OLAP系统设计-向量化执行
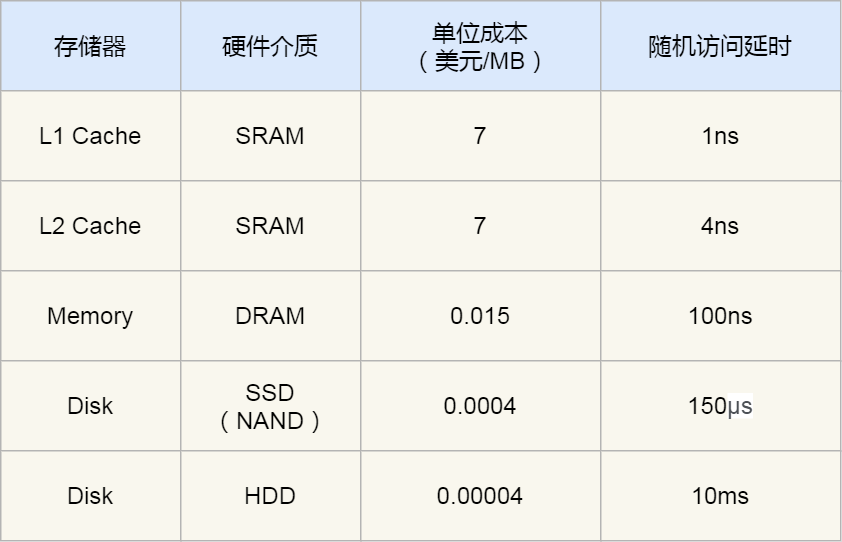
1.寄存器-> 缓存->内存->硬盘
只要能存储数据的器件都可以称之为存储器,它的含义覆盖了寄存器,缓存,内存,硬盘。
cpu访问快慢的速度依次为:寄存器-> 缓存->内存->硬盘
寄存器(register)是中央处理器的组成部分,是一种直接整合到cpu中的有限的高速访问速度的存储器,它是有一些与非门组合组成的,分为通用寄存器和特殊寄存器。cpu访问寄存器的速度是最快的。那为什么我们不把数据都存储到寄存器中呢,因为寄存器是一种容量有限的存储器,并且非常小。因此只把一些计算机的指令等一些计算机频繁用到的数据存储在其中,来提高计算机的运行速度。
缓存其实是内存中高速缓存(cache),它之所以存在,是因为当cpu要频繁访问内存中的一些数据时,如果每次都从内存中去读,花费的时间会更多,因此在寄存器和内存之间有了缓存,把cpu要频繁访问的一些数据存储在缓冲中,这样效率就会更高,但需要注意的是,缓冲的大小也是很小的,不能存放大量的数据,并且缓存中存放的数据会因为cpu的访问而被替代,必须某个数据开始被cpu频繁访问,但后来不再频繁,那这个数据的空间会被其他访问频繁的数据所占据(那些数据会被暂时存储在缓存中是算法问题)。缓存又可以分为一级和二级缓存,一级的速度大一二级的速度。因此cpu在访问数据时,先到缓存中看有没有,没有的话再到内存中读取。
内存分为只读(ROM)和随机存储器(RAM)一级最强悍的高速缓存存储器(cache)。其中RAM应用非常广泛,例如在平常用的开发板中的内存指的就是RAM,还有我们电脑上的内存条指的就是RAM。
硬盘、U盘等存储器都归入外存储器,它们的访问速度是最慢的。

2.向量化执行概念
向量体系结构使用一条向量指令开启一组数据操作,其中数据的加载、存储以及数据计算以流水线的形式进行。它最大的特点就是,其仅在一组数据操作的第一个元素存在存储器延迟和由冒险引起的停顿,后续元素会沿着流水线顺畅流动
主要是利用寄存器硬件层面的特性。
SIMD (Single Instruction Multiple Data) 即单条指令操作多条数据——原理即在CPU 寄存器层面实现数据的并行操作。
