

七、docker 网络基础
Docker 本身的技术依赖于 Linux 内核虚拟化技术的发展。所以 Docker 对 Linux 内核的特性有很强的依赖。
网络基础
其中 Docker 使用到的与 Linux 网络有关的技术分别有:网络名称空间、Veth、Iptables、网桥、路由。
1、网络名称空间
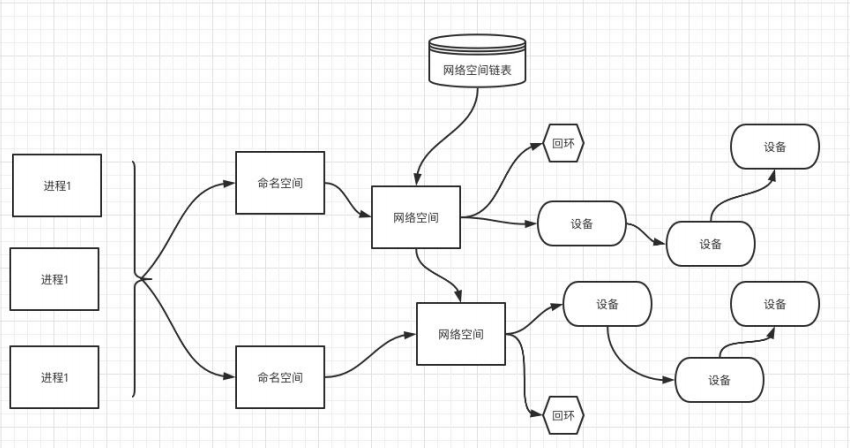
为了支持网络协议栈的多个实例,Linux 在网络协议栈中引入了网络名称空间(Network Namespace),这些 独立的协议栈被隔离到不同的命名空间中。处于不同的命名空间的网络协议栈是完全隔离的,彼此之间无法进行 网络通信,就好像两个“平行宇宙”。通过这种对网络资源的隔离,就能在一个宿主机上虚拟多个不同的网络环 境,而 Docker 正是利用这种网络名称空间的特性,实现了不同容器之间的网络隔离。在 Linux 的网络命名空间 内可以有自己独立的 Iptables 来转发、NAT 及 IP 包过滤等功能。
Linux 的网络协议栈是十分复杂的,为了支持独立的协议栈,相关的这些全局变量都必须修改为协议栈私有。 最好的办法就是让这些全局变量成为一个 Net Namespace 变量的成员,然后为了协议栈的函数调用加入一个 Namespace 参数。这就是 Linux 网络名称空间的核心。所以的网络设备都只能属于一个网络名称空间。当然, 通常的物理网络设备只能关联到 root 这个命名空间中。虚拟网络设备则可以被创建并关联到一个给定的命名空 间中,而且可以在这些名称空间之间移动。
- 创建网络命名空间
[root@master ~]# ip netns add test01
[root@master ~]# ip netns add test02
[root@master ~]# ip netns ls
test02
test01
2、Veth 设备
引入 Veth 设备对是为了在不同的网络名称空间之间进行通信,利用它可以直接将两个网络名称空间链接起 来。由于要连接的两个网络命名空间,所以 Veth 设备是成对出现的,很像一对以太网卡,并且中间有一根直连 的网线。既然是一对网卡,那么我们将其中一端称为另一端的 peer。在 Veth 设备的一端发送数据时,它会将数 据直接发送到另一端,并触发另一端的接收操作。

