
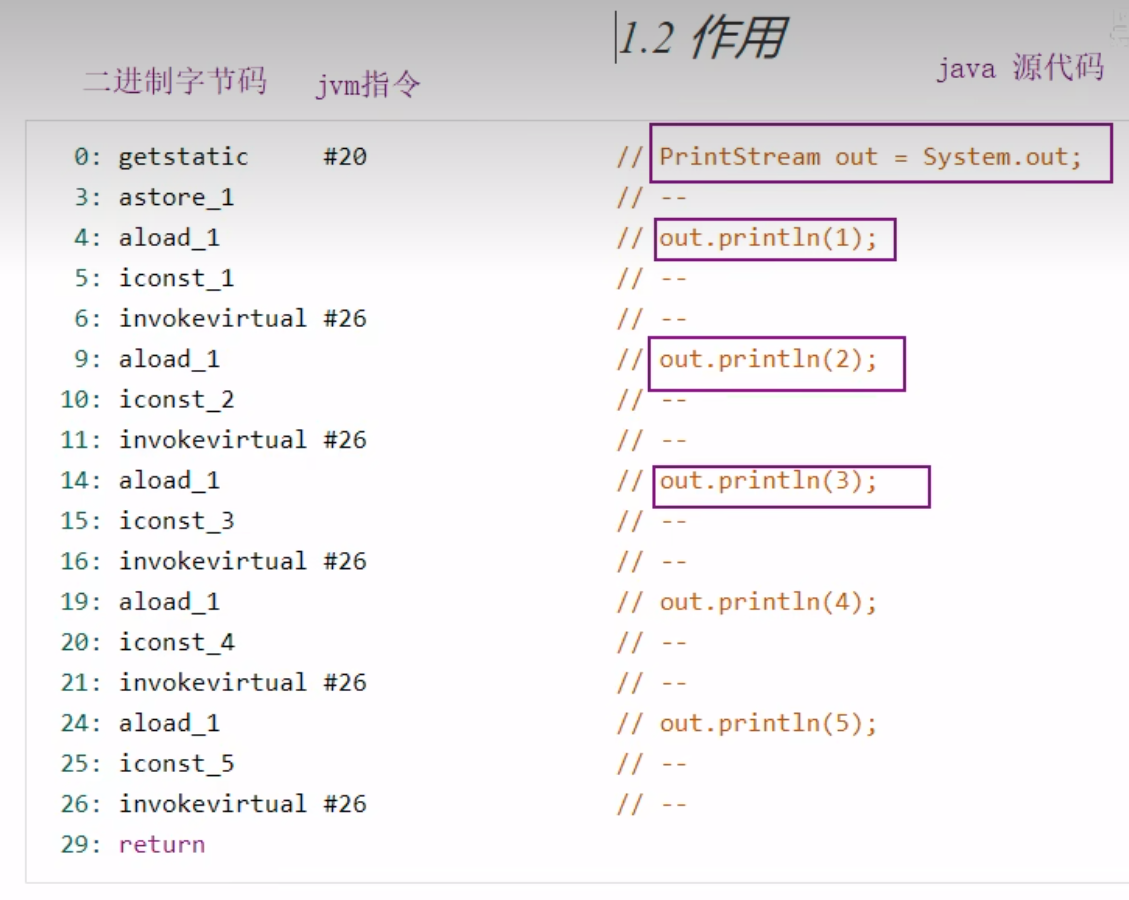
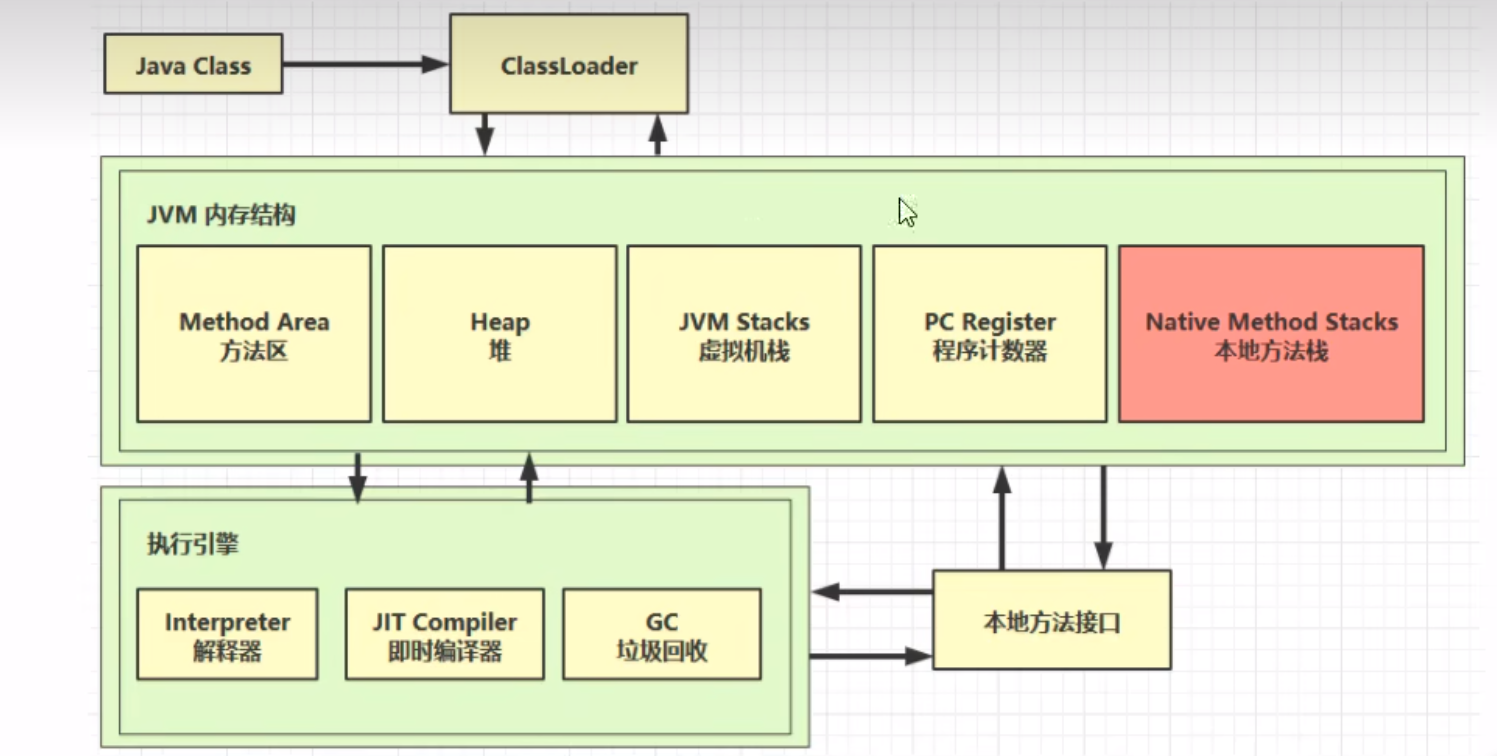
1 内存结构
1.1 程序计数器
1.1.1 作用
在执行的过程中 , 记住下一条jvm指令的执行地址
物理上通过寄存器实现
1.1.2 特性
-
每个线程都有自己的程序计数器 - 线程私有
-
不会存在内存溢出
1.2 虚拟机栈
1.2.1 定义
栈 - 线程运行需要的内存空间
栈帧 - 每个方法运行时所需要的内存
- 方法执行时,方法所用的栈帧入栈
- 方法执行完成时 , 栈帧出栈(内存被释放) jvm内存回收机制
每个线程运行时 只能有一个 活动栈帧
1.2.3 一些相关问题
栈内存不需要进行垃圾回收(后面所提及的堆内存需要)
默认栈大小 - 1024kb
widows根据虚拟内存所分配

如果方法内的局部变量没有逃离方法分作用访问, 它是线程安全的
如果局部变量引用了对象 , 并逃离了作用范围需要考虑线程安全问题
1.2.3 栈内存溢出
