hadoop安装
1.硬件准备
阿里云三台服务器,使用系统是centos6.9
2.安装
2.1安装jdk
1)jdk下载,在官网下载linux 64位的

下载到本地上传,或者使用wget下载 ,注意后面的AUTH信息每次需要自行改变
https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html

浏览器下载后获取地址
curl -O https://download.oracle.com/otn/java/jdk/8u261-b12/a4634525489241b9a9e1aa73d9e118e6/jdk-8u261-linux-x64.tar.gz?AuthParam=1600227784_d1d21d93eaccab801bd1324fb5089179
解压后
[root@iZ8vbikyhq14lnnku3lyegZ soft]# tar -zxvf jdk-8u261-linux-x64.tar.gz -C ../modules
配置环境变量
vi /etc/profile JAVA_HOME=/opt/modules/jdk PATH=$PATH:$JAVA_HOME/bin export JAVA_HOME PATH source /etc/profile [root@hadoop-001 jdk]# which java /opt/modules/jdk/bin/java
2)配置host互通
修改hostname
/etc/hosts:主机名查询静态表,是ip地址与域名快速解析的文件
格式
IP 主机名 域名 主机别名(一个IP有多个名字,可用空格隔离)
[root@iZ8vbikyhq14lnnku3lyegZ modules]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 172.20.5.0 hadoop01 [root@iZ8vbikyhq14lnnku3lyegZ modules]# hostname iZ8vbikyhq14lnnku3lyegZ [root@iZ8vbikyhq14lnnku3lyegZ modules]# hostname hadoop01 [root@iZ8vbikyhq14lnnku3lyegZ modules]# hostname hadoop01
这一步是最坑的,对于阿里云这种有固定IP的,这里不能配置外网IP,需要配置内网IP
[root@hadoop-001 jdk]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 172.24.67.124 hadoop-001 hadoop-001 39.100.128.158 hadoop-002 hadoop-002 39.100.146.104 hadoop-003 hadoop-003 [root@hadoop-001 jdk]# ping hadoop-003 PING hadoop-003 (39.100.146.104) 56(84) bytes of data. 64 bytes from hadoop-003 (39.100.146.104): icmp_seq=1 ttl=64 time=0.266 ms 64 bytes from hadoop-003 (39.100.146.104): icmp_seq=2 ttl=64 time=0.203 ms
新的配置
[hadoop@hadoop01 ~]$ cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 172.20.5.0 hadoop01 172.20.5.1 hadoop02 172.20.5.2 hadoop03
3)创建用户
[root@hadoop-001 jdk]# useradd hadoop [root@hadoop-001 jdk]# passwd hadoop Changing password for user hadoop. New password: BAD PASSWORD: it is based on a dictionary word BAD PASSWORD: is too simple Retype new password: passwd: all authentication tokens updated successfully. [root@hadoop-001 jdk]# chown -R hadoop:hadoop /opt/modules/ [root@hadoop-001 jdk]# ll /opt/ total 8 drwxr-xr-x 3 hadoop hadoop 4096 Sep 16 14:04 modules drwxr-xr-x 2 root root 4096 Sep 16 11:35 soft
授予sudo权限
[root@hadoop-001 jdk]# vi /etc/sudoers
90 ## Allow root to run any commands anywhere
91 root ALL=(ALL) ALL
92 hadoop ALL=(ALL) NOPASSWD: ALL
[root@hadoop-001 jdk]# su - hadoop
[hadoop@hadoop-001 ~]$ sudo mkdir /opt/test
[hadoop@hadoop-001 ~]$ ll /opt/
total 12
drwxr-xr-x 3 hadoop hadoop 4096 Sep 16 14:04 modules
drwxr-xr-x 2 root root 4096 Sep 16 11:35 soft
drwxr-xr-x 2 root root 4096 Sep 16 14:23 test
[hadoop@hadoop-001 soft]$ sudo chown -R hadoop:hadoop /opt/soft/ [hadoop@hadoop-001 soft]$ ll /opt/ total 12 drwxr-xr-x 3 hadoop hadoop 4096 Sep 16 14:04 modules drwxr-xr-x 2 hadoop hadoop 4096 Sep 16 14:34 soft drwxr-xr-x 2 root root 4096 Sep 16 14:23 test
2.2 安装hadoop
1)上传和解压
