embedding
1 one-hot编码
首先讲讲one-hot编码,这种编码很简单。假设你有N个词,那么就直接创建一个N维度的向量,之后每个词在不同位置上取1来区分。N个词相当于在一个N维空间里,刚好N个单位向量。而且这些向量彼此正交
这种简单的表示方法存在几个问题:
- 维度高:N个词有N个维度,所以对于英文字典,就有成百上千的维度。计算量太大,高维空间中词向量过于稀疏,不便于计算
- 不能表示词与词之间的关联:词与词是有关联的,可以是词义上的关联,也可以是词性上的关联等。但是one-hot编码导致所有词向量正交,不能表示他们之间的关系。
2 embedding操作
对于one-hot编码的问题,我们想,是否存在一种降维方法将这些词向量,映射到一个低维的空间中,同时保证相近词之间位置密集(“相近:取决于你的任务目的”),这个过程就叫embedding,将词嵌入到一个低维密集空间中。
现在embedding算法已经有很多了,我这里了解不多也不再赘述。但是2013年谷歌创造的word2vec的算法,就是其中一种著名的embedding算法。
这种算法简单,简单到只使用了带一层隐藏层的神经网络就学习到了这种映射。甚至当年的论文,连激活函数都没有,而且还是无监督学习,不需要人进行语料标注。
3 word2Vec
word2vec分为两种模型,一种叫CBOW(用上下文去预测中心词),另一种叫skip-gram(以中心词去预测上下文)
需要注意的一点,word2vec是一种伪任务(fake