hadoop主要概念的理解和学习_HDFS
1、概念与作用
HDFS,是一个分布式文件系统,用来解决海量数据的存储问题。
2、设计思路
1、分而治之/分块存储
(把一个大文件切分成多个小文件,每一个节点存储一部分小文件)
使用一个集群来联合存储这个文件
2、冗余存储
一个数据块存储多个副本。多个副本分散存储在多个不同的节点上。
提高副本数,有助于提高数据安全性
3、HDFS架构
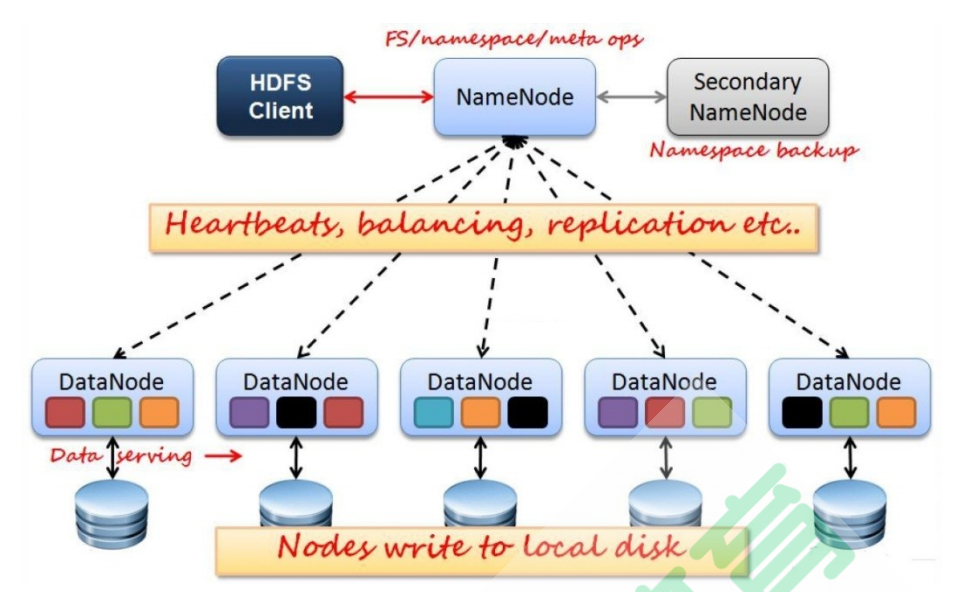
HDFS集群是一个典型的主从架构(Master/Slave架构)的分布式集群,它由四部分组成,
HDFSClient、
NameNode:集群老大,主要承担管理集群的任务,掌管HDFS文件系统的元数据(目录树+文件和数据块映射数据),处理客户端读写请求,HDFS集群内部数据安全和负载均衡等。
DataNode:主要承担存储真实数据的任务,存储整个集群中所有数据块,处理真正数据读写。
Secondary NameNode,主要给namenode分担压力,降低负载(元数据的编辑日志合并)之用。
4、元数据
5、HDFS优缺点
优点:
1)可构建在廉价机器上:通过多副本提高了可靠性,提供了容错和恢复机制
2)高容错性:数据自动保存多个副本,副本丢失后,自动恢复,增加副本,提高容错性,副本丢失,HDFS的内部机制可以自动恢复
3)适合批处理:移动计算而非数据,数据位置暴露给计算框架(引擎)
4)时候大数据处理:数据规模GB、TB、PB级别,文件规模 百万规模以上的文件梳理,节点规模 10K+ 节点规模
5)流式文件访问:一次性写入,多次读取
缺点,不适合以下操作
1)低延迟数据访问,比如毫秒级,HDFS是为了处理大型数据集分析任务的,主要是为达到高的数据吞吐量而设计的,这就可能要求以高延迟作为代价。
2)小文件存取,会占用 NameNode 大量内存 150b * 1000W = 15E,1.5G,寻道时间超过读取时间,存取大量小文件消耗大量的寻道时间,类比拷贝大量小文件与拷贝同等大小的一个大文件
3)并发写入、文件随机修改,一个文件只能有一个写者,仅支持 append,不支持修改和随机访问
6、怎么保证高效
1、机架感知,保证数据块的存放有一个最高效的策略
2、负载均衡
3、安全模式:
加载磁盘元数据(有多少文件,总共有多少数据块)
等待所有的datanode上线来汇报
4、Trash机制
5、Archeive归档解决海量小文件存储问题
6、执行流时数据访问
7、执行自动副本维护
namenode:存储和管理元数据
文件在HDFS
一个namenode要识别一个datanode宕机需要630s
7、搭建高可用的hadoop
8、使用shell、API方式操作HDFS
shell操作和linux文件操作差不多
api操作思路:
1.初始化一些环境配置
2.获取会话对象
3.通过会话对象进行各种操作
4.close...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号