栈帧过多导致的栈内存溢出
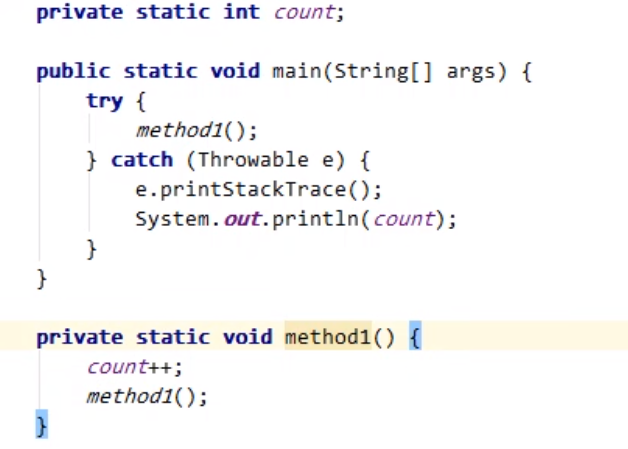
此处无限递归,造成栈帧过多 , 内存溢出 , 抛出异常StackOverFlowError
更改栈帧大小的操作
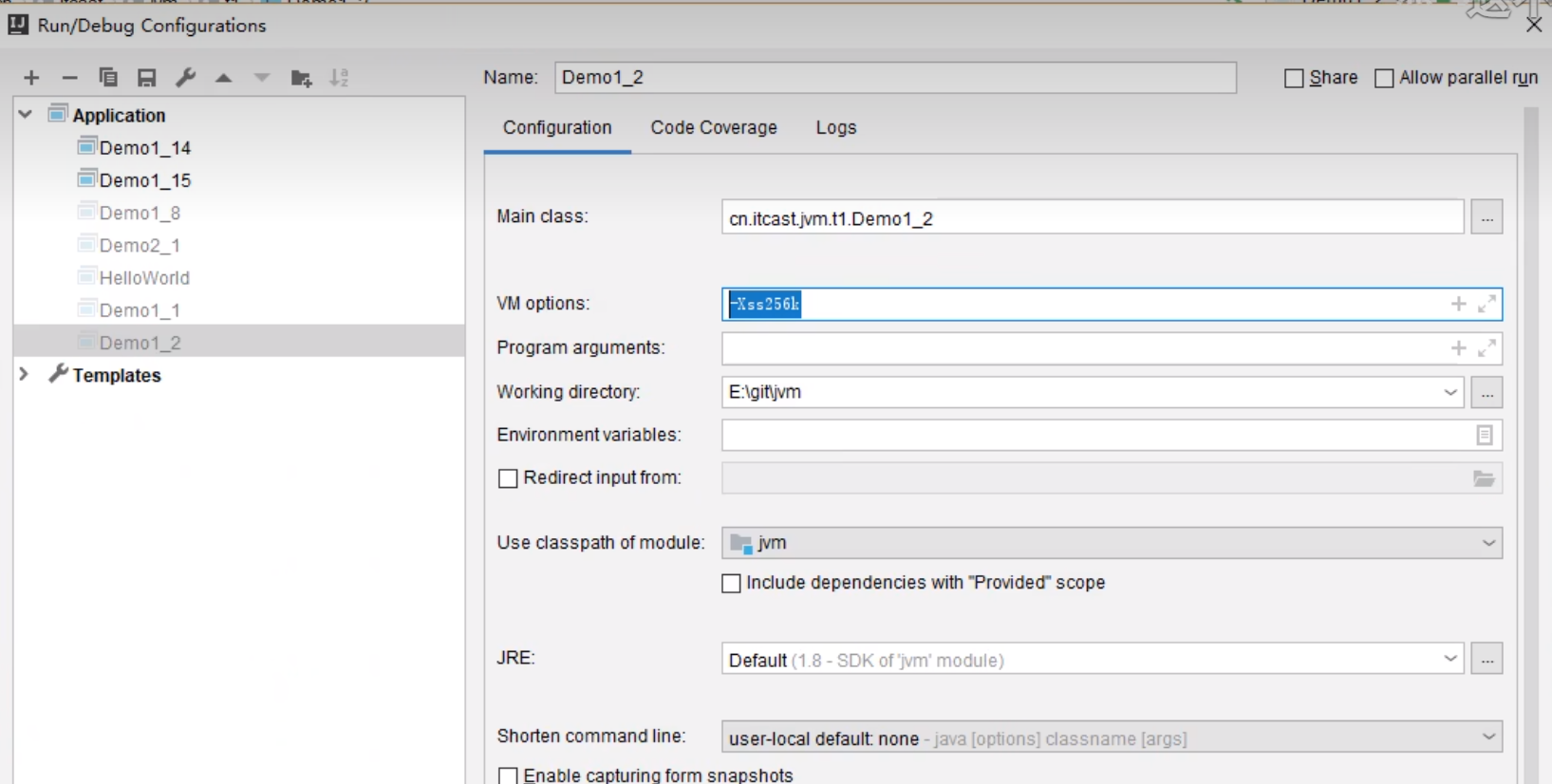
重新更改栈大小 VM options 添加 -Xss256k , 此时循环次数降低就造成了栈溢出
栈帧过大造成的栈内存溢出
如果两个类相互套娃, 都有对方的作为成员变量 , 那么在转换成json时会无限转换下去,直至栈溢出
1.2.4 线程运行诊断
cpu占用过多 - 定位
哪个进程占用资源更高
运行jar 用top命令进行检测
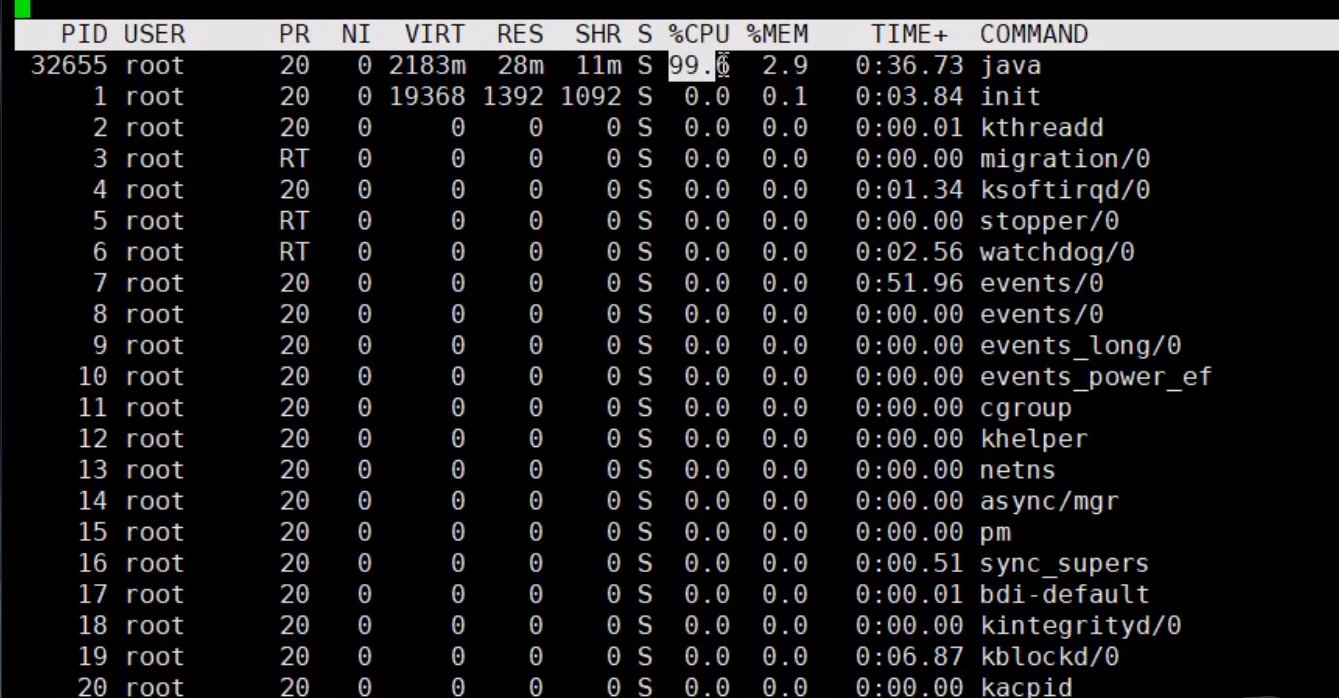
查询到了进程所使用的资源
哪个线程占用过高
用 ps H -eo pid,tid,%cpu 命令
查询线程所占用的资源
jstack 工具列出所有java线程
线程id需要转换成十六进制
进一步定位到问题源代码的行号