[hadoop@hadoop-001 soft]$ tar -zxvf hadoop-2.7.2.tar.gz -C ../modules/ [hadoop@hadoop-001 hadoop-2.7.2]$ sudo vi /etc/profile HADOOP_HOME=/opt/modules/hadoop-2.7.2 PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export JAVA_HOME PATH HADOOP_HOME [hadoop@hadoop-001 hadoop-2.7.2]$ source /etc/profile [hadoop@hadoop-001 hadoop-2.7.2]$ hadoop version Hadoop 2.7.2 Subversion Unknown -r Unknown Compiled by root on 2017-05-22T10:49Z Compiled with protoc 2.5.0 From source with checksum d0fda26633fa762bff87ec759ebe689c This command was run using /opt/modules/hadoop-2.7.2/share/hadoop/common/hadoop-common-2.7.2.jar
2.3.集群安装准备工作
1)三台机子免密登录(001免密登录002和003)
先完成hadoop用户
[hadoop@hadoop-001 ~]$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Created directory '/home/hadoop/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa. Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub. The key fingerprint is: aa:ad:73:ca:f5:ab:a9:a6:99:a4:29:93:28:84:f4:39 hadoop@hadoop-001 The key's randomart image is: +--[ RSA 2048]----+ | | | | | | | . | |o . . S | |.. E . | |o.. . o | |*+ +o+.o | |=.+o**+.o. | +-----------------+ [hadoop@hadoop-001 ~]$ ssh-copy-id hadoop-001 The authenticity of host 'hadoop-001 (172.24.67.124)' can't be established. RSA key fingerprint is ae:64:82:22:d7:6c:cb:ab:5d:d8:04:8c:fe:16:a7:ea. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'hadoop-001,172.24.67.124' (RSA) to the list of known hosts. hadoop@hadoop-001's password: Now try logging into the machine, with "ssh 'hadoop-001'", and check in: .ssh/authorized_keys to make sure we haven't added extra keys that you weren't expecting. [hadoop@hadoop-001 ~]$ ssh-copy-id hadoop-002 The authenticity of host 'hadoop-002 (39.100.128.158)' can't be established. RSA key fingerprint is ea:6f:0d:c6:43:18:36:34:e7:d3:c7:2b:c2:3a:17:5b. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'hadoop-002,39.100.128.158' (RSA) to the list of known hosts. hadoop@hadoop-002's password: Now try logging into the machine, with "ssh 'hadoop-002'", and check in: .ssh/authorized_keys to make sure we haven't added extra keys that you weren't expecting. [hadoop@hadoop-001 ~]$ ssh-copy-id hadoop-003 The authenticity of host 'hadoop-003 (39.100.146.104)' can't be established. RSA key fingerprint is ae:64:82:22:d7:6c:cb:ab:5d:d8:04:8c:fe:16:a7:ea. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'hadoop-003,39.100.146.104' (RSA) to the list of known hosts. Now try logging into the machine, with "ssh 'hadoop-003'", and check in: .ssh/authorized_keys to make sure we haven't added extra keys that you weren't expecting. [hadoop@hadoop-001 ~]$ ssh hadoop-002 ls /opt
再完成root用户
[hadoop@hadoop-001 bin]$ ssh-copy-id root@hadoop-001 root@hadoop-001's password: Now try logging into the machine, with "ssh 'root@hadoop-001'", and check in: .ssh/authorized_keys to make sure we haven't added extra keys that you weren't expecting. [hadoop@hadoop-001 bin]$ ssh-copy-id root@hadoop-002 root@hadoop-002's password: Now try logging into the machine, with "ssh 'root@hadoop-002'", and check in: .ssh/authorized_keys to make sure we haven't added extra keys that you weren't expecting. [hadoop@hadoop-001 bin]$ ssh-copy-id root@hadoop-003 root@hadoop-003's password: Now try logging into the machine, with "ssh 'root@hadoop-003'", and check in: .ssh/authorized_keys to make sure we haven't added extra keys that you weren't expecting.
