数理统计13:非正态总体的区间估计,极限分布
上篇文章中,我们了解了枢轴量法,并用它处理了正态分布相关参数的区间估计。事实上,能给出正态分布参数较好形式的区间估计的原因,在于正态分布的点估计本身具有良好的性质——正态分布的可变换性、\(\chi^2\)分布的可加性、\(t\)分布和\(F\)分布具有分位数表、\(\bar X\)和\(S^2\)相互独立,等等。
本文,我们将探讨其他分布的区间估计。由于本系列为我独自完成的,缺少审阅,如果有任何错误,欢迎在评论区中指出,谢谢!
Part 1:指数分布与均匀分布
我们现在讨论的求区间估计的方法,都是基于良好点估计的。将这两种分布单独列出来,是因为其充分统计量:\(T=\sum_{j=1}^n X_j\)与\((X_{(1)},X_{(n)})\)的分布容易求得,故试想可以通过和正态分布相似的方法,找出其置信区间。
对于指数分布\(E(\lambda)\),要求\(\lambda\)的区间估计,因为\(\bar X\)是\(1/\lambda\)的UMVUE,所以\(\lambda\)的区间估计应当通过\(\bar X\)或\(T\)予以一定的变化求得。由于\(T\sim \Gamma(n,\lambda)\),所以\(2\lambda T\sim \chi^2(2n)\),故\(2\lambda T\)是一个枢轴量,容易找到一个区间,以\(1-\alpha\)的概率包含\(2\lambda T\)的观测值,取等尾区间即\(2\lambda T\in[\chi^2_{1-\alpha/2}(2n),\chi^2_{\alpha/2}(2n)]\),所以\(\lambda\)的\(1-\alpha\)置信区间是
rm(list=ls())
dev.off()
n <- 100 # 样本容量
lambda <- 5 # 指数分布的参数
l <- qchisq(0.025, df=2*n)
u <- qchisq(0.975, df=2*n)
upper.bound <- c()
lower.bound <- c()
for (j in 1:10000){
sumx <- sum(rexp(n, rate = lambda))
upper.bound[j] <- u / (2*sumx)
lower.bound[j] <- l / (2*sumx)
}
plot(1:10000, rep(lambda, 10000), ylim = c(2, 8), cex=0.1)
points(1:10000, upper.bound, col = 'red', cex=0.1)
points(1:10000, lower.bound, col = 'blue', cex=0.1)
sum(upper.bound < lambda | lower.bound > lambda)
在10000个观测值计算出的置信区间中,有502个区间没有包含真值。
对于均匀分布\(U(0,\theta)\),\(X_{(n)}\)为其充分完备统计量,由LS定理,\(\theta\)的UMVUE为
所以\(\theta\)的区间估计应该用\(T\)表示。取枢轴量为
故枢轴量的密度函数是
这里用到一个结论:随机变量倒数的密度。可以简单推导如下:若恒正随机变量\(X\sim F(x),p(x)\),则
\[\mathbb{P}\left(\frac{1}{X}\le x \right)=\mathbb{P}\left(X\ge \frac{1}{x}\right)=1-F\left(\frac{1}{x} \right), \]这里假设\(X\)是连续的,所以
\[p_{\frac{1}{X}}(x)=\frac{\mathrm{d}}{\mathrm{d}x}\left[1-F\left(\frac{1}{x} \right) \right]=p\left(\frac{1}{x} \right)\cdot\frac{1}{x^2}. \]
要找到一个区间以\(1-\alpha\)的概率包含\(\theta/T\)的观测值,就是找到上界和下界\(1\le c<d\),使得
关于如何选取这样的\(c,d\),我们可以设\(d=c+l\),为了使得精度最高,转化为这样的规划问题:
由于\(1/x^n\)是减函数,所以应当尽可能让\(c\)小,所以取\(c=1\)最佳,此时有\(d=\alpha^{-\frac{1}{n}}\),所以\(\theta\)的置信区间是