程序运行很长时间没有结果
有可能是发生了死锁
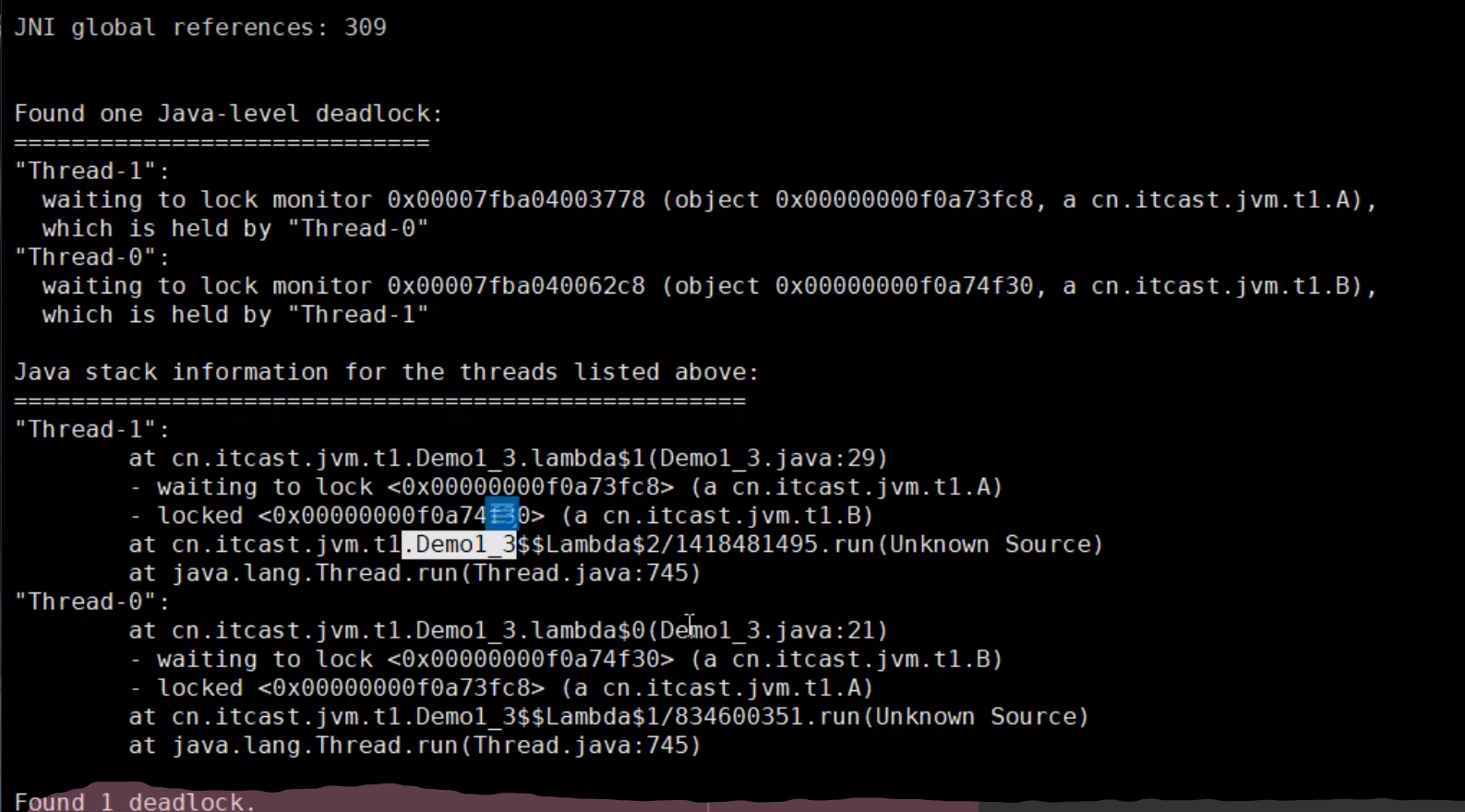
用jstack查看进程
1.3 本地方法栈
在与更底层的功能交互时,需要调用用c或者其他偏向底层的语言写的本地方法接口 , 关键词 native 此时会给调用的本地方法提供一定的内存空间
1.4 堆
1.4.1 定义
通过new关键字创建对象时都会使用堆内存
- 特点
他是线程共享的 , 堆中的对象都需要考虑线程安全的问题
有垃圾回收机制
1.4.2 堆内存溢出
更改堆大小 - 默认4GB
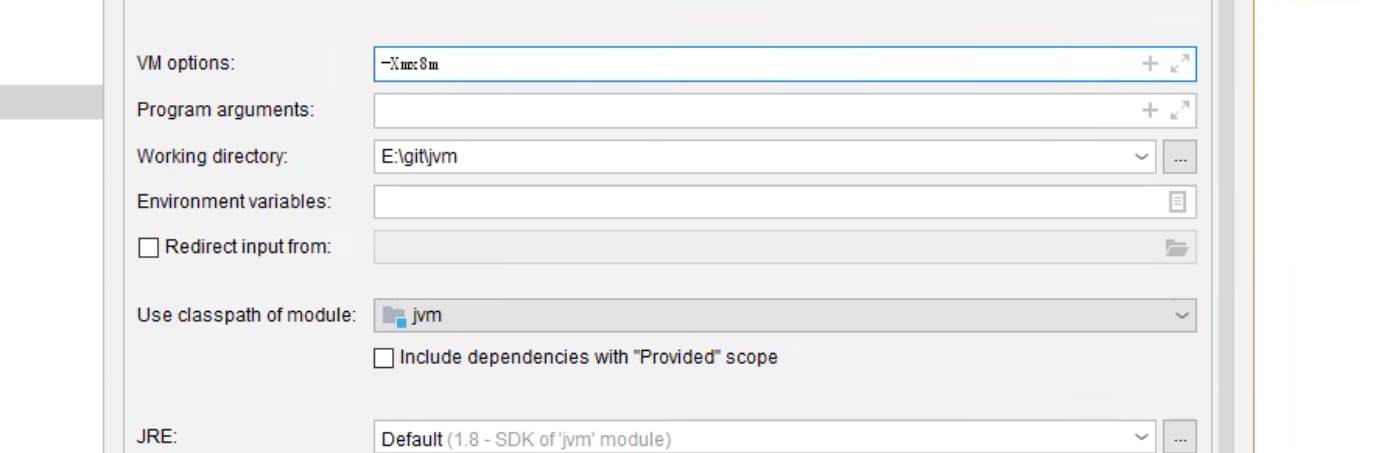
-Xmx8m
1.4.3 堆内存诊断
工具:

jvisualvm工具 - 可视化 , 能够保存当前堆的快照进行分析
1.5 JVM方法区
1.5.1 概念
jdk 1.6 - 用永久代(PermGen) 实现 用堆内存存储
存储着:常量池(包含StringTable) Class ClasLoader