切换到root用户下配置免密登录(因为部分操作使用root用户会比较方便)
[root@hadoop01 ~]# ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: de:9f:57:a5:41:ea:2e:6b:cc:e0:44:4f:69:74:18:e2 root@hadoop01 The key's randomart image is: +--[ RSA 2048]----+ | . .o | | . .o . . | | E. o o | | . + . . .| | .S+ . o.| | .o.. . . .| | o.+.. . | | . =.... | | ..oo. | +-----------------+ [root@hadoop01 ~]# ssh-copy-id hadoop01 The authenticity of host 'hadoop01 (172.20.5.0)' can't be established. RSA key fingerprint is 55:c0:b5:f5:65:73:f7:76:c5:4b:87:c9:0c:97:df:c7. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'hadoop01,172.20.5.0' (RSA) to the list of known hosts. root@hadoop01's password: Now try logging into the machine, with "ssh 'hadoop01'", and check in: .ssh/authorized_keys to make sure we haven't added extra keys that you weren't expecting. [root@hadoop01 ~]# ssh-copy-id hadoop02 The authenticity of host 'hadoop02 (39.99.132.211)' can't be established. RSA key fingerprint is 9d:13:8f:31:29:9b:11:b3:ef:ac:4e:3f:ec:da:6e:6f. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'hadoop02,39.99.132.211' (RSA) to the list of known hosts. root@hadoop02's password: Now try logging into the machine, with "ssh 'hadoop02'", and check in: .ssh/authorized_keys to make sure we haven't added extra keys that you weren't expecting. [root@hadoop01 ~]# ssh-copy-id hadoop03 The authenticity of host 'hadoop03 (39.99.129.254)' can't be established. RSA key fingerprint is 3b:84:38:db:ba:02:a9:5a:ed:b8:b6:84:ba:8a:c6:4a. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'hadoop03,39.99.129.254' (RSA) to the list of known hosts. root@hadoop03's password: Now try logging into the machine, with "ssh 'hadoop03'", and check in: .ssh/authorized_keys to make sure we haven't added extra keys that you weren't expecting.
2)编写同步文件脚本 xsync
#!/bin/bash #判断是否传参数,或者参数大于1 if(($#!=1)) then echo 请传入一个参数 exit; fi #获取文件的路径和文件名 dirname=$(cd `dirname $1`;pwd -P) filename=basename $1 echo 要分发的文件路径是$dirname/$filename for((i=2;i<4;i++)) do echo ------hadoop-00$i--------- rsync -rvlt $dirname/$filename hadoop@hadoop-00$i:$dirname done
3)no-login模式,让/etc/profile里面的环境变量生效
[hadoop@hadoop-001 ~]$ vi .bashrc [hadoop@hadoop-001 ~]$ tail .bashrc # .bashrc # Source global definitions if [ -f /etc/bashrc ]; then . /etc/bashrc fi # User specific aliases and functions source /etc/profile
4)编写同步执行命令
[hadoop@hadoop-001 bin]$ cat xcall #!/bin/bash #判断是否传入命令 if(($#==0)) then echo 请输入命令!!! exit fi #执行命令 for((i=1;i<4;i++)) do echo -----------hadoop-00$i------------ ssh hadoop-00$i $* done
因为path中包括/home/hadoop/bin,所以把脚本放在该目录下即可在任意地点执行 chmod u+x 脚本
hadoop@hadoop01 ~]$ mkdir bin [hadoop@hadoop01 ~]$ mv xcall xsync ./bin/ [hadoop@hadoop01 ~]$ cd bin/ [hadoop@hadoop01 bin]$ chmod u+x * [hadoop@hadoop01 bin]$ ll total 8 -rwxrw-r-- 1 hadoop hadoop 209 Oct 14 15:49 xcall -rwxrw-r-- 1 hadoop hadoop 388 Oct 14 15:48 xsync
