
MySQL复习 - 2023/5/21
SQL 语句可以写成一行,也可以分写为多行。
CRUD
INSERT
INSERT INTO 表名 VALUES()
INSERT INTO 表名(字段1,字段2...) VALUES()
UPDATE
UPDATE user SET username='root' , password = '123' where id = 1
DELETE
DELETE FROM user where username='root'
清空表中数据
TRUNCATE TABLE USER
SELECT
DISTINCT 去重
LIMIT 限制返回行数 (起始行,返回行数) (返回行数)
select * from user
select id,username from user
select username form user DISTINCT
select * from user LIMIT 5 = select * from user LIMIT 0,5
排序
order by 字段1 DES/ASC,字段2 DES/ASC
DES是升序,ASC是降序
select * from user order by id DES, time ASC
分组
group by
group by 字句将记录分组到汇总行中
group by 为每个组返回一个记录
group by 能搭配聚合 count max sum avg 使用
group_concat(字段) 显示group by出来的字段
select username from user having age > 20 group by age having count(*) >3
查询年龄大于20,且同年龄段人数大于3的第一个人的名字
having 用于过滤group by后的数据
也可以和where连用,先用where过滤一次查询结果,再用group by 来分组汇总,最后过滤分组后的数据,having能够搭配聚合函数使用
子查询
可以嵌入CRUD 以及 连同 = < > IN BETWEEN EXISTS 使用
select id,username,age from user where id = (select id from user where id >200)
//in表示后面子查询的id的集合中查询
SELECT log_id,log_name FROM tb_log_browsing as A WHERE log_id in (SELECT log_id FROM tb_log_browsing as B WHERE B.log_id > 400 )
//exists 会先查询前面的 , 然后将前面查询的缓存的每一条数据都用作后面的子查询,如果前面的条件扔到后面,比如A.log_id>400在后面的子查询中能够查询到,会返回true,那么这条数据有效,保留,如果查询为空,返回false,不保存。
SELECT log_id,log_name FROM tb_log_browsing as A WHERE EXISTS (SELECT 'x' FROM tb_log_browsing as B WHERE A.log_id > 400 )
如果是子查询的表比较大,用exists比较好,如果是子查询的表比较小,那么用in 比较好
连接方式
一般内联,左外,右外,全外记得就好,笛卡尔积
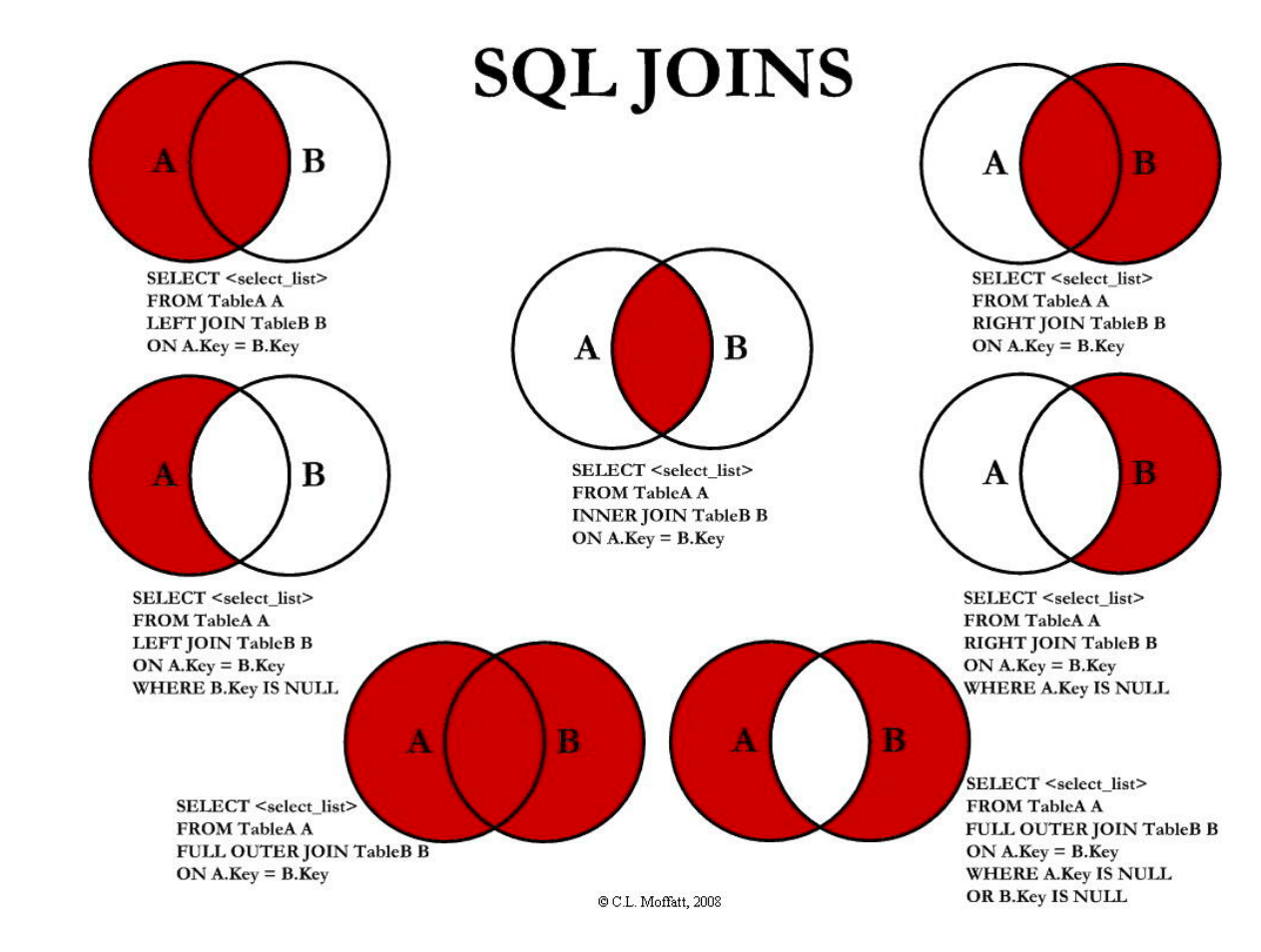

n行的表 与 m行的表进行笛卡尔积连接 , 会形成 x*m行的表
组合
UNION 运算符将两个或更多查询的结果组合起来,并生成一个结果集,其中包含来自 UNION 中参与查询的提取行。
UNION 基本规则:
- 所有查询的列数和列顺序必须相同。(查询结果集内容必须是相同的)
- 每个查询中涉及表的列的数据类型必须相同或兼容。
- 通常返回的列名取自第一个查询。
SELECT id,username FROM user
UNION ALL
SELECT employeeid,employeename FROM employee
从用户表中查询id和名称,再与员工表中的id和名称相组合,可以查询出普通用户和员工的集合
视图
视图主要是为了先进行一些复杂的连表操作,然后整理出一部分需要使用到的数据,我们可以根据这个数据来访问,但是不能对视图进行索引等。