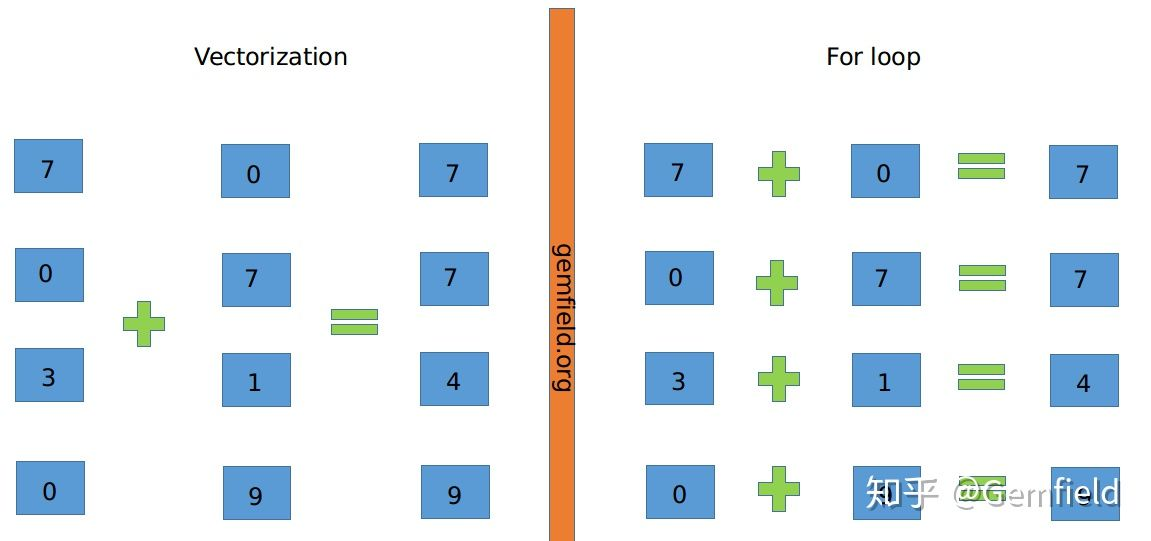
上图中,左侧为vectorization,右侧为寻常的For loop计算。将多次for循环计算变成一次计算完全仰仗于CPU的SIMD指令集,SIMD指令可以在一条cpu指令上处理2、4、8或者更多份的数据。在Intel处理器上,这个称之为SSE以及后来的AVX,在Arm处理上,这个称之为NEON。
因此简单来说,向量化计算就是将一个loop——处理一个array的时候每次处理1个数据共处理N次,转化为vectorization——处理一个array的时候每次同时处理8个数据共处理N/8次。
3.向量化执行设计-前提条件-列式存储
每列的数据存储在一起,可以认为这些数据是以数组的方式存储的,基于这样的特征,当该列数据需要进行某一同样操作,可以使用SIMD进一步提升计算效率。
ClickHouse 目前使用SSE4.2 指令集实现向量化执行
vectorization如何让速度更快?
我们以x86指令集为例,1997年,x86扩展出了MMX指令集,伴随着80-bit的vector寄存器,首开向量化计算的先河。 之后,x86又扩展出了SSE指令集 (有好几个版本, 从SSE1到SEE4.2),伴随着128-bit寄存器。而在2011年,Intel发布了Sandy Bridge架构——扩展出了AVX指令集(256-bit寄存器)。在2016年,第一个带有AVX-512寄存器的CPU发布了(512-bit寄存器,可以同时处理16个32-bit的float数)。SSE和AVX各有16个寄存器。SSE的16个寄存器为XMM0-XMM15,AVX的16个寄存器为YMM0-YMM15。XMM registers每个为128 bits,而YMM寄存器每个为256bit(AVX512为512bit)。
参考资料:1.https://zhuanlan.zhihu.com/p/72953129
2.https://zhuanlan.zhihu.com/p/55403951
3.https://www.sohu.com/a/428808782_298038