把两个脚本同步到root用户下
[root@hadoop01 ~]# cp /home/hadoop/bin/* /usr/local/bin/ [root@hadoop01 ~]# ll /usr/local/bin/ total 8 -rwxr--r-- 1 root root 205 Oct 14 16:35 xcall -rwxr--r-- 1 root root 386 Oct 14 16:35 xsync
修改xsync,用户改为root
[root@hadoop01 ~]# cat /usr/local/bin/xsync
#!/bin/bash
#判断是否传参数,或者参数大于1
if(($#!=1))
then
echo 请传入一个参数
exit;
fi
#获取文件的路径和文件名
dirname=$(cd `dirname $1`;pwd -P)
filename=`basename $1`
echo 要分发的文件路径是$dirname/$filename
for((i=2;i<4;i++))
do
echo ------hadoop0$i---------
rsync -rvlt $dirname/$filename root@hadoop0$i:$dirname
done
[hadoop@hadoop-001 bin]$ echo $PATH
/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/opt/modules/jdk/bin:/opt/modules/hadoop-2.7.2/bin:/opt/m
odules/hadoop-2.7.2/sbin:/home/hadoop/bin
2.4规划
进程规划:核心、同质进程尽量分散
|
Hadoop-001 |
Hadoop-002 |
Hadoop-003 |
|
|
HDFS
|
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
|
YARN |
NodeManager |
ResourceManager NodeManager |
NodeManager |
2.5修改配置文件
1)core-site.xml
[hadoop@hadoop-001 hadoop]$ pwd
/opt/modules/hadoop-2.7.2/etc/hadoop
[hadoop@hadoop-001 hadoop]$ vi core-site.xml
[hadoop@hadoop-001 hadoop]$ tail -20 core-site.xml
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-001:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.7.2/data/tmp</value>
</property>
</configuration>
[hadoop@hadoop-001 hadoop]$ cd ..
[hadoop@hadoop-001 etc]$ cd ..
[hadoop@hadoop-001 hadoop-2.7.2]$ ll
total 52
drwxr-xr-x 2 hadoop hadoop 4096 May 22 2017 bin
drwxr-xr-x 3 hadoop hadoop 4096 May 22 2017 etc
drwxr-xr-x 2 hadoop hadoop 4096 May 22 2017 include
drwxr-xr-x 3 hadoop hadoop 4096 May 22 2017 lib
drwxr-xr-x 2 hadoop hadoop 4096 May 22 2017 libexec
-rw-r--r-- 1 hadoop hadoop 15429 May 22 2017 LICENSE.txt
-rw-r--r-- 1 hadoop hadoop 101 May 22 2017 NOTICE.txt
-rw-r--r-- 1 hadoop hadoop 1366 May 22 2017 README.txt
drwxr-xr-x 2 hadoop hadoop 4096 May 22 2017 sbin
drwxr-xr-x 4 hadoop hadoop 4096 May 22 2017 share
[hadoop@hadoop-001 hadoop-2.7.2]$ mkdir data
[hadoop@hadoop-001 hadoop-2.7.2]$ mkdir -p data/tmp
[hadoop@hadoop-001 hadoop-2.7.2]$
2)同步操作
环境变量
[hadoop@hadoop01 ~]$ xsync .bashrc 要分发的文件路径是/home/hadoop/.bashrc ------hadoop02--------- sending incremental file list .bashrc sent 217 bytes received 37 bytes 508.00 bytes/sec total size is 144 speedup is 0.57 ------hadoop03--------- sending incremental file list .bashrc sent 217 bytes received 37 bytes 508.00 bytes/sec total size is 144 speedup is 0.57
[root@hadoop01 ~]# xsync /etc/profile 要分发的文件路径是/etc/profile ------hadoop02--------- sending incremental file list profile sent 666 bytes received 49 bytes 1430.00 bytes/sec total size is 1985 speedup is 2.78 ------hadoop03--------- sending incremental file list profile sent 666 bytes received 49 bytes 1430.00 bytes/sec total size is 1985 speedup is 2.78
hadoop和jdk文件
xsync modules/
(1)如果集群是第一次启动,需要格式化NameNode
hadoop namenode -format
[hadoop@hadoop-001 tmp]$ tree
.