创建视图
CREATE VIEW top_10_user_view AS
SELECT id, username
FROM user
WHERE id < 10;
包含了用户的id和用户名,且id是小于10的,之后我们对用户表进行删改,视图查询的结果也是一样的,当我们在实际表中将视图中的记录的内容进行删除时,再次查询视图,结果是能够实时地反应出真实表的情况的
DROP VIEW top_10_user_view;
索引
索引是一种用于快速查询和检索数据的数据结构,其本质可以看成是一种排序好的数据结构。
索引的作用就相当于书的目录。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
优点:
- 使用索引可以大大加快 数据的检索速度(大大减少检索的数据量), 这也是创建索引的最主要的原因。
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
缺点:
- 创建索引和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低 SQL 执行效率。
- 索引需要使用物理文件存储,也会耗费一定空间。
事务处理
不能回退 SELECT 语句,回退 SELECT 语句也没意义;也不能回退 CREATE 和 DROP 语句。
MySQL 默认是隐式提交,每执行一条语句就把这条语句当成一个事务然后进行提交。当出现 START TRANSACTION 语句时,会关闭隐式提交;当 COMMIT 或 ROLLBACK 语句执行后,事务会自动关闭,重新恢复隐式提交。
通过 set autocommit=0 可以取消自动提交,直到 set autocommit=1 才会提交;autocommit 标记是针对每个连接而不是针对服务器的。
指令:
START TRANSACTION- 指令用于标记事务的起始点。SAVEPOINT- 指令用于创建保留点。ROLLBACK TO- 指令用于回滚到指定的保留点;如果没有设置保留点,则回退到START TRANSACTION语句处。COMMIT- 提交事务。
start transaction
insert into user values(1,"root")
savepoint update1
insert into user values(2,"ll")
rollback to update1
commit
只会保存1"root,后面的2,ll的数据被回滚了,不会commit
存储过程
优点:代码封装,保证安全性; 代码可以服用 ; 预先编译,性能高。
阿里巴巴的 JAVA开发手册 禁止使用,因为难以调试、拓展,也没有移植性,基本只能针对特定的库、表写
与函数的区别是,函数有返回值
创建一个存储过程
DROP PROCEDURE IF EXISTS `proc_adder`;
DELIMITER ;;
CREATE DEFINER=`root`@`localhost` PROCEDURE `proc_adder`(IN a int, IN b int, OUT sum int)
BEGIN
DECLARE c int;
if a is null then set a = 0;
end if;
if b is null then set b = 0;
end if;
set sum = a + b;
END
;;
DELIMITER ;
//执行
set @b = 5;
call proc_adder(2,@b,@s);//需要传出的值最好传进去 然后有定式 OUT,名称为sum
select @s as sum
游标
游标(cursor)是一个存储在 DBMS 服务器上的数据库查询,它不是一条 SELECT 语句,而是被该语句检索出来的结果集。
在存储过程中使用游标可以对一个结果集进行移动遍历。
游标主要用于交互式应用,其中用户需要滚动屏幕上的数据,并对数据进行浏览或做出更改。
使用游标的几个明确步骤:
-
在使用游标前,必须声明(定义)它。这个过程实际上没有检索数据, 它只是定义要使用的
SELECT语句和游标选项。 -
一旦声明,就必须打开游标以供使用。这个过程用前面定义的 SELECT 语句把数据实际检索出来。
-
对于填有数据的游标,根据需要取出(检索)各行。
-