1.8 Metaspace 元空间 实现 存储在本地内存中
存储着:常量池 Class ClasLoader
StringTable 仍然存储在堆中
1.5.2 方法区内存溢出
元空间的内存溢出
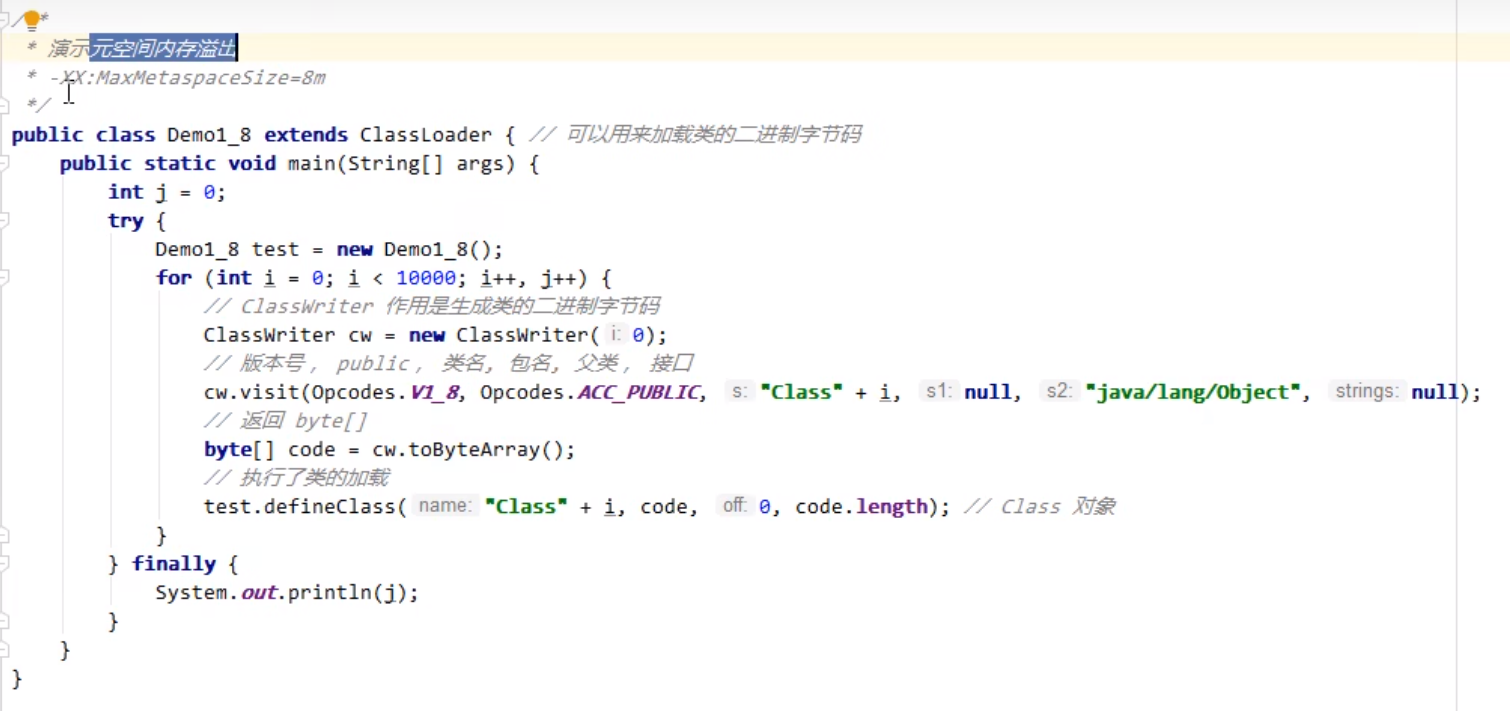
永久代的内存溢出
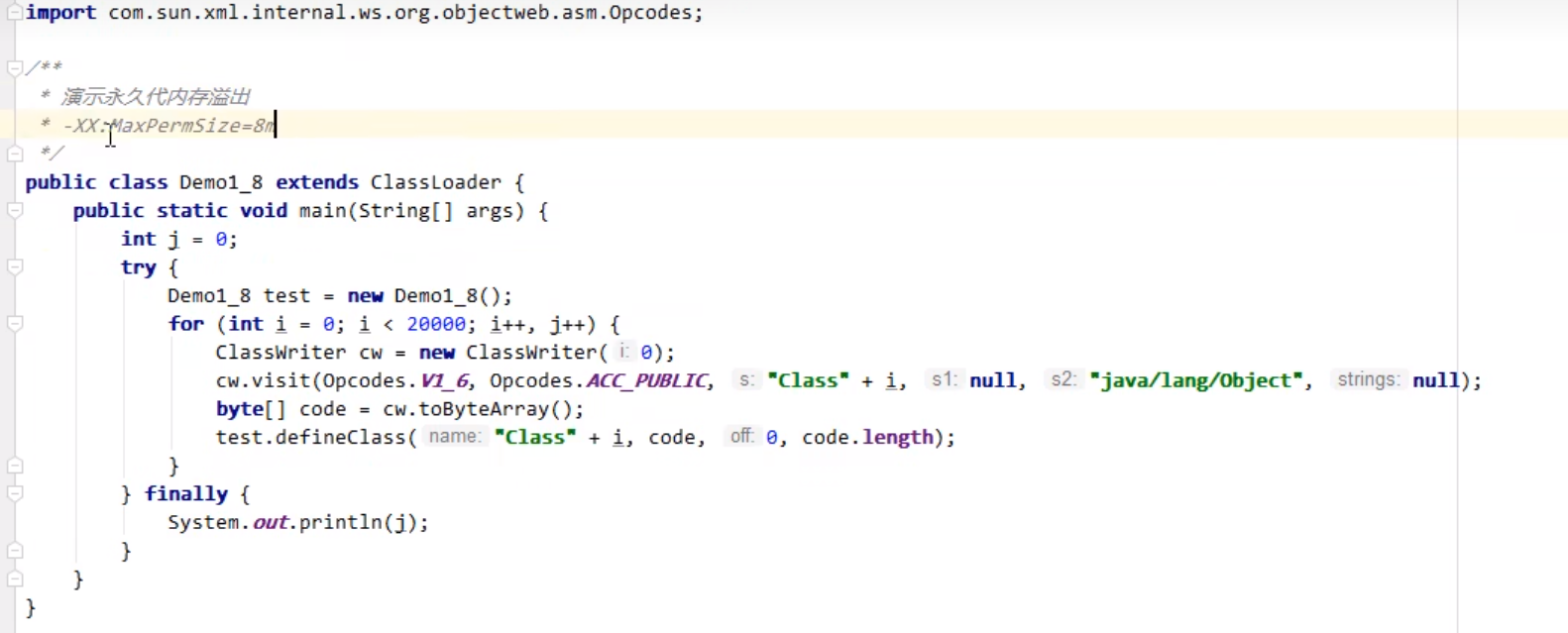
1.5.3 运行时常量池
java -v xx.class 反编译类 输出类编译后的信息
二进制字节码 : 类基本信息 , 常量池, 类方法定义, 包含了虚拟机指令
- 常量池:就是一张表 , 虚拟机根据这张常量表找到要执行的类名 方法名 参数类型
字面量等信息
- 运行时常量池 , 常量池是 *.class 文件中的,当该类被加载, 他的常量池信息就好被放入运行时常量池,并把里面的符号地址变为真实地址
1.5.3 StringTable
ldc #2 --- 会把a符号变成“a”字符串对象 放入常量池中(先会在常量池的哈希表结构中查找,如果没那就放进去,如果存在,那么就会将地址指向它)