└── dfs
└── name
└── current
├── edits_0000000000000000001-0000000000000000002
├── edits_0000000000000000003-0000000000000000004
├── fsimage_0000000000000000000
├── fsimage_0000000000000000000.md5
├── seen_txid
└── VERSION
3 directories, 6 files
[hadoop@hadoop-001 tmp]$
(2)在001上面启动namenode
cd /opt/modules/hadoop-2.7.2/sbin/
[hadoop@hadoop-001 bin]$ hadoop-daemon.sh start namenode starting namenode, logging to /opt/modules/hadoop-2.7.2/logs/hadoop-hadoop-namenode-hadoop-001.out 查看日志 2020-09-17 22:01:34,101 ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode. java.net.BindException: Problem binding to [hadoop-001:9000] java.net.BindException: Cannot assign requested address; For more details see: http://wiki.apache.org/hadoop/BindException at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:792) at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:721) at org.apache.hadoop.ipc.Server.bind(Server.java:425) at org.apache.hadoop.ipc.Server$Listener.<init>(Server.java:574) at org.apache.hadoop.ipc.Server.<init>(Server.java:2215) at org.apache.hadoop.ipc.RPC$Server.<init>(RPC.java:938) at org.apache.hadoop.ipc.ProtobufRpcEngine$Server.<init>(ProtobufRpcEngine.java:534) at org.apache.hadoop.ipc.ProtobufRpcEngine.getServer(ProtobufRpcEngine.java:509) at org.apache.hadoop.ipc.RPC$Builder.build(RPC.java:783) at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.<init>(NameNodeRpcServer.java:344) at org.apache.hadoop.hdfs.server.namenode.NameNode.createRpcServer(NameNode.java:673) at org.apache.hadoop.hdfs.server.namenode.NameNode.initialize(NameNode.java:646) at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:811) at org.apache.hadoop.hdfs.server.namenode.NameNode.<init>(NameNode.java:795) at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1488) at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1554) Caused by: java.net.BindException: Cannot assign requested address at sun.nio.ch.Net.bind0(Native Method) at sun.nio.ch.Net.bind(Net.java:444) at sun.nio.ch.Net.bind(Net.java:436) at sun.nio.ch.ServerSocketChannelImpl.bind(ServerSocketChannelImpl.java:225) at sun.nio.ch.ServerSocketAdaptor.bind(ServerSocketAdaptor.java:74) at org.apache.hadoop.ipc.Server.bind(Server.java:408) ... 13 more 2020-09-17 22:01:34,103 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1 2020-09-17 22:01:34,104 INFO org.apache.hadoop.hdfs.server.namenode.NameNode: SHUTDOWN_MSG: /*********************************************************