在结束游标使用时,必须关闭游标,可能的话,释放游标(有赖于具
体的 DBMS)。
可以写在存储过程中
-- 创建游标 DECLARE cur CURSOR FOR SELECT id,name,age from cursor_table where age>30; -- 指定游标循环结束时的返回值 DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = true; SET total = 0; OPEN cur; FETCH cur INTO sid, sname, sage; WHILE(NOT done) DO SET total = total + 1; FETCH cur INTO sid, sname, sage; END WHILE; CLOSE cur;
触发器
如果我想做到在一个用户注销后,在另一个关联的用户VIP表中删除他的信息,那么就会使用到触发器
触发器是一种与表操作有关的数据库对象,当触发器所在表上出现指定事件时,将调用该对象,即表的操作事件触发表上的触发器的执行。
我们可以使用触发器来进行审计跟踪,把修改记录到另外一张表中。
使用触发器的优点:
- SQL 触发器提供了另一种检查数据完整性的方法。
- SQL 触发器可以捕获数据库层中业务逻辑中的错误。
- SQL 触发器提供了另一种运行计划任务的方法。通过使用 SQL 触发器,您不必等待运行计划任务,因为在对表中的数据进行更改之前或之后会自动调用触发器。
- SQL 触发器对于审计表中数据的更改非常有用。
使用触发器的缺点:
- SQL 触发器只能提供扩展验证,并且不能替换所有验证。必须在应用程序层中完成一些简单的验证。例如,您可以使用 JavaScript 在客户端验证用户的输入,或者使用服务器端脚本语言(如 JSP,PHP,ASP.NET,Perl)在服务器端验证用户的输入。
- 从客户端应用程序调用和执行 SQL 触发器是不可见的,因此很难弄清楚数据库层中发生了什么。
- SQL 触发器可能会增加数据库服务器的开销。
MySQL 不允许在触发器中使用 CALL 语句 ,也就是不能调用存储过程。
注意:在 MySQL 中,分号 ; 是语句结束的标识符,遇到分号表示该段语句已经结束,MySQL 可以开始执行了。因此,解释器遇到触发器执行动作中的分号后就开始执行,然后会报错,因为没有找到和 BEGIN 匹配的 END。这时就会用到 DELIMITER 命令(DELIMITER 是定界符,分隔符的意思)。它是一条命令,不需要语句结束标识,语法为:DELIMITER new_delemiter。new_delemiter 可以设为 1 个或多个长度的符号,默认的是分号 ;,我们可以把它修改为其他符号,如 $ - DELIMITER $ 。在这之后的语句,以分号结束,解释器不会有什么反应,只有遇到了 $,才认为是语句结束。注意,使用完之后,我们还应该记得把它给修改回来。
NEW 和 OLD:MySQL 中定义了 NEW 和 OLD 关键字,用来表示触发器的所在表中,触发了触发器的那一行数据。在 INSERT 型触发器中,NEW 用来表示将要(BEFORE)或已经(AFTER)插入的新数据;在 UPDATE 型触发器中,OLD 用来表示将要或已经被修改的原数据,NEW 用来表示将要或已经修改为的新数据;在 DELETE 型触发器中,OLD 用来表示将要或已经被删除的原数据;使用方法:NEW.columnName (columnName 为相应数据表某一列名
用户表中删除一个用户,将VIP信息表中的该用户也删除
DELIMITER $
CREATE TRIGGER trigger_1
AFTER DELETE ON 'user'
FOR EACH ROW
BEGIN
DELETE FROM 'vip_info' where user_id = OLD.id;
END;
DELIMITER ;
查看触发器
SHOW TRIGGERS;
删除触发器
DROP TRIGGER IF EXISTS trigger_1
参考资料
https://javaguide.cn/database/sql/sql-syntax-summary.html JAVA Guide
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号