ElasticSearch搜索引擎(一)
目录
一、建索引需要了解
settings:配置信息
number_of_replicas: 0 不需要备份(单节点的ElasticSearch使用)
mappings: 映射内容
dynamic:false 是否动态索引,这里使用的是false,表示索引的固定的,不需要修改。
properties: 属性结构内容
index:true 是否设置分词
type:数据类型,text文本(长字符串),integer数字,date时间,keyword单词
analuzer:存储时使用的分词器
searchAnalyze:搜索时使用的分词器
store:是否存储
二、基础操作
1.添加索引

{
"mappings": {
"properties": {
"id": {
"type": "long",
"store": true,
"index": false
},
"title": {
"type": "text",
"store": true,
"index": true,
"analyzer": "standard"
},
"content": {
"type": "text",
"store": true,
"index": true,
"analyzer": "standard"
}
}
}
}
添加成功:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "blog2"
}
2.删除索引
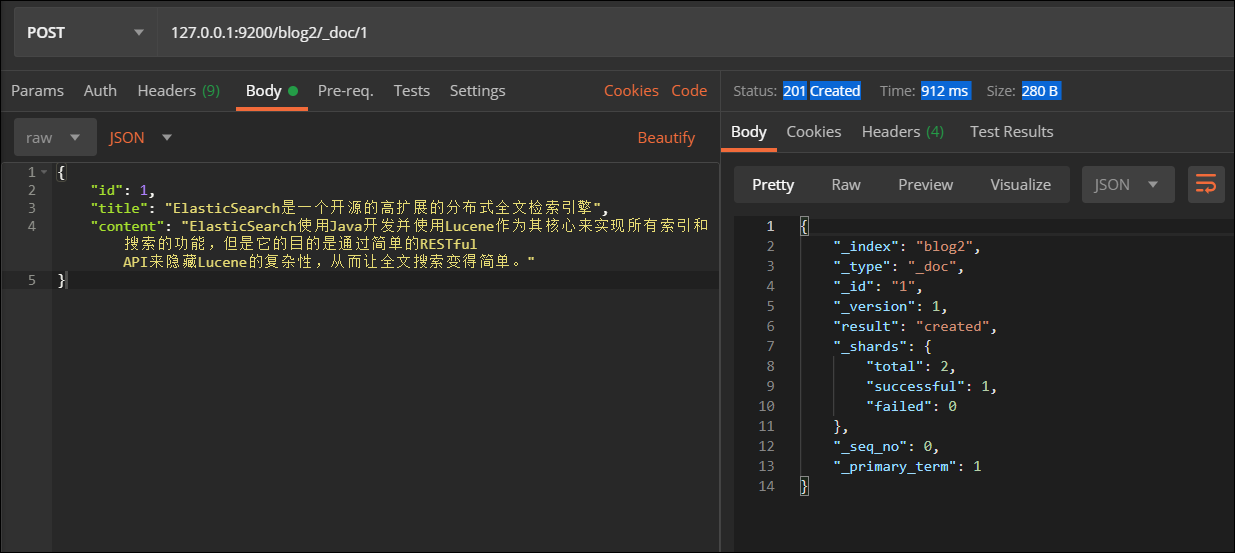
3.添加文档
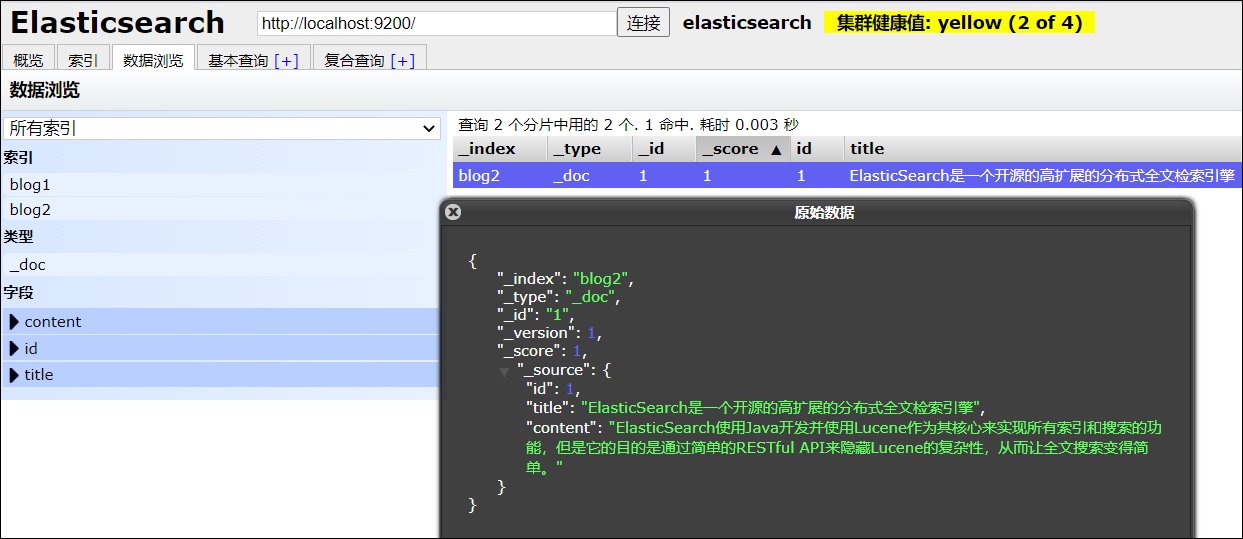
使用ElasticSearch-Head图形化工具查看
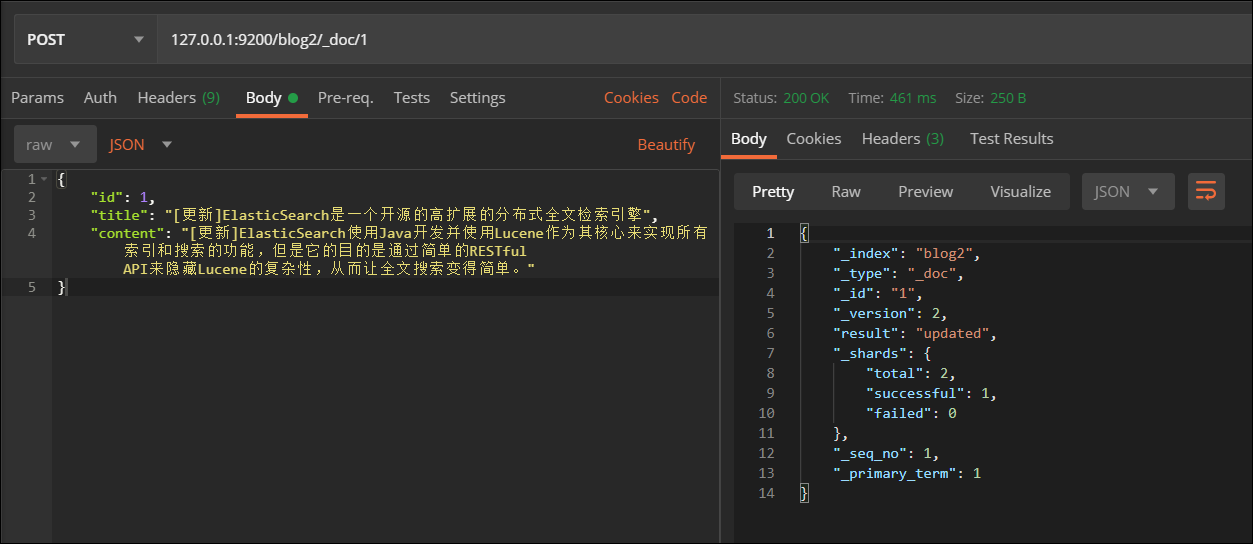
4.修改文档
查看

5.删除文档

6.查询文档
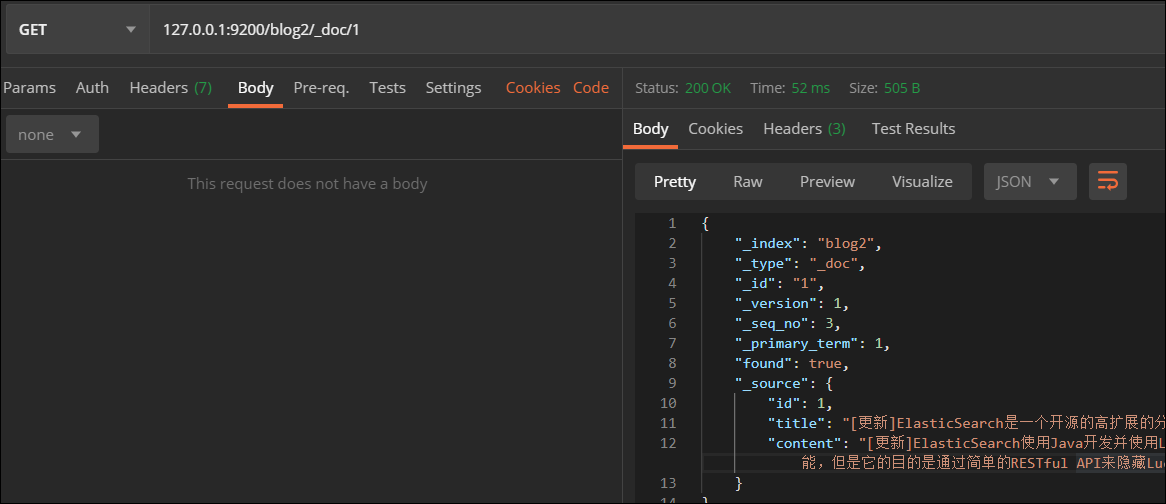
- 根据id查
- 根据QueryString
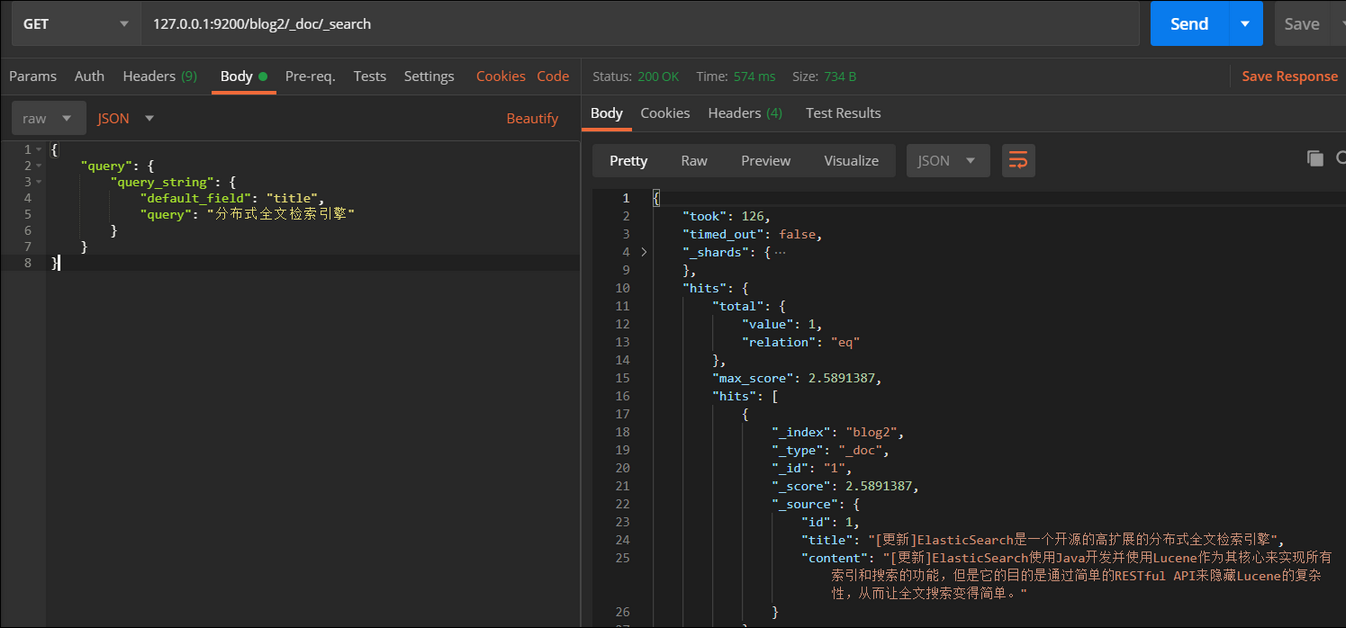
将搜索内容"分布式全文检索引擎"修改为"搜索",同样也能搜索到文档,这是为什么?