task),真任务意思是我们拿数据去训练一个网络,然后用训练好的网络模型去完成相应实际任务(比如预测,分类等),但是word2vec我们并没有一个实际任务,我们只是需要通过已有的词,去学习到一个网络结构进行空间映射
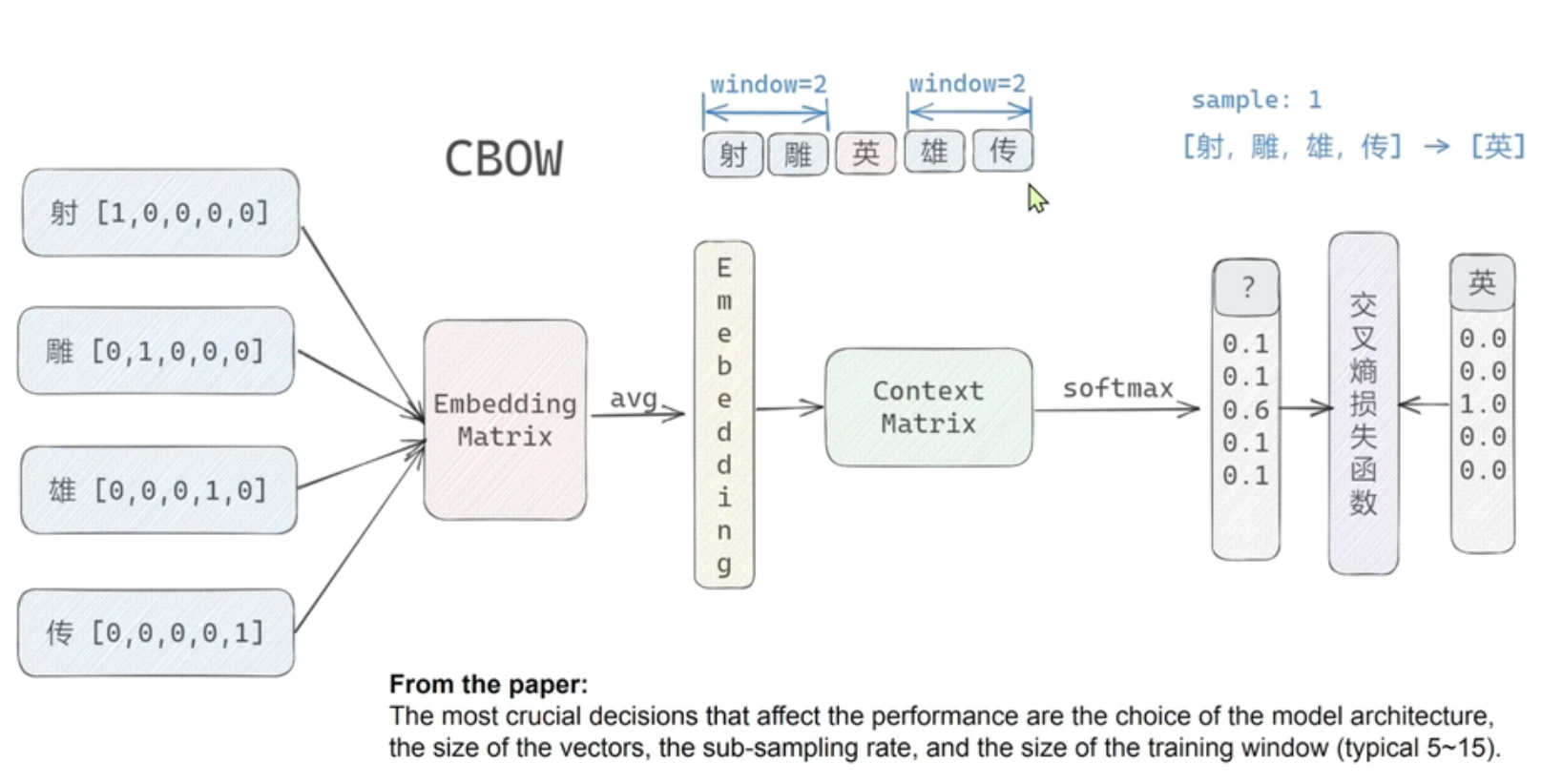
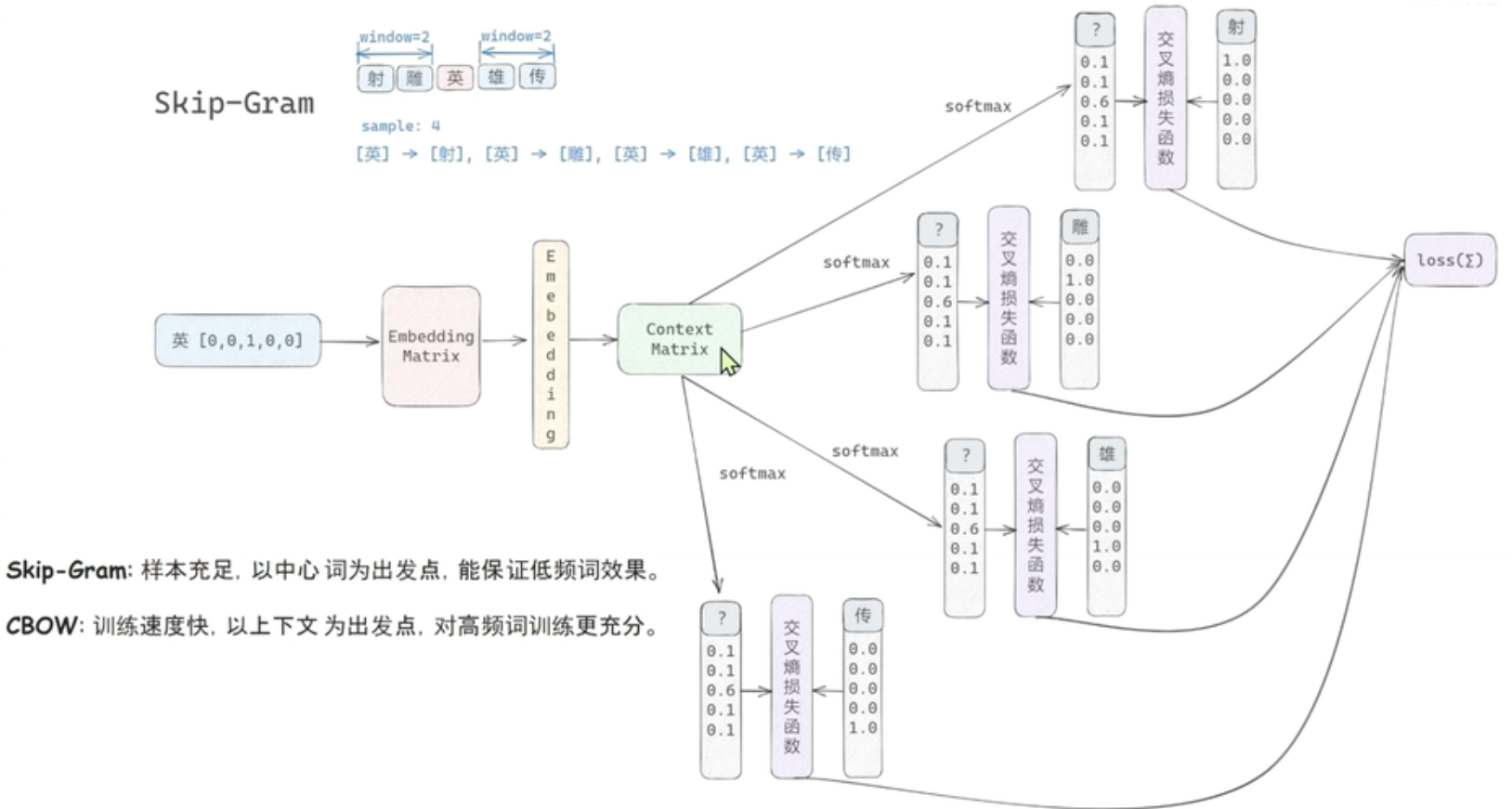
上面看起来两者的结构像是对偶的,skip-gram的输入像一个学生,但是有多个老师进行辅导,最后loss是多个老师的交叉熵求和;CBOW则是多个学生对一个老师
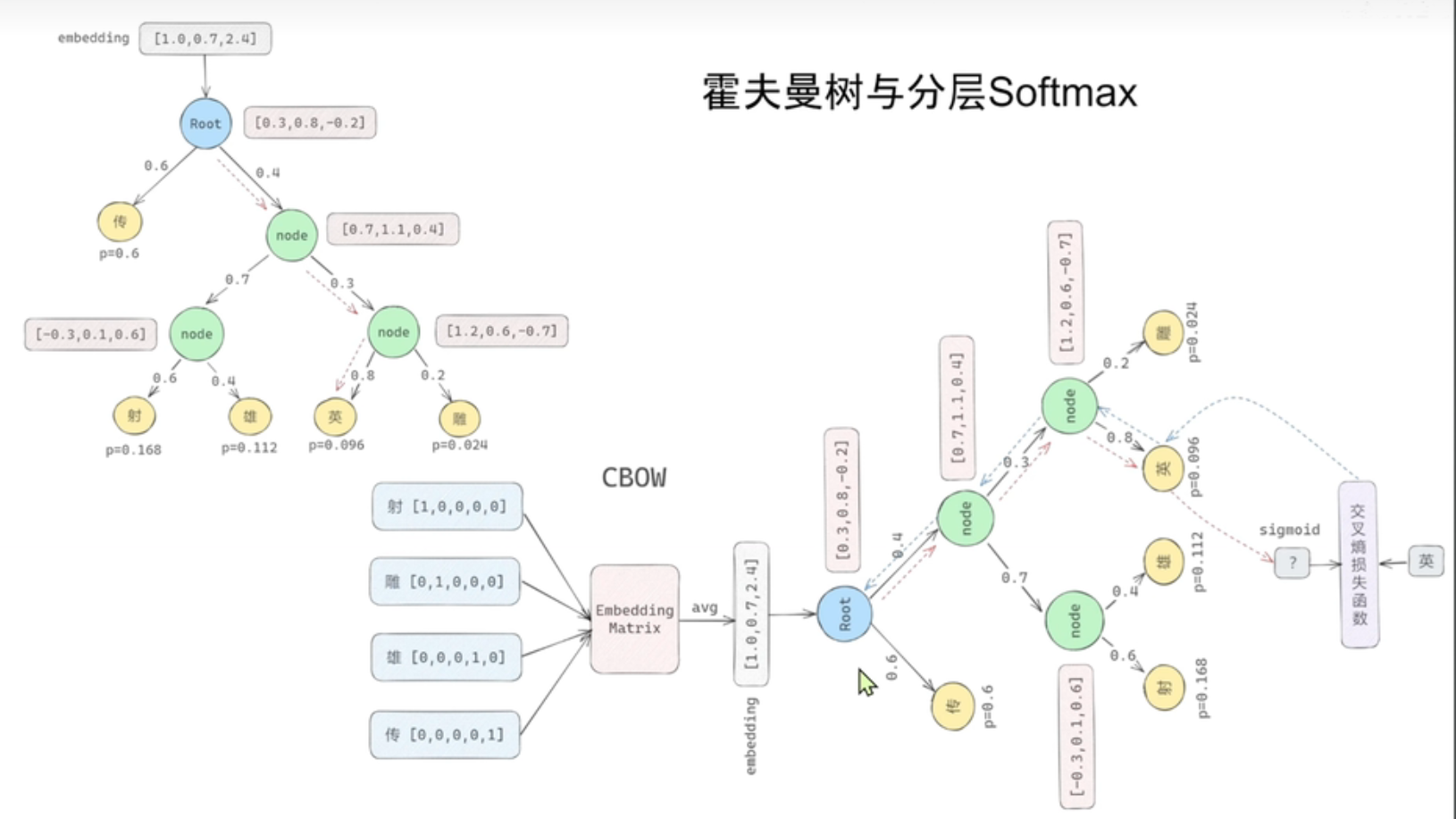
其他embedding技术

 浙公网安备 33010602011771号
浙公网安备 33010602011771号