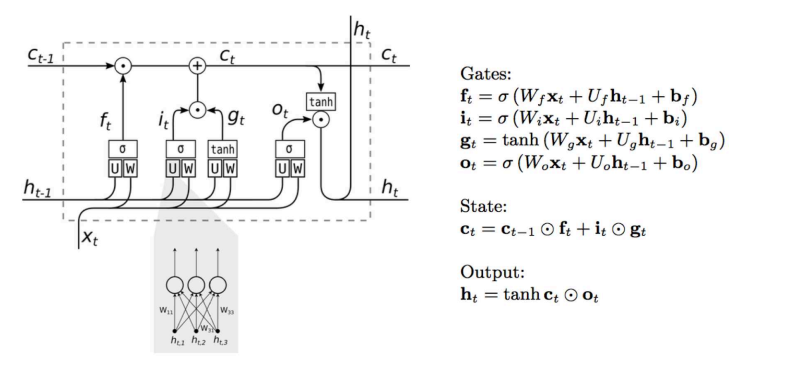
LSTM 同样有类似链式结构,但是它的重复的神经网络结构的部分,不再是一个简单的 tanh 层,而是一个十分复杂的结构。具体来讲有四层神经网络和三个门控构成!如下图所示:
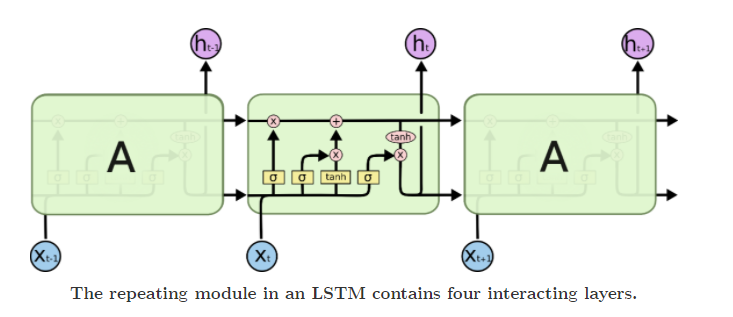
我们可以对上面的结构进行如下的一个基本划分,明确一下接收了哪些输入,后面再具体将每一处的细节,可以先暂时不管右边的公式:
下面我们将一步步的学习 LSTM 的结构,在学习之前我们先明确一下相关的符号:
- 黄色方框:一个神经网络层
- 粉色圆圈:一个点态操作
- 一条线:携带一个完整的向量从一个节点的输出到另一个节点的输入
- 合并的线:连接
- 分叉的线:把一个内容赋值到两个不同的位置
LSTM 的核心
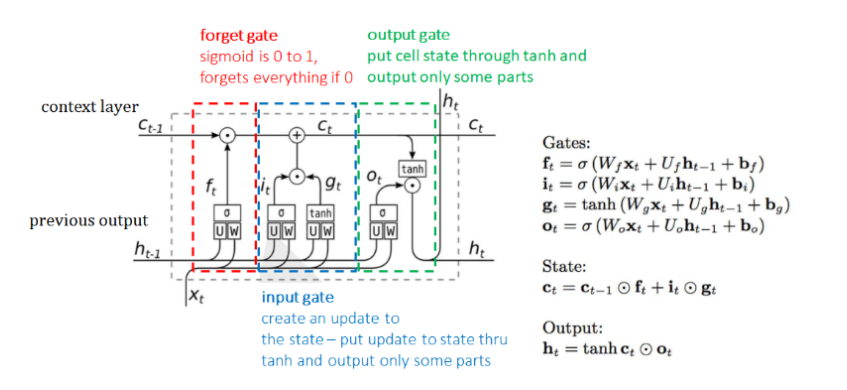
LSTM 的核心关键是细胞状态(cell state),表示细胞状态的这条线水平的穿过图的顶部。细胞的状态类似于输送带,细胞的状态在整个链上运行,只有一些小的线性操作作用其上,信息很容易保持不变的流过整个链。

门控是一种选择性地让信息通过的方式。具体的门控概念和相应的任务实例已经在上面讲过了。LSTM 中它们由一个 Sigmoid 神经网络层和一个点乘运算组成。Sigmoid 层输出 0 到 1 之间的数字,描述每个组件有多少应该被允许通过。一个 LSTM 有三个这样的门,以保护和控制单元的状态。

具体分析LSTM的结构
- 第一步:LSTM 中的第一步就是要决定我们从之前的信息中丢弃哪些信息。这个是 forget gate 的工作。如下图所示:
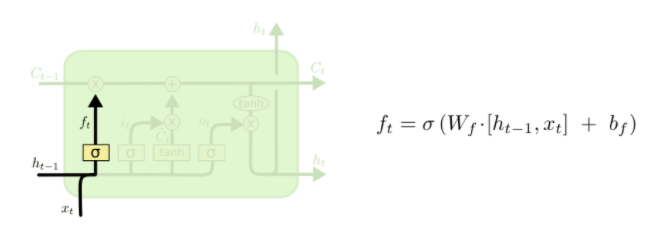