string s4 = s1 + s2;
两个字符串拼接 - 会先创建个StringBuilder对象 然后调用append方法拼接 最后调用tostring tostring 是new出一个string 所以存放在堆中
string s5 = "a" + "b";
javac在编译期优化 , 两个常量拼接在编译期间就确定了,所以直接加入串池
s.intern()
将该字符串对象尝试放入串池中 如果有则不会放入 如果没有则放入串池
将串池的对象返回
jdk1.6会将对象拷贝一份再放入串池
1.8 直接将该对象放入串池
1.5.4 永久代、新生代、老年代(插入)
参考博客:https://blog.csdn.net/zs18753479279/article/details/119341774
概念:
Java7及以前版本的Hotspot中方法区位于永久代中。同时,永久代和堆是相互隔离的,但它们使用的物理内存是连续的。
堆被划分成两个不同的区域:新生代 ( Young )、老年代 ( Old )。而新生代 ( Young ) 又被划分为三个区域:Eden、From Survivor、To Survivor。这样划分的目的是为了使 JVM 能够更好的管理堆内存中的对象,包括内存的分配以及回收。
- 新生代中一般保存新出现的对象,所以每次垃圾收集时都发现大批对象死去,只有少量对象存活,便采用了复制算法,只需要付出少量存活对象的复制成本就可以完成收集。
- 老年代中一般保存存活了很久的对象,他们存活率高、没有额外空间对它进行分配担保,就必须采用“标记-清理”或者“标记-整理”算法。
- 永久代就是JVM的方法区。在这里都是放着一些被虚拟机加载的类信息,静态变量,常量等数据。这个区中的东西比老年代和新生代更不容易回收。
1.5.5 StringTable 垃圾回收
打印垃圾回收信息
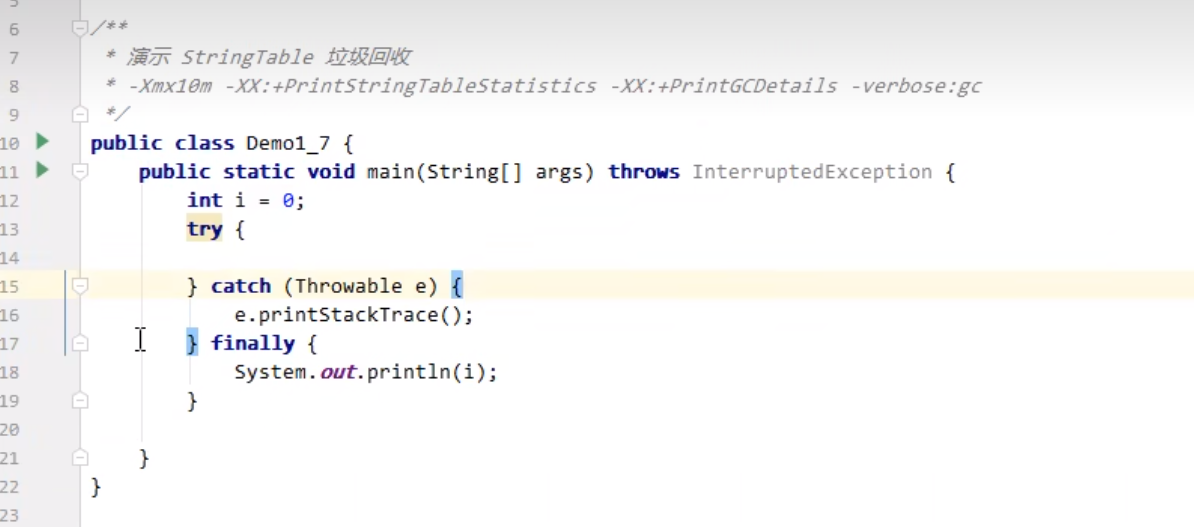
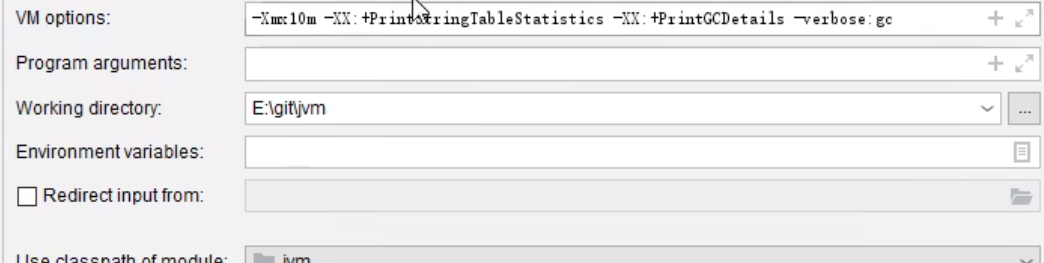
1.5.6 StringTable性能调优