- term查询
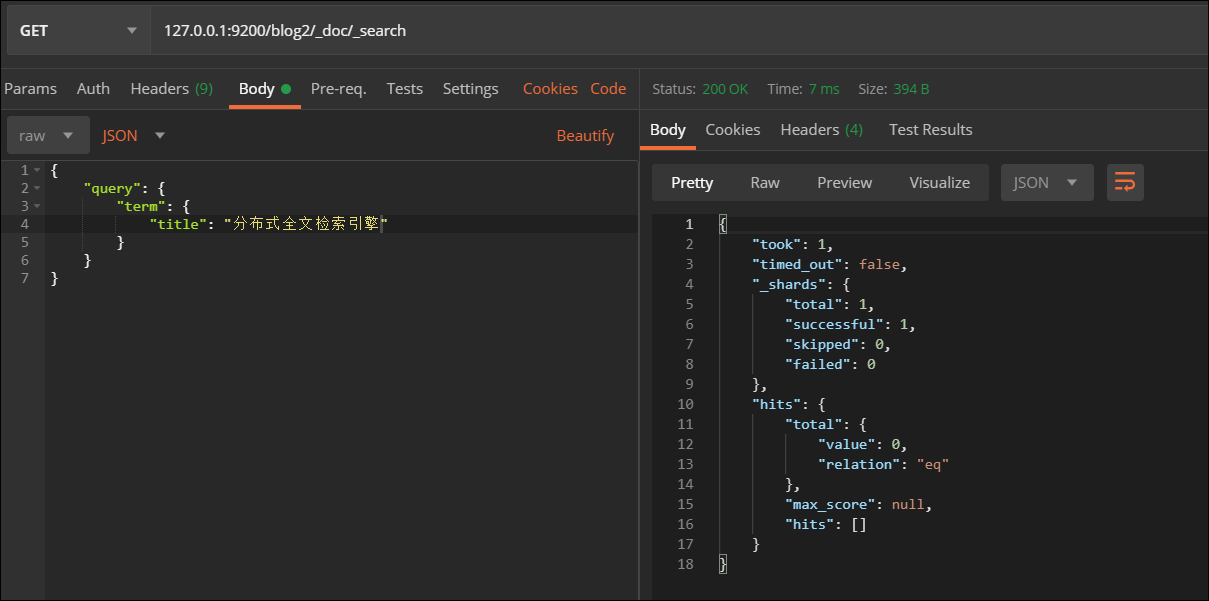
查询结果为0
将搜索内容"分布式全文检索引擎"修改为"搜索",同样也不能搜索到文档,这又是为什么?
三、IK分词器与ES集成
在进行字符串查询时,我们发现去搜索"搜索服务器"和"搜索"都可以搜索到数据,而在进行词条查询时,我们都没有搜索到数据;
究其原因是ElasticSearch的标准分词器导致的,当我们创建索引时,字段使用的是标准分词器:
"analyzer": "standard"
现对 "分布式全文检索引擎" 进行标准分词器分词 ,测试效果:

发现standard对中文的支持不够良好
1.IKAnalyzer简介
是一个开源的,基于java语言开发的轻量级的中文分词工具包。提供了对 Lucene的默认优化实现。
2.IK分词器安装
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases/