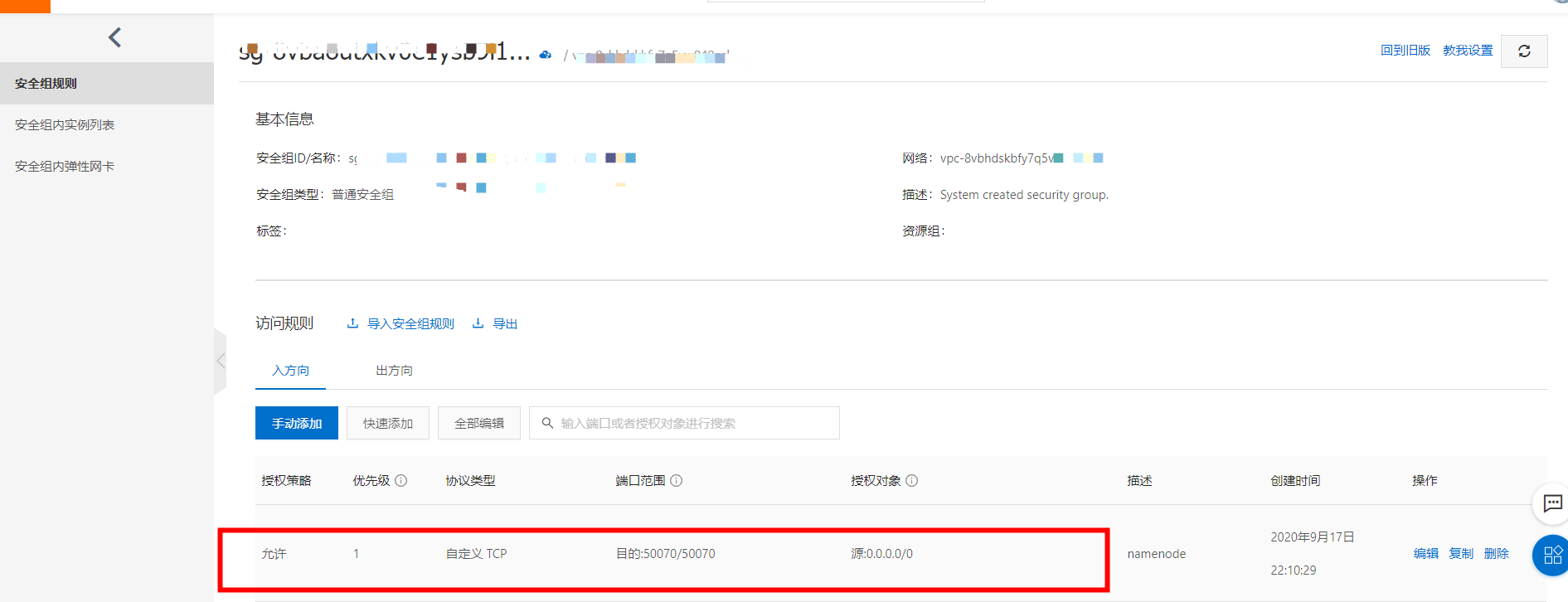
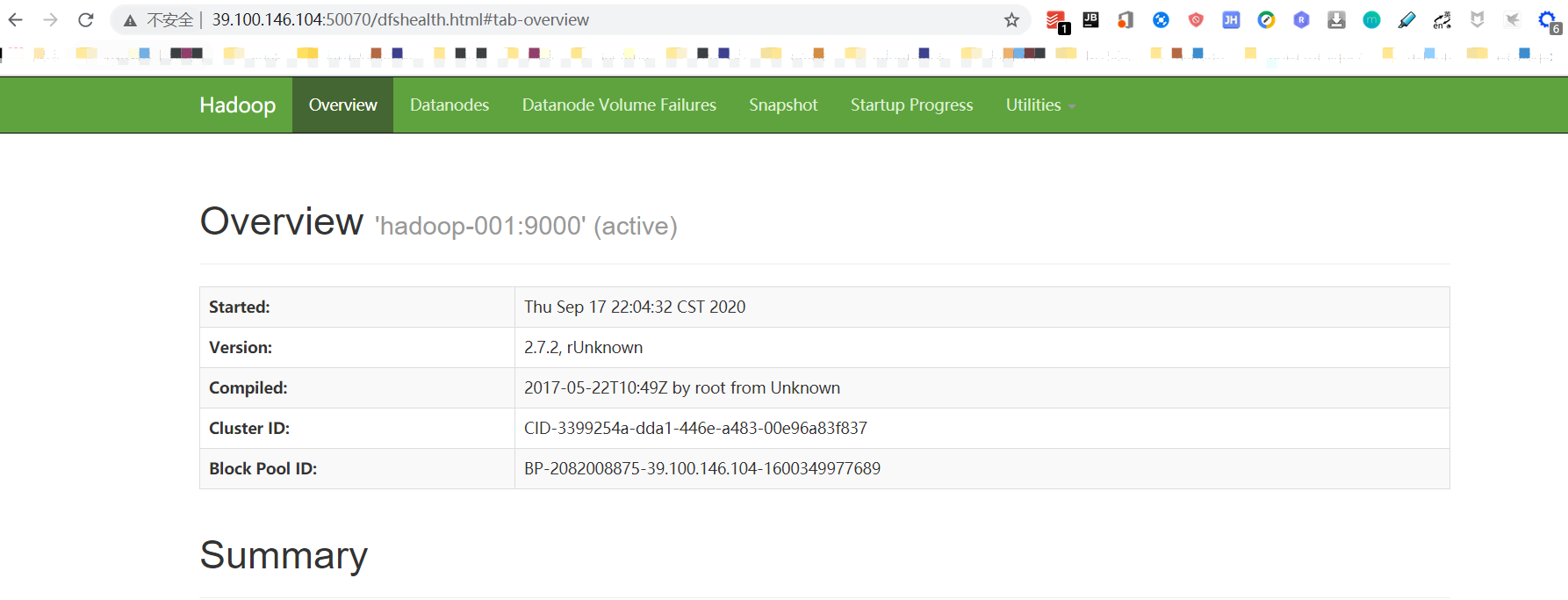
分析原因:阿里云服务器无法绑定公网IP的地址,在 /etc/hosts 中把主节点master节点里面的ip写成内网ip
重启后验证:
界面验证rpc9000对应的http是50070,需要在安全组中添加,
(2)启动其他节点的datanode,需要指定namenode,把001上的文件同步至002、003
xsync core-site.xml
[hadoop@hadoop-001 hadoop]$ xcall hadoop-daemon.sh start datanode -----------hadoop-001------------ starting datanode, logging to /opt/modules/hadoop-2.7.2/logs/hadoop-hadoop-datanode-hadoop-001.out -----------hadoop-002------------ starting datanode, logging to /opt/modules/hadoop-2.7.2/logs/hadoop-hadoop-datanode-hadoop-002.out -----------hadoop-003------------ starting datanode, logging to /opt/modules/hadoop-2.7.2/logs/hadoop-hadoop-datanode-hadoop-003.out [hadoop@hadoop-001 hadoop]$ xcall jps -----------hadoop-001------------ 16770 Jps 16686 DataNode 6191 NameNode -----------hadoop-002------------ 12439 DataNode 12509 Jps -----------hadoop-003------------ 14121 DataNode 14191 Jps
配置
secondarynamenode
vi /opt/modules/hadoop-2.7.2/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop03:50090</value>
</property>
</configuration>
vi yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop02</value>
</property>
</configuration>
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
同步
[hadoop@hadoop01 etc]$ xsync hadoop/ 要分发的文件路径是/opt/modules/hadoop-2.7.2/etc/hadoop ------hadoop02--------- sending incremental file list hadoop/ hadoop/.mapred-site.xml.swp hadoop/hdfs-site.xml hadoop/mapred-site.xml hadoop/yarn-site.xml sent 15282 bytes received 110 bytes 30784.00 bytes/sec total size is 89844 speedup is 5.84 ------hadoop03--------- sending incremental file list hadoop/ hadoop/.mapred-site.xml.swp hadoop/hdfs-site.xml hadoop/mapred-site.xml hadoop/yarn-site.xml sent 15282 bytes received 110 bytes 30784.00 bytes/sec total size is 89844 speedup is 5.84
启动脚本
在hadoop03上面启动secondarynamenode