不过,并不是所有充分统计量都具有这么好的性质,对于离散型随机变量,或者一些较为复杂的连续分布,UMVUE的分布也比较复杂,我们只能给出一个近似的区间估计。
Part 2:极限分布
极限分布是针对统计量而言的,大多数统计量一定会包含样本容量\(n\)(否则充分多的抽样就没有意义),然而,当\(n\)具体等于某一个数\(n_0\)时,统计量的分布可能很复杂,不易求出。统计量的极限分布,指的是当样本容量趋向于无穷时,统计量的分布如果会趋近一个确定的分布,就称这个确定分布是该统计量的极限分布。
注意,极限分布与无穷是密不可分的,如果没有趋于无穷的过程,则无论样本容量\(n\)是多大,都不能称为极限分布。同样,随着样本容量的无限增大,统计量可能表现出一些性质,比如依概率收敛于某个点(即相合性)等等,这就被称为大样本性质,它也依赖于样本大小趋于无穷的要求。
中心极限定理是用于理解极限分布的最好工具,它指出,如果某个总体\(X\)的期望\(\mu\)和方差\(\sigma^2\)存在,则从总体\(X\)中抽取的样本\(\boldsymbol{X}=(X_1,\cdots,X_n)\)具有如下的性质:
当\(\sigma\)和\(\mu\)均为已知量时,等式左边的量是给定样本就可以计算出的量,因而是统计量,如果将这个统计量记作\(T\),则随着样本容量的趋于无穷,\(T\)的分布会趋向于标准正态分布。
大数定律也是随着样本容量趋于无穷才会表现出来的性质,它指出,如果某个总体\(X\)的期望\(\mu\)存在,则从总体\(X\)种抽取的样本\(\boldsymbol{X}=(X_1,\cdots,X_n)\)具有如下的性质:
不论\(\mu\)是否已知,\(\bar X\)均为统计量,因此单点分布\(\mu\)就是\(\bar X\)的极限分布。事实上,由中心极限定理可以知道\(\bar X\sim N(\mu,\sigma^2/n)\),随着\(n\)趋向于无穷大,方差趋向于\(0\),自然就是单点分布。
柯尔莫哥洛夫强大数定律又将样本均值对总体均值的收敛增强为几乎必然的。
由于中心极限定理对分布族的约束很少,只要求其存在一阶矩和二阶矩,大数定律的约束则更少,因而它的应用很广泛。我们还要提出Slutsky引理,这个定理将中心极限定理和大数定律联系在一起。
Slutsky引理:令\(\{X_n\}\)和\(\{Y_n\}\)是两个随机变量列,满足\(n\to \infty\)时\(X_n\stackrel{d}\to X\),\(Y_n\stackrel{P}\to c\),则有
- \(X_n\pm Y_n\stackrel{d}\to X\pm c\)。
- \(X_nY_n\stackrel{d}\to cX\)。
- 若\(c\ne 0\),则\(X_n/Y_n\stackrel{d}\to X/c\)。
我们将在接下来的部分中,给出Slutsky引理的应用。
Part 3:大样本下的区间估计
对于一些小样本下不好解决的区间估计问题,使用极限分布,就可以给出近似置信水平的区间估计。以下以二项分布和泊松分布为例。
首先是二项分布\(B(1,p)\)的参数\(p\),求其\(1-\alpha\)置信区间,如果利用\(T=\sum_{j=1}^n X_j\sim B(n,p)\)构造枢轴量会比较麻烦,因而考虑大样本方法,使用中心极限定理、大数定律和Slutsky引理给出区间估计。
注意到
所以可以构建如下的枢轴量:
于是,\(p\)的\(1-\alpha\)置信区间就是
在\(n=100\),\(p=0.4\)的情况下,10000个观测区间有532个落入了所求的置信区间,置信区间的平均长度为\(0.191\)。
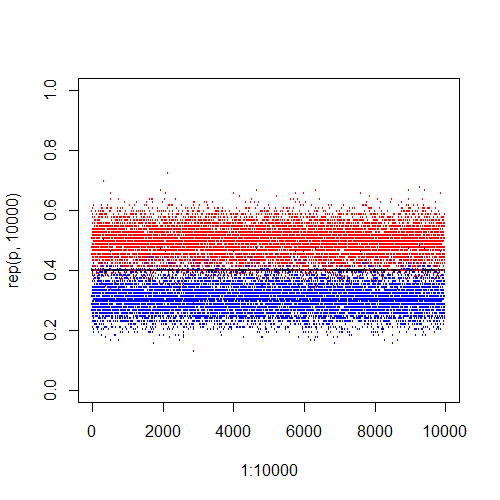
事实上,
\[\frac{\sqrt{n}(\bar X-p)}{\sqrt{p(1-p)}}\stackrel{d}\to N(0,1) \]已经是一个枢轴量,并且从中可以反解出\(p\)与\(\bar X\)之间的关系,只是比较复杂。书上给出了按照这种方式构造的置信区间为\([c_1,c_2]\):
