5.18学习总结
最优化基础理论与方法第二章 无约束最优化方法的一般结构
2.1 最优性条件
所谓最优性条件,是指最优化问题的最优解所要满足的必要条件或充分条件,这些条件对于最优化算法的建立和最优化理论的推理都是至关重要的.
求解n元函数的无约束最优化问题 min f(x) 其中, x = (x1, , xn)T Rn, f : Rn → R.
若n=1,则f (x)为一元函数.
一元函数的最优性条件
必要条件
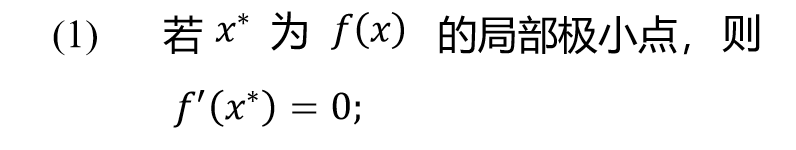
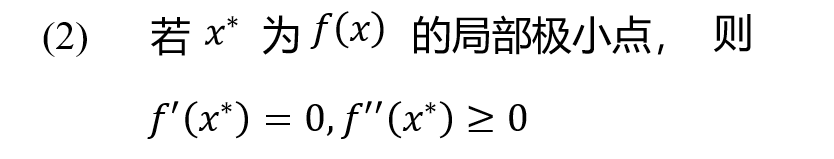
充要条件
![]()

局部解和全局解
定义2.1.1 设x^∗∈R^n .若存在x^∗的δ(δ > 0)邻域 N_δ (x^∗)= {x| ||x−x^∗||< δ}, 使得f(x)≥f(x^∗), ∀x∈N_δ(x^∗), 则称x^∗为f(x)的局部解;若f(x)> f(x^∗), ∀x∈N_δ(x^∗), ,则称x^∗为f(x)的严格局部解。
定义2.1.2 设x^∗∈R^n (1)若对任意的x^∗∈R^n,有f(x)≥f(x^∗),则称x^∗为f(x)的全局解; (2)若对任意的x^∗∈R^n ,有f(x) > f(x^∗),则称x^∗为f (x)的严格全局解。
一阶必要条件
定理 2.1.1 若f(x)一阶连续可微,若x^∗是无约束问题的局部解 ∇f(x^∗)=0;
注:(1)仅仅是必要条件,而非充分条件
若x^∗是局部解,则任何方向上的方向导数均为0, 即在x^∗处的切平面是水平的. 注意, 定理2.1.1的逆命题不成立,即梯度为0的点不一定是局部解.