丢弃信息通过一个 Sigmoid 层实现,又叫 forget gate layer。接收了上一层的输出 \(h_{t-1}\) 以及当前 time step 的输入 \(x_t\) 。通过 Sigmoid 层之后输出一个介于 0 和 1 之间的数字 \(f_t\)。如果 \(f_t = 1\) 表示完全的保留这些信息;如果 \(f_t = 0\) 表示完全的遗忘这些信息;如果 \(0<f_t<1\) 表示只忘记一部分信息。
- 第二步:LSTM中的第二步就是决定我们要保留哪些新信息,即存储哪些信息到 cell state 中。这个是 input gate 的工作。如下图所示:
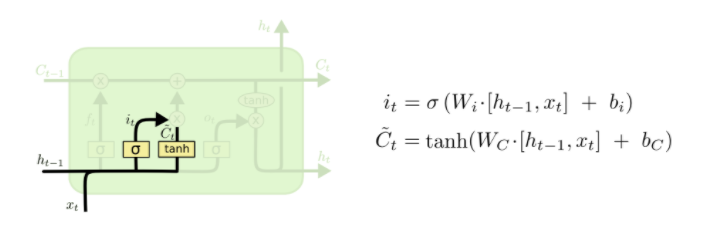
从图中可以看出,这一步由两个神经网络层来实现。第一个是一个 Sigmoid 层,又称为 input gate layer,决定的是我们将会更新哪信息。第二个是一个 tanh 层,会创建一个新的候选数据 \({\widetilde{C}_{t}}\) ,它将会被添加到当前信息中。在下一步的时候,我们会将二者结合来创新对新信息的更新。
- 第三步:我们要将传入的旧cell state \({\widetilde{C}_{t-1}}\) ,更新为新的cell state \({\widetilde{C}_{t}}\) 。如下图所示:
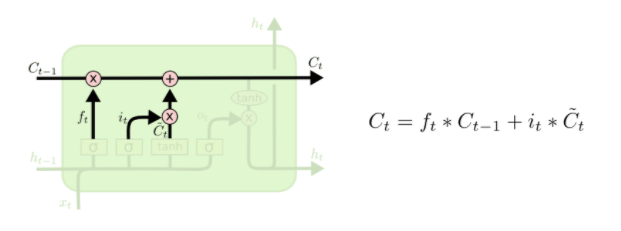
我们先用第一步产生的 \(f_t\) 乘以 \({\widetilde{C}_{t-1}}\) ,也就是忘记我们打算忘记的信息(这就是一个门控过程)。然后和 \(i_t *{\widetilde{C}_{t}}\) 相加。这就是我们根据想要更新多少信息而选出的新的信息。
- 第四步:决定我们要输出什么信息,这个是 output gate 的工作。如下图所示:
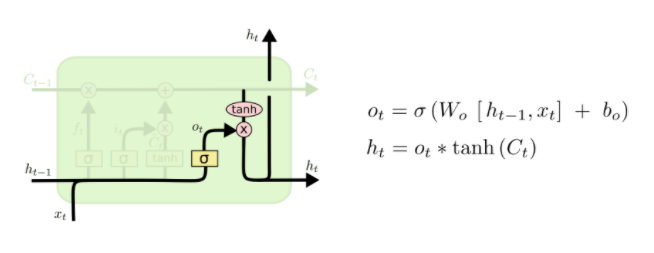
首先我们利用一个 Sigmoid 层决定我们要输出哪些信息。然后我们把第三步的新的信息放入一个 tanh 层中(把值置为 -1 到 1 之间),然后二者相乘。最终就能得到我们想输出的值。
由此整个 LSTM 的数据流向和基本操作已经学习完毕。但是我们还有个地方需要注意!
