算法:记忆化搜索算法
一:简述
记忆化搜索实际上是递归来实现的,但是递归的过程中有许多的结果是被反复计算的,这样会大大降低算法的执行效率。
而记忆化搜索是在递归的过程中,将已经计算出来的结果保存起来,当之后的计算用到的时候直接取出结果,避免重复运算,因此极大的提高了算法的效率。
二:应用实例
题目描述
对于一个递归函数w(a,b,c)
- 如果 a<=0 or b<=0 or c<=0 就返回值1.
- 如果 a>20 or b>20 or c>20就返回w(20,20,20)
- 如果 a<b并且b<c 就返回w(a,b,c-1)+w(a,b-1,c-1)-w(a,b-1,c)
- 其它的情况就返回w(a-1,b,c)+w(a-1,b-1,c)+w(a-1,b,c-1)-w(a-1,b-1,c-1)
这是个简单的递归函数,但实现起来可能会有些问题。当a,b,c均为15时,调用的次数将非常的多。你要想个办法才行.
/* absi2011 : 比如 w(30,-1,0)既满足条件1又满足条件2
这种时候我们就按最上面的条件来算
所以答案为1
*/
输入输出格式
输入格式:
会有若干行。
并以-1,-1,-1结束。
保证输入的数在[-9223372036854775808,9223372036854775807]之间,并且是整数。
输出格式:
输出若干行,每一行格式:
w(a, b, c) = ans
注意空格。
输入输出样例
输入样例#1: 复制
1 1 1
2 2 2
-1 -1 -1
输出样例#1: 复制
w(1, 1, 1) = 2
w(2, 2, 2) = 4
这是一个非常经典的记忆化搜索的题目。
拿到这个题,首先可以想到的就是递归的方法,看上去用递归可以轻而易举的解决。但是递归的开销是不一般的大。下面先给大家上一个递归的代码,以便和之后的记忆化搜索的进行对比。
1 #include<iostream> 2 #include<cstdio> 3 #include <time.h> //用来记时 4 using namespace std; 5 clock_t start, finish; 6 double duration; 7 8 typedef long long ll; 9 ll f[30][30][30]; 10 11 int w(ll a, ll b, ll c){ //递归的函数 12 if(a<=0||b<=0||c<=0){ 13 return 1; 14 } 15 else if(a>20||b>20||c>20){ 16 return w(20,20,20); 17 } 18 else if(a<b&&b<c){ 19 return w(a,b,c-1) + w(a,b-1,c-1) - w(a,b-1,c); 20 } 21 else{ 22 return w(a-1,b,c)+w(a-1,b-1,c)+w(a-1,b,c-1)-w(a-1,b-1,c-1); 23 } 24 } 25 26 int main(){ 27 ll a, b, c; 28 while(1){ 29 cin >> a >> b >> c; 30 start = clock(); //开始计时 31 if(a==-1&&b==-1&&c==-1) return 0; 32 else{ 33 printf("w(%lld, %lld, %lld) = %d\n", a, b, c, w(a, b, c)); 34 finish = clock(); //结束记时 35 duration = (double)(finish - start) / CLOCKS_PER_SEC; //计算持续时间 36 printf( "%f seconds\n", duration ); 37 } 38 } 39 return 0; 40 }
运行结果
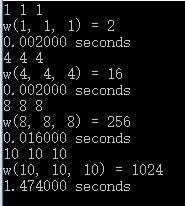
记忆化搜索解法
开辟一个数组 f[][][],用来存储计算出来的结果。
关于数组的大小:因为题目中给出了一个条件 “ 如果 a>20 or b>20 or c>20就返回w(20,20,20) ” 那么数组只要最小开到 f[21][21][21]就够用了。
具体的步骤看代码中的注解。
1 #include<iostream> 2 #include<cstdio> 3 #include <time.h> 4 using namespace std; 5 clock_t start, finish; 6 double duration; 7 8 typedef long long ll; 9 ll f[30][30][30]; 10 11 int w(ll a, ll b, ll c){ 12 if(a<=0||b<=0||c<=0){ 13 return 1; 14 } 15 else if(a>20||b>20||c>20){ 16 return w(20,20,20); 17 } 18 else if(f[a][b][c]!=0)return f[a][b][c]; //如果之前被计算过,那么直接返回存在数组中的结果 19 //没有计算过的,就进行的计算 20 else if(a<b&&b<c){ 21 f[a][b][c] = w(a,b,c-1) + w(a,b-1,c-1) - w(a,b-1,c); 22 } 23 else{ 24 f[a][b][c]=w(a-1,b,c)+w(a-1,b-1,c)+w(a-1,b,c-1)-w(a-1,b-1,c-1); 25 } 26 return f[a][b][c]; //计算完毕之后返回计算出的结果 27 } 28 29 int main(){ 30 ll a, b, c; 31 while(1){ 32 cin >> a >> b >> c; 33 start = clock(); //开始计时 34 if(a==-1&&b==-1&&c==-1) return 0; 35 else{ 36 printf("w(%lld, %lld, %lld) = %d\n", a, b, c, w(a, b, c)); 37 finish = clock(); //结束记时 38 duration = (double)(finish - start) / CLOCKS_PER_SEC; //计算持续时间 39 printf( "%f seconds\n", duration ); 40 } 41 } 42 return 0; 43 }
运行结果

三:总结过程
根据上面的题,可以总结一个记忆化搜索的过程。
1 f(problem p){ 2 if(p has been solved){ 3 return the result 4 }else{ 5 divide the p into some sub-problems (p1, p2, p3...) 6 f(p1); 7 f(p2); 8 f(p3); 9 ... 10 }
(。・∀・)ノ干杯

 浙公网安备 33010602011771号
浙公网安备 33010602011771号