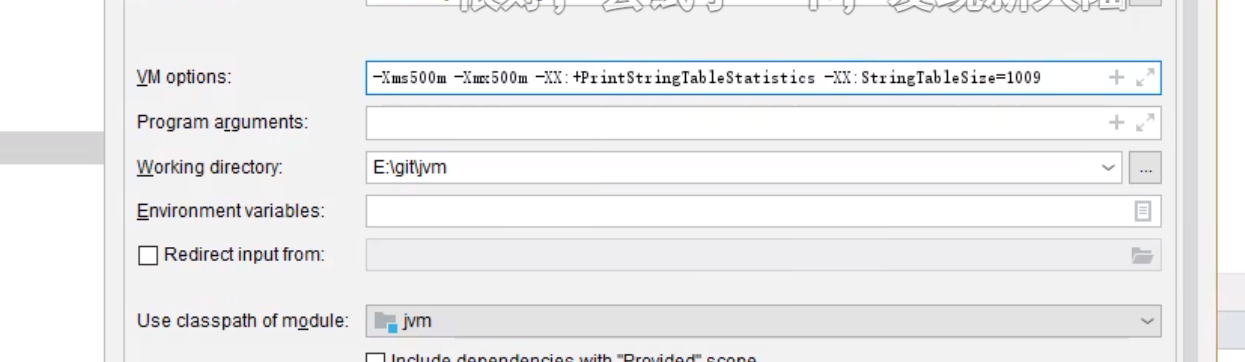
常量较多的情况下,增加哈希桶的数量 , 以此来减少哈希碰撞的概率,进而提高了效率(以空间换时间)
-XX:StringTableSize=桶个数
将常用的变量入池 , 比不入池的内存占用较小
s.intern()
1.6 直接内存
1.6.1 定义

ByteBuffer.allocateDirect(1024*1024);
提高大文件的读写性能
正常的文件读写
CPU从用户态转换到内核态 再转换到用户态
文件的读写从磁盘文件读入到系统内存中的系统缓存区 而后读入java的缓冲区 磁盘效率低
使用了direct memory 从系统内存中划出一个缓冲区 , java和系统都能够直接访问它
少了一次缓冲区的复制操作 效率大大提高
1.6.2 释放原理
直接内存的内存管理并不是由jvm的内存机制管理的 ,内置的垃圾回收对象对它无效,这里是使用Unsafe来释放内存的
unsafe.freeMemory(地址[long]) unsafe对象可以通过暴力反射来获取
因为bytebuff对象被回收 虚引用机制的关联 使得Unsafe触发回收了直接内存
ByteBuffger的实现类内部 , 使用了Cleaner(虚引用)来监测ByteBuffer对象 , 一单ByteBuffer对象被垃圾回收 , 那么就会由ReferenceHandler线程通过Cleaner 的 clean方法调用freeMemory来直接释放内存
-XX:+DisableExplicitGC 禁用显式的垃圾回收 , jvm调优时加上, 显示垃圾回收时不会Full GC
System.gc() // 显式的垃圾回收 Full GC
但是这样会引发问题 , 如果使用直接内存时, 显示回收没法回收掉byteBuffer的对象 , 造成直接内存没法及时释放,只有等到系统触发垃圾回收时才能一起释放掉
这就需要我们自己去暴力反射获取unsafe , 从而手动的释放直接内存
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号