下载完成将解压到elasticsearch-7.5.2\plugins下,并重新启动es服务
3.IK分词器测试
IK提供了两个分词算法ik_smart 和 ik_max_word ,其中 ik_smart 为最少切分,ik_max_word为最细粒度划分
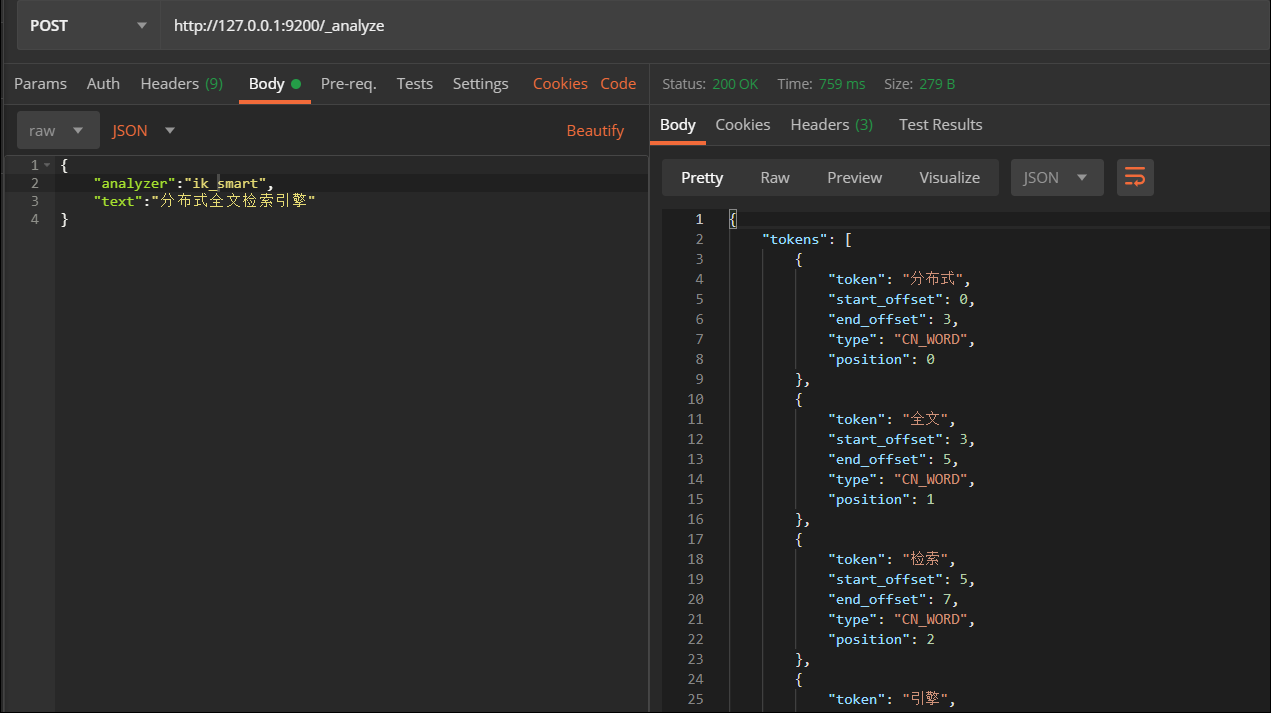
分词效果ik_smart 是:分布式—全文—检索—引擎,ik_max_word 是:分布式—分布—式—全文—检索—引擎,还是有区别的..
4.重新配置索引映射mapping并添加文档
"analyzer": "ik_max_word"
再次测试:
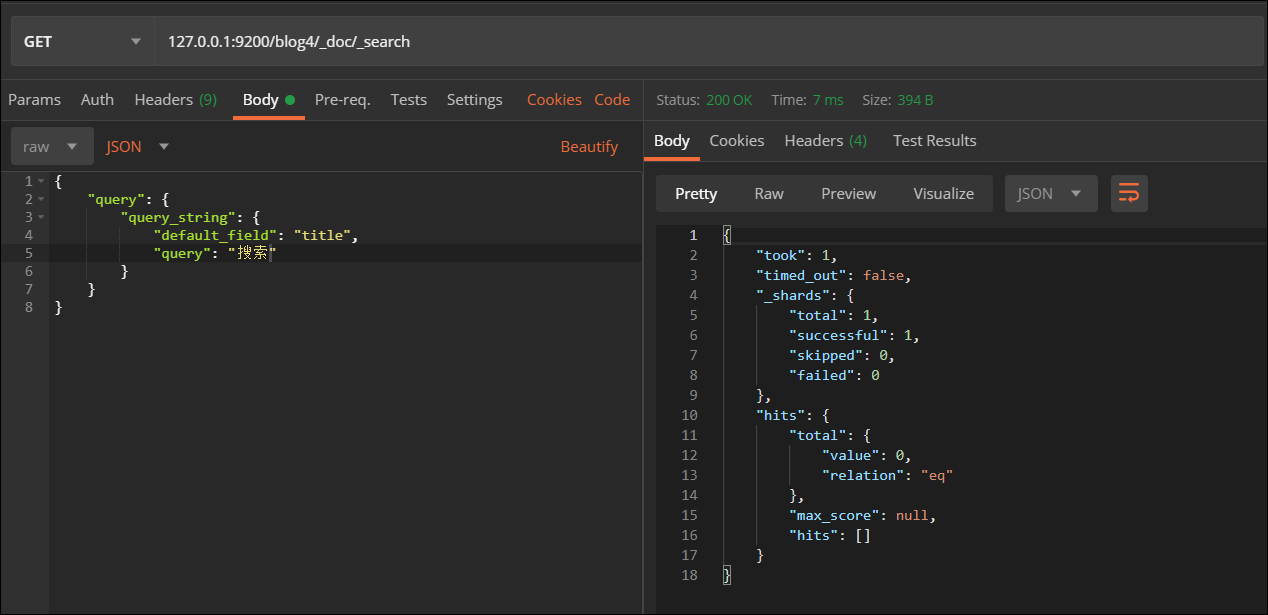
而用term就能搜索出来

 浙公网安备 33010602011771号
浙公网安备 33010602011771号