
【mysql】 查询数据时group by,及group_concat()函数用法
GROUP BY 语句
语法

select 聚合函数, 列(要求出现在group by的后面) from 表 where 筛选条件 group by 分组的列表 order by 子句
注意:除了出现在group by后面的字段,如果要在select后查询其他字段,必须用聚合函数进行聚合
特点:分组查询中的筛选条件分为两类:
分组前筛选: 数据源是原始表,用where,放在group by前面,因为在分组前筛选
分组后筛选:数据源是分组后的结果集 ,用having,放在group by后面,因为在分组后进行筛选。
例子
# 查询每个工种最高工资员工 select max(salary), job_id from employees group by job_id; # 查询邮箱中包含a字符的每个部门的平均工资 select avg(salary), department_id from employees where email like '%a%' group by department_id # 查询有奖金的每个领导手下最高工资的员工工资 select max(salary), manager_id from employees where commission_pct is not null group by manager_id # 查询哪个部门的员工个数大于2 select count(*), department_id from employees group by department_id having count(*) > 2; # 查询每个工种有奖金的员工的最高工资大于12000的工种编号和最高工资 select max(salary), job_id from employees where commission_pct is not null group by job_id having max(salary) > 12000;
按表达式或聚合函数进行筛选
# 按照员工姓名长度分组,查询每一组员工个数,筛选员工个数大于5的有哪些 select count(*) , length(last_name) as len_name from employees group by length(last_name) having count(*) > 5;
按照多个字段分组
# 查询每个部门每个工种的员工平均工资,并且按照平均工资的高低排序 select avg(salary), department_id, job_id from employees where department_id is not null group by department_id, job_id order by avg(salary) desc;
group_concat()函数
group_concat()函数语法如下:
group_concat([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator '分隔符'])
示例:SELECT * FROM testgroup

表结构与数据如上
现在的需求就是每个id为一行 在前台每行显示该id所有分数
- SELECT id,GROUP_CONCAT(score) FROM testgroup GROUP BY id

可以看到 根据id 分成了三行 并且分数默认用 逗号 分割 但是有每个id有重复数据
接下来去重:
- SELECT id,GROUP_CONCAT(DISTINCT score) FROM testgroup GROUP BY id

排序:
- SELECT id,GROUP_CONCAT(DISTINCT score ORDER BY score DESC) as result FROM testgroup GROUP BY id

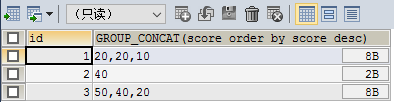
最后可以设置分隔符:
- SELECT id,GROUP_CONCAT(DISTINCT score ORDER BY score DESC SEPARATOR '-') as result FROM testgroup GROUP BY id

reference
https://www.cnblogs.com/tff612/p/15513606.html
https://blog.csdn.net/weixin_41885239/article/details/115933896
认清现实,放弃幻想。
细节决定成败,心态放好,认真学习与工作。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· .NET10 - 预览版1新功能体验(一)