【ACWING】KMP算法
这两天在学习KMP算法,是真的难。太抽象了而且不好理解,网上的教程太多了,而且不同教程之间在数组存储、next数组的定义上各有不同,所以看的我很混乱。
这篇文章讲的是acwing基础课上的KMP算法
- 字符数组下标从1开始存储
- next数组表示前后缀公共部分的最大长度。
0 引入
KMP经典问题的暴力求解法,用两层循环去遍历比较字符。结果是TLE
//O(nm)暴力代码如下
for ( int i =0; i < m; i++ )
{
int flag = 1;
for(int j = 0; j <n; j++ )
{
if(s[i+j] != p[j])
{
flag = 0;
break;
}
}
if(flag == 1)
{
cout <<i<< " ";
}
}
而KMP就是在上面算法的基础上进行优化的。因为如果一次匹配中途失败,我们就要将子串后移一位,重新开始匹配,这样就会浪费子串前面已经成功匹配上的字符。而想要优化暴力算法,我们就需要从这浪费掉的字符中捕获一些能够利用的信息。
1 字符串匹配过程
我们接着上面的暴力匹配过程分析

证明一下这么做的可行性
如上图所示
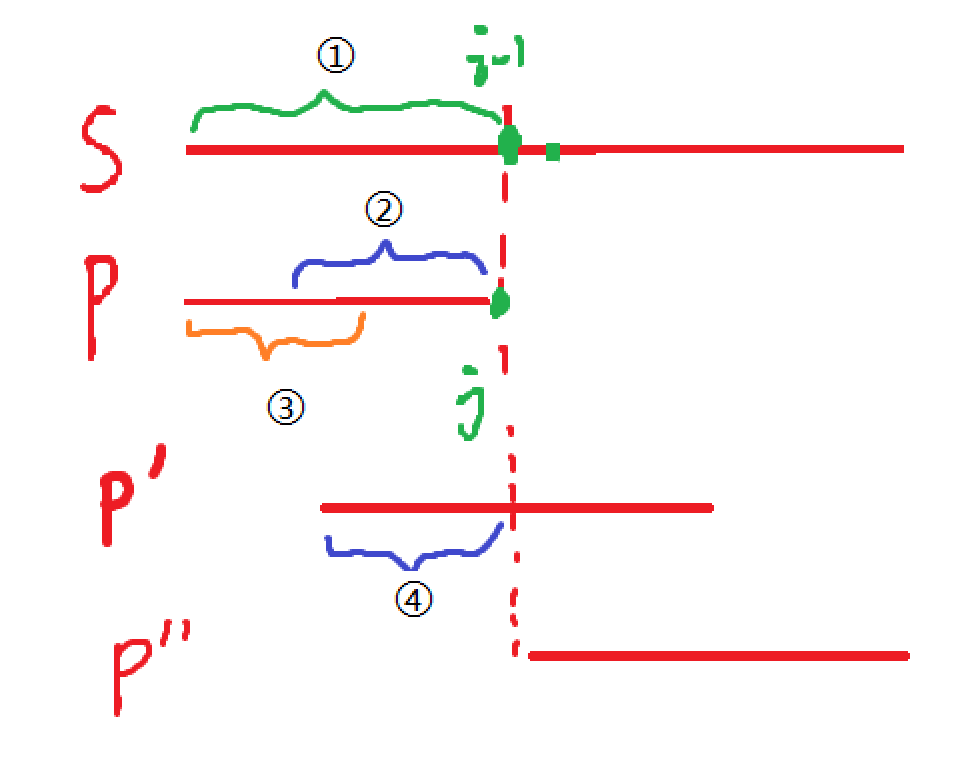
1. 当P第一次匹配上S时,易证:S和P中的①段相等。
2. 所以,第二次成功部分匹配时,即P'匹配S的情况时,②和④显然和①段中的匹配,也易得:②=④
3. 而P'和P是同一字符串,所以④=③,这就得到了② = ③ = ④
4. 此时,我们考虑P->P'的情况,不用像暴力算法一样逐位后退,而是直接从上次未匹配成功的字符开始继续匹配。在P情况下②、③已经是匹配上的了,那么P’中的④必然也是匹配得上的,下次比较就直接从下一个不匹配的开始就行。
说得再详细一点
- P->P'的过程相当于,后移子串,让子串前面的部分,替换了子串后面“已经匹配上”的部分。
- 这里的③、②分别称为前缀和后缀,只要模板串(子串)的前后缀有公共部分,那么就可以用KMP算法。
- P->P'的过程,我们需要借助next数组来定位。我们观察上图P->P'的过程,子串初始下标都为1,然后P能匹配到