hadoop-daemon.sh start secondarynamenode
yarn的启动
在hadoop02上启动resourcemanager
[hadoop@hadoop02 ~]$ yarn-daemon.sh start resourcemanager starting resourcemanager, logging to /opt/modules/hadoop-2.7.2/logs/yarn-hadoop-resourcemanager-hadoop02.out [hadoop@hadoop02 ~]$ jps 13688 DataNode 14154 Jps 13932 ResourceManager
在所有节点启动nodemanager
[hadoop@hadoop01 ~]$ xcall yarn-daemon.sh start nodemanager -----------hadoop01------------ starting nodemanager, logging to /opt/modules/hadoop-2.7.2/logs/yarn-hadoop-nodemanager-hadoop01.out -----------hadoop02------------ starting nodemanager, logging to /opt/modules/hadoop-2.7.2/logs/yarn-hadoop-nodemanager-hadoop02.out -----------hadoop03------------ starting nodemanager, logging to /opt/modules/hadoop-2.7.2/logs/yarn-hadoop-nodemanager-hadoop03.out [hadoop@hadoop01 ~]$ xcall jps -----------hadoop01------------ 4881 NodeManager 4610 NameNode 4722 DataNode 4989 Jps -----------hadoop02------------ 14305 Jps 13688 DataNode 14201 NodeManager 13932 ResourceManager -----------hadoop03------------ 14371 Jps 14070 SecondaryNameNode 14267 NodeManager 13948 DataNode
测试验证
[hadoop@hadoop01 ~]$ hadoop fs -mkdir /wcinput [hadoop@hadoop01 ~]$ echo "hi hi hi peter amy study hadoop and yarn">> hi [hadoop@hadoop01 ~]$ hadoop fs -put hi /wcinput/ [hadoop@hadoop01 ~]$ cd $HADOOP_HOME [hadoop@hadoop01 hadoop-2.7.2]$ cd share/hadoop/mapreduce/ [hadoop@hadoop01 mapreduce]$ ls hadoop-mapreduce-client-app-2.7.2.jar hadoop-mapreduce-client-hs-2.7.2.jar hadoop-mapreduce-client-jobclient-2.7.2-tests.jar lib hadoop-mapreduce-client-common-2.7.2.jar hadoop-mapreduce-client-hs-plugins-2.7.2.jar hadoop-mapreduce-client-shuffle-2.7.2.jar lib-examples hadoop-mapreduce-client-core-2.7.2.jar hadoop-mapreduce-client-jobclient-2.7.2.jar hadoop-mapreduce-examples-2.7.2.jar sources [hadoop@hadoop01 mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.7.2.jar wordcount /wcinput /wcoutput 20/10/15 10:35:47 INFO client.RMProxy: Connecting to ResourceManager at hadoop02/172.20.5.1:8032 20/10/15 10:35:48 INFO input.FileInputFormat: Total input paths to process : 1 20/10/15 10:35:49 INFO mapreduce.JobSubmitter: number of splits:1 