\[c_1,c_2=\frac{n}{n+u_{\alpha/2}^2}\left[\bar X+\frac{u_{\alpha/2}^2}{2n}\pm u_{\alpha/2}\sqrt{\frac{\bar X(1-\bar X)}{n}+\frac{u_{\alpha/2}^2}{4n^2}} \right]. \]不妨也用这个置信区间看看效果,在相同的参数下,有488个样本观测值生成的置信区间不包括参数真值,区间的平均长度是\(0.188\)。因此,这个置信区间的效果确实比二次近似的效果稍好,但是复杂得太多了。
再看泊松分布,设\(X\sim P(\lambda)\),则
同样,这已经是一个枢轴量,但我们会使用Slutsky引理对其简化,得到
所以\(\lambda\)的\(1-\alpha\)置信区间为
更一般地,使用极限分布构造\(\theta\)的近似置信区间在很多情况下是可行的,这依赖于以下事实:\(\theta\)的极大似然估计\(\hat\theta_n\)有渐进正态分布:
\[\sqrt{\frac{n}{I(\theta)}}(\hat\theta_n-\theta)\stackrel{d}\to N(0,1). \]这里\(I(\theta)\)是信息函数,即
\[I(\theta)=\mathbb{E}\left[\left(\frac{\partial \ln f(x;\theta)}{\partial\theta}\right)^2 \right]. \]令\(\sigma^2(\theta)=\frac{1}{I(\theta)}\),则由Slutsky引理,可以得到\(\theta\)的\(1-\alpha\)置信区间为:
\[\left[\hat\theta_n-\frac{u_{\alpha/2}}{\sqrt{n}}\sigma(\hat\theta_n),\hat\theta_n+\frac{u_{\alpha/2}}{\sqrt{n}}\sigma(\hat\theta_n) \right]. \]这是一个通用性的结论,但不是很有必要记忆,只需在遇到实际问题时知道极限分布的使用即可。
以上两个例子中,\(p\)和\(\lambda\)都是总体的均值,故中心极限定理会得出\(\bar X\)与参数的对称形式。有时候,总体的均值并不显式地体现在某些参数中,这就是非参数估计。现在给定一个分布\(F\),只知道其均值\(\mu\)和方差\(\sigma^2\)是存在的,要如何对总体均值\(\mu\)进行估计?一样可以使用中心极限定理,由于
这里\(\bar X\)和\(S^2\)分别是样本均值和样本方差,所以
于是可以给出\(\mu\)的近似\(1-\alpha\)置信区间为
柯西分布是一种特殊的参数分布,其分布族为
\[f(x;\theta)=\frac{1}{\pi[1+(x-\theta)^2]},\quad x\in\mathbb{R},\theta\in\mathbb{R}. \]这里参数\(\theta\)是总体中位数。由于柯西分布不存在矩,故中心极限定理不再适用,这种情况下应当如何给出总体中位数的区间估计呢?令\(m_n\)为\(\boldsymbol{X}=(X_1,\cdots,X_n)\)的样本中位数,则显然
\[m_n-\theta\stackrel{d}= \theta_0, \]是一个枢轴量,这里\(\theta_0\)是\(\theta=0\)时柯西分布的样本中位数,与参数\(\theta\)无关。
这里,我们需要一个与样本中位数相关的引理,设总体\(f\)的中位数是\(\xi\),即\(\int_{-\infty}^\xi f(x)\mathrm{d}x=0.5\),且\(\xi\)在以上积分定义下唯一,则对于样本分位数\(m\),有
\[2\sqrt{n}f(\xi)(m-\xi)\stackrel{d}\to N(0,1). \]在具体的柯西分布下,有
\[\frac{2\sqrt{n}}{\pi}(m_n-\theta)\stackrel{d}\to N(0,1), \]于是\(\theta\)的\(1-\alpha\)置信区间是
\[\left[m_n-\frac{\pi}{2\sqrt{n}}u_{\alpha/2},m_n+\frac{\pi}{2\sqrt{n}}u_{\alpha/2} \right]. \]
事实上,区间估计理论中还有Fisher的信仰推断法,但这种方法的争议尚未停止,我也不是很了解,所以在这里就跳过。从下一篇文章开始,我们就进入数理统计的另一个步骤:假设检验。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号