j下标。P'下标同样从1开始,但是再次部分匹配时,虚线部分下标为next[j],所以每次不匹配都会导致j = next[j]。 - 观察可得,
next[j] = 前后缀最长公共部分的长度。 - 同时我们发现这个过程中,
i可以一直往前,只是不匹配时,j要回退到next[j]的位置而已
字符串匹配过程简述
- 定义变量
i,j,前者用来遍历S串,后者遍历P串。 - 比较
S[i]和P[j+1],如果相等就比较下一个字符(j++,i++) - 如果不相等,
j回退,j = next[j] - 如果
j = 子串长度,说明子串都能匹配上,这就是完全匹配的情况了。
2 求next数组
这部分是真的头疼。
next数组的含义:next[j]表示子串的部分切片P[1,j]中最长公共前后缀长度。(这里是左闭右闭的切片)
所以构建next数组,就是求某一字符串切片的最长公共前后缀的长度。
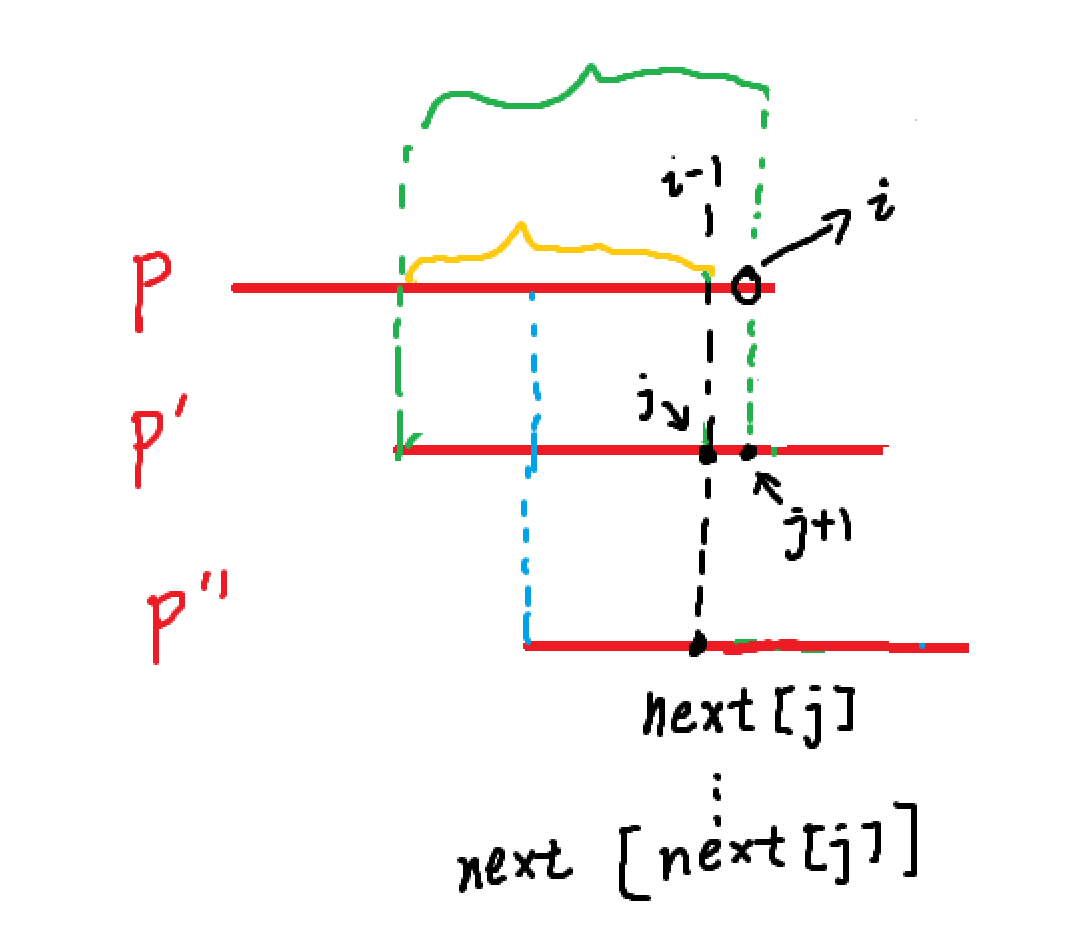
如上图所示,整个过程其实就是拿子串和子串自己配对
1. P->P':假设已经知道next[i-1](黄色那段),现在想求next[i](绿色那段),比较一下p[i]和p[j+1],如果相等,j++
2. 如果不相等,那么就要将子串回退,回退到什么情况呢,就和之前匹配一样的,让子串的后缀变前缀就行,就是P''所示的情况。这个时候,只需让j = next[j]就行。
3. 最后让next[i]=j就行了。
3 具体代码实现
其实KMP具体写法上有各种各样的,但是我个人比较喜欢这么写
#include <iostream>
using namespace std;
int n,m;
const int N = 1e5+10, M = 1e6+10;
char s[M], p[N];
int ne[N]; //ne代表next,next会与头文件中已有的关键字冲突
int main()
{
cin>>n>>p+1>>m>>s+1; //字符串从下标1开始存
//求next数组
for (int i = 2, j = 0; i <= n; i++) //这里的i,j都是用于子串p的遍历,但是i从2开始