20/10/15 10:35:49 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1602728522305_0001 20/10/15 10:35:49 INFO impl.YarnClientImpl: Submitted application application_1602728522305_0001 20/10/15 10:35:49 INFO mapreduce.Job: The url to track the job: http://hadoop02:8088/proxy/application_1602728522305_0001/ 20/10/15 10:35:49 INFO mapreduce.Job: Running job: job_1602728522305_0001 20/10/15 10:35:58 INFO mapreduce.Job: Job job_1602728522305_0001 running in uber mode : false 20/10/15 10:35:58 INFO mapreduce.Job: map 0% reduce 0% 20/10/15 10:36:05 INFO mapreduce.Job: map 100% reduce 0% 20/10/15 10:36:12 INFO mapreduce.Job: map 100% reduce 100% 20/10/15 10:36:12 INFO mapreduce.Job: Job job_1602728522305_0001 completed successfully 20/10/15 10:36:13 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=83 FILE: Number of bytes written=235065 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=137 HDFS: Number of bytes written=49 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=4273 Total time spent by all reduces in occupied slots (ms)=4884 Total time spent by all map tasks (ms)=4273 Total time spent by all reduce tasks (ms)=4884 Total vcore-milliseconds taken by all map tasks=4273 Total vcore-milliseconds taken by all reduce tasks=4884 Total megabyte-milliseconds taken by all map tasks=4375552 Total megabyte-milliseconds taken by all reduce tasks=5001216 Map-Reduce Framework Map input records=1 Map output records=9 Map output bytes=77 Map output materialized bytes=83 Input split bytes=96 Combine input records=9 Combine output records=7 Reduce input groups=7 Reduce shuffle bytes=83 Reduce input records=7 Reduce output records=7 Spilled Records=14 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=125 CPU time spent (ms)=940 Physical memory (bytes) snapshot=308670464 Virtual memory (bytes) snapshot=4131770368 Total committed heap usage (bytes)=170004480 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=41 File Output Format Counters Bytes Written=49 [hadoop@hadoop01 mapreduce]$
群起脚本:读取HADOOP_HOME/etc/hadoop/slaves 获取所有节点的主机名,ssh启动(免密登录,source /etc/profile)
start-yarn.sh 在集群非RM所在的机器使用,不会启动resourcemanager
建议在RM上执行群启脚本。