如果你有仔细看基本结构划分的黑白图,会发现里面多了几个框,也就是 U 和 W 的框。这个其实就是我们的神经网络的权重。需要注意的一点是,这里的三组 U 和 W 是各不相同!也就是第一组实际上应该是 \(U_f\) 和 \(W_f\) ;第二组实际上应该是 \(U_i\) 和 \(W_i\) ;第三组实际上应该是 \(U_o\) 和 \(W_o\)。之前讨论过的公式,最终应该为下图右边表示的公式:
GRU
简介
门控循环单元(Gated Recurrent Unit, GRU), 是 LSTM 的一个比较经典的变种。在上面的传统LSTM中有三个门控单元,但是在GRU中只有两个门控单元,分别为更新门和重置门,结构变的更加的简单了。所以和LSTM相比,它更容易计算。如下图所示:
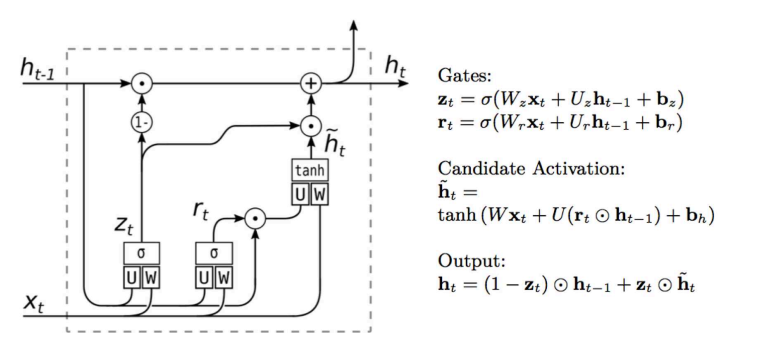
- 重置门:reset gate,\(z_t\),控制需要从前的忘记多少信息和从当前的信息里保留多少信息。
- 更新门:update gate,\(r_t\),控制需要保留多少之前的信息,这个和 LSTM 中的相同。
其实如果你已经理解了LSTM的公式,那么可以从右侧的公式中很容易就能看出两个门控的作用。
- 如果当前的任务是处理具有长期依赖的信息,那么更新门会起到比较大的作用。
- 如果是处理短期依赖的信息,那么重置门会起到比较大的作用。
- 如果 \(r_t\) 为 1,\(z_t\) 为 0,GRU 就变成了传统的RNN
LSTM 和 GRU 对比
- GRU 参数更少,计算更容易,更容易收敛。但是 LSTM 更适用于处理数据集很大的任务。因为它的表达能力更强
- GRU 只有两个门,而LSTM有三个门。GRU 没有 output gate,而是直接把得到的 \(h_t\),即隐藏单元的输出传给下一个 time step。而 LSTM 利用一个 output gate 将 \(h_t\) 再进行一次处理之后再输出。
常见面试问题
- 什么是 RNN
- RNN 为什么好
- RNN 容易梯度消失,怎么解决?
- LSTM 和 RNN 的区别
- LSTM 每个门的公式
- LSTM 和 GRU 的原理
- 画出 GRU 的结构
- 推导 LSTM 正向传播和反向传播的过程
参考资料
- Understanding LSTM Networks, Posted on August 27, 2015
- Deep Learning, Ian Goodfellow, Yoshua Bengio and Aaron Courville
- 老师上课讲的内容 ( ̄▽ ̄)"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号