{ //因为这里字符串从1开始存,ne[1]一定是0,所以从2开始遍历就行了
while(j && p[i] != p[j+1]) j = ne[j]; //只要有不匹配的就要回退
if(p[i] == p[j+1]) j++; //匹配上了就自增
ne[i] = j; //经过上面两个流程了,更新ne数组就行 !!!!!注意两种更新方法的不同
}
//字符匹配过程
for(int i = 1, j = 0; i <=m; i++) //i遍历s串,j遍历p串
{
while(j && s[i] != p[j+1]) j=ne[j]; //只要有不匹配的就要回退
if(s[i] == p[j+1]) j++; //匹配上了就自增
if(j == n) //子串完全匹配的情况
{
printf("%d ",i-n);
j = ne[j]; //注意这里不是j=0,而是j=ne[j] !!!!!注意两种更新方法的不同
}
}
return 0;
}
5 补充细节
- 字符串匹配中为什么最后是
j=ne[j],而不是j=[0]
如上图,假设当前
i-1处已经完全匹配完了子串,子串长度就只到P的j处,下一次重新匹配,仍然可以从公共前缀处接着开始,如果j=0,那么就会如P''所示,会漏掉P'的情况
- 为什么字符串要从下标1开始存储,next数组也是
我觉得是习惯问题,也见过从0开始存的,但是从1开始存,第一位可以当保留位,用作其他用途
- 为什么遍历的时候j都是从0开始的
其实j=0有点标志位的意思,只要j=0了就说明从头开始遍历了。j != 0的时候就说明已经有部分匹配了。同时在建立next数组的时候,由于ne[j] = j,当没有公共前后缀的时候,j自然而然的等于0,我个人更加容易理解。
- 为什么比较的时候用
j+1和i进行比较
next[j]的含义是:p[1,j]最长的公共前后缀长度,这里的切片是左闭右闭的,有些next[j]含义中是左闭右开的,所以还是习惯问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号