- Veth 设备操作
[root@master ~]# ip link add veth type veth peer name veth001
[root@master ~]# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:0c:29:ab:0f:3a brd ff:ff:ff:ff:ff:ff
3: veth001@veth: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 4e:a2:0c:f2:4d:4a brd ff:ff:ff:ff:ff:ff
4: veth@veth001: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 6e:c4:53:7e:28:f8 brd ff:ff:ff:ff:ff:ff
生成了两个虚拟网卡 veth、veth001设备, 互为对方的 peer。
- 绑定命名空间
[root@master ~]# ip link set veth001 netns test01
[root@master ~]# ip link show | grep veth
5: veth3bab2ee@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
7: veth@if6: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
##
##已经查看不到veth001,当我们进入 test01 命名空间之后,就可以查看到
[root@master ~]# ip netns exec test01 ip link
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
3: veth001@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 4e:a2:0c:f2:4d:4a brd ff:ff:ff:ff:ff:ff link-netnsid 0
- Veth001 分配 IP
#设置IP
[root@master ~]# ip netns exec test01 ip addr add 172.16.0.111/20 dev veth001
#启用veth001网卡
[root@master ~]# ip netns exec test01 ip link set dev veth001 up
#查看
[root@master ~]# ip netns exec test01 ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
6: veth001@if7: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state LOWERLAYERDOWN group default qlen 1000
link/ether 6a:87:71:9d:b9:2b brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.16.0.111/20 scope global veth001
valid_lft forever preferred_lft forever
这个时候双方就通了。
- 查看对端 Veth 设备
[root@master ~]# ip netns exec test01 ethtool -S veth001
NIC statistics:
peer_ifindex: 4
[root@master ~]# ip a | grep 4
[root@master ~]# ip a | grep 4
inet 10.0.0.90/24 brd 10.0.0.255 scope global eth0
inet6 fe80::20c:29ff:feab:f3a/64 scope link
4: veth@if3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 6e:c4:53:7e:28:f8 brd ff:ff:ff:ff:ff:ff link-netnsid 0
- 给对端 Veth 设备设置 IP
[root@master ~]# ip addr add 172.16.0.112/20 dev veth
[root@master ~]# ip link set dev veth down
[root@master ~]# ip link set dev veth up
[root@master ~]# ping 172.16.0.111
PING 172.16.0.111 (172.16.0.111) 56(84) bytes of data.
64 bytes from 172.16.0.111: icmp_seq=1 ttl=64 time=0.174 ms
64 bytes from 172.16.0.111: icmp_seq=2 ttl=64 time=0.047 ms
64 bytes from 172.16.0.111: icmp_seq=3 ttl=64 time=0.068 ms
64 bytes from 172.16.0.111: icmp_seq=4 ttl=64 time=0.050 ms
^C
--- 172.16.0.111 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3016ms
rtt min/avg/max/mdev = 0.047/0.084/0.174/0.053 ms
主机和网络名称空间互通
3、网桥
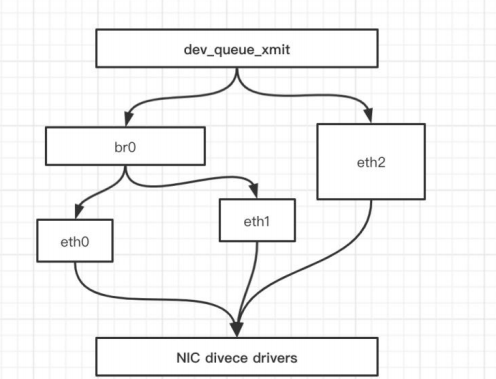
Linux 可以支持多个不同的网络,它们之间能够相互通信,就需要一个网桥。 网桥是二层的虚拟网络设备, 它是把若干个网络接口“连接”起来,从而报文能够互相转发。网桥能够解析收发的报文,读取目标 MAC 地 址的信息,和自己记录的 MAC 表结合,来决定报文的转发目标网口。
网桥设备 br0 绑定了 eth0、 eth1 。对于网络协议械的上层来说,只看得到 br0 。因为桥接是在数据链 路层实现的 ,上层不需要关心桥接的细节,于是协议枝上层需要发送的报文被送到 br0 ,网桥设备的处理代 码判断报文该被转发到 eth0 还是 ethl ,或者两者皆转发。反过来,从 eth0 或从 ethl 接收到的报文被提交给网桥的处理代码,在这里会判断报文应该被转发、丢弃还是提交到协议枝上层。 而有时 ethl 也可能会作为 报文的源地址或目的地址 直接参与报文的发送与接收,从而绕过网桥。
4、Iptables
我们知道,Linux 络协议栈非常高效,同时比较复杂 如果我们希望在数据的处理过程中对关心的数据进行一些操作该怎么做呢? Linux 提供了一套机制来为用户实现自定义的数据包处理过程。
在 Linux 网络协议栈中有一组回调函数挂接点,通过这些挂接点挂接的钩子函数可以在 Linux 网络中处理数据包的过程中对数据包进行一些操作,例如过滤、修改、丢弃等 整个挂接点技术叫作 Netfilter lptables。
Netfilter 负责在内核中执行各种挂接的规则,运行在内核模式中:而 lptables 是在用户模式下运行的进程, 负责协助维护内核中 Netfilter 的各种规则表,通过二者的配合来实现整个 Linux 网络协议战中灵活的数据包处理 机制。
总结

本文来自博客园,作者:看啥,转载请注明原文链接:https://www.cnblogs.com/jykn92/p/15154427.html