所谓x^∗是鞍点, 从直观上说曲面在x^∗处沿一方向“向上弯曲”,而沿另一方向“向下弯曲”
二阶必要条件
定理 2.1.2 若f(x)二阶连续可微,若x^∗是无约束问题的局部解 ∇f(x^∗)=0; ∇^2f(x^∗)为半正定
注: (1) 刻画了f (x)在x处切平面的法向.
(2) 刻画了曲面f (x) 的弯曲方向.
(3) 局部解 x^∗ 处的二阶方向导数为负.
(4) 定理2.1.2仅仅是必要条件而非充分条件.
定理 2.1.3 若f(x)二阶连续可微,且 ∇f(x^∗)=0;∇^2f(x^∗)为正定 则x^∗是无约束问题的一个严格局部解
(1)如果∇^2f(x^∗)负定,则x^∗为严格局部极大点
(2) 定理2.1.3仅仅是充分条件而非必要条件.
凸优化问题-----一阶充要条件
定理 2.1.4 若f: R^n→R是凸函数,且f(x)一阶连续可微,则x^∗是全局解的充分必要条件是 ∇f(x^∗)=0.
证明 因为f是R^n上的可微凸函数∇f(x^∗)=0,故有 f(x)≥f(x^∗)+∇f(x^∗)T(x−x^∗)=f(x^∗),∀x^∈R^n, 这表明x*是f(x)的全局极小点. 必要性显然
2.2 线性搜索
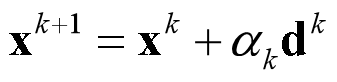
d的k次方:K+1次迭代的搜索方向
ak:
搜索的最佳步长因子
当搜索方向 给定,求最佳步长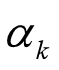 就是求一元函数的极值
就是求一元函数的极值
f(x^k+1)=f(x^k+α_kd^k)=ϕ(α_k)
称为一维搜索,是优化搜索方法的基础。
求解一元函数的步长 α_k,主要有精确线性搜索、直接搜索法和不精确搜索法等
2.2.1 精确线性搜索
如果有α_k,使得 min┬α>0{ϕ(α)=f(x^k+αd^k)} 则称该搜索为精确线性搜索,称得到的α^k为最优步长。
求解:ϕ^′(α)=∇f(x^k+α^d^k)^Td^k=0
其中,解得α_k是方程的非负根。求ϕ(α)中的全局极小点是困难的, 故取方程的最小正根作为中ϕ(α)的极小点αk,
Curry准则:![]()
2.2.2 搜索区间与单峰函数
定义2.2.1 设 α^∗是ϕ(α)的极小点,若存在区间[a,b] 使得 α^∗∈[a,b],则称[a,b]为ϕ(α)的搜索区间
定 义:如果函数ϕ(α)在区间[a, b]上只有一个极值点, 则称ϕ(α)为[a, b]上的单峰函数。
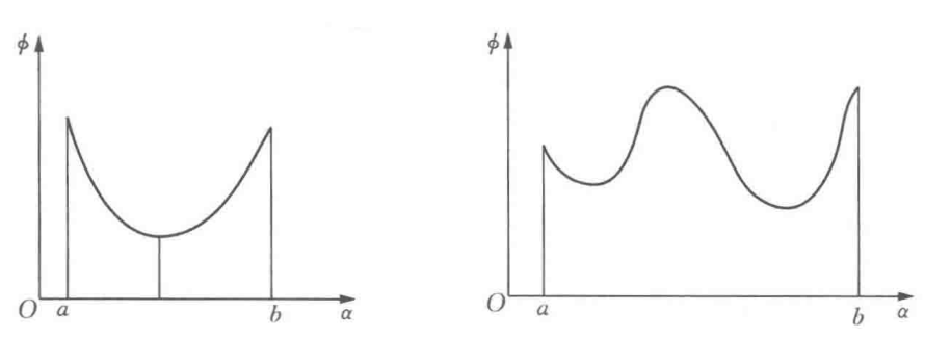
单峰函数的消去性质
定 理:设f(x)是区间[a,b]上的一个单峰函数,x*∈[a,b]是其极小点, x1 和x2是[a, b]上的任意两点,且a<x1 <x2<b,那么比较f(x1)与f(x2)的值后,可得出如下结论:
(I) 若f(x1)≥f(x2),x*∈[x1,b]
(II) 若f(x1) < f(x2), x*∈[a,x2]
在单峰函数的区间内,计算两个点的函数值,比较大小后,就能把搜索区间缩小。在已缩小的区间内,仍含有一个函数极值,若再计算另一点的函数值,比较后就可进一步缩小搜索区间 .
如何确定包含极小点在内的初始区间 ?
(一)基本思想:由单峰函数的性质可知,函数值在极小点左边严格下降,右边严格上升。
从某个初始点出发,沿函数值下降的方向前进,直至发现函数值上升为止。由两边高,中间低的三点,可确定极小点所在的初始区间。
(二)初始区间确定算法
1、选定初始点a 和步长h;
2、计算并比较f(a)和f(a+h);有前进(1)和后退(2)两种情况:
(1) 前进运算:若f(a) ≥f(a+h), 则步长加倍,计算f(a+2h)。若f(a+h) ≤f(a+2h), 令 a1=a, a2=a+2h, 停止运算;否则将步长加倍,并重复上述运算。
(2) 后退运算:若f(a) < f(a+h), 则将步长改为-h。计算f(a-h), 若f(a-h) ≥ f(a), 令 a1=a-h, a2=a+h, 停止运算;否则将步长加倍,继续后退。
(三) 几点说明 缺点:效率低; 优点:可以求搜索区间; 注意:h 选择要适当,初始步长不能选得太小;
2.2.3 直接搜索法——0.618法(黄金分割法)
0.618法的基本思想是通过取试探点和进行函数值比较,使包含极小点的搜索区间不断减少,当区间长度缩短到一定长度时,就得到函数极小点的近似值。
在搜索区间上确定两个试探点,其中
左试探点为:

右试探点为:

下面开始推导黄金分割法的分割方式。
设 f (x)在[a,b]上单峰, 极小值点x ̅∊[a, b] 第k次迭代前x ̅∊[ak , bk], 计算新的左、右分割点al , ar (al < ar) 计算f (al ) 和f (ar ),更新边界分两种情况:
(1) f (al )> f (ar ) , 则 ak+1 =al,bk+1=bk ; (2) f (al )≤ f (ar ), 则 ak+1 =ak,bk+1=ar ;
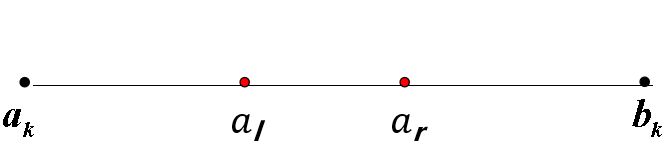
算法步骤:
(1)置初始区间[a,b], 并置精度要求ε,并计算左右试探点
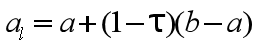
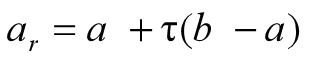
其中 ,及相应的函数值
Φl=f (al), Φr=f (ar)
(2)如果Φl<Φr,则置b=ar 、 ar=al, Φr=Φl
并计算
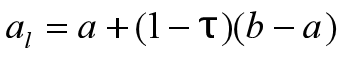 新的左分割点
新的左分割点
Φl=Φ(al)新的左分割点函数值
否则,置a=al, al=ar, Φl=Φr,
并计算
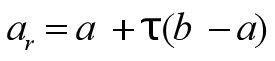 新的右分割点
新的右分割点
Φr=Φ(ar)新的右分割点函数值
(3)如果|b-a|≤ ε,那么:如果Φl<Φr,则置μ=al; 否则,置μ=ar, 停止计算(μ作为问题的解)。否则,转步骤(2)。
2.2.4 非精确一维搜索方法
用前面介绍的精确线性搜索和0.618法求得的是一元函数 Φ(α)=f(x^k+αd^k)精确极小点或近似极小点。
其缺点:计算量大、 迭代初始阶段,迭代点离最优解较远,过分追求精确迭代,大大 降低效率。 因此,适当放松对α^k的要求,只要求目标函数在每次迭代有充分下降即可,可以减少搜索时间,提高效率 ,此类方法成为非精确一维搜索方法。
非精确一维搜索方法:总体希望收敛快,每一步不要求达到精确最小,速度快,虽然步数增加,则整个收敛达到快速。
基本思想是求μ,使得Φ(μ)<Φ(0),但不希望μ值过大,因为μ值过大会引起点列{x^k}产生大幅度的摆动。也不希望μ值过小,因为μ值过小会使得点列{x^k}在未达到x^∗之前进展缓慢,下面简单介绍三种非精确一维搜索方法思想。
2.2.4 非精确一维搜索方法-Goldstein方法
(预先指定两个参数β_1,β_2(精度要求),满足0<β_1<β_2<1,)
用下边两个不等式来限定步长μ,即:
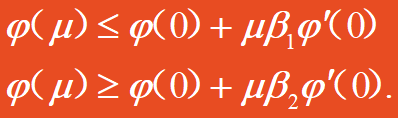
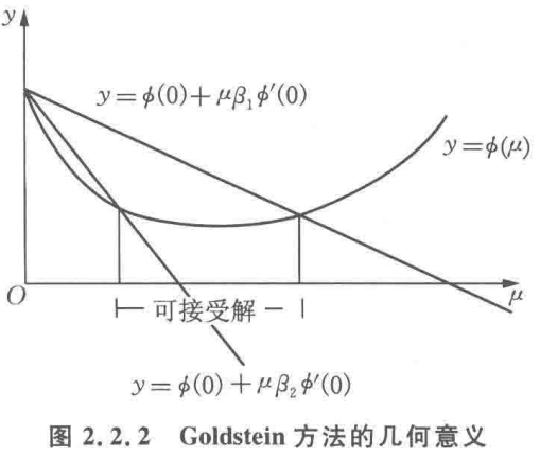
由图可以看出, μ值在y=φ(μ)图形夹于直线y=φ(0)+β_1φ^′(0)μ 和直线y=φ(0)+β_2φ^′(0)μ 之间。
直线 y=φ(0)+μβ_1φ^′(0) 控制μ的值使其不会过大;
直线 y=φ(0)+μβ_2φ^′(0) 控制𝜇值使其不会过小。
Goldstein算法步骤

2.2.4 非精确一维搜索方法-Armijo方法
Armijo方法是Goldstein方法的一种变形,是Armijo在1969年提出来的求αk的一种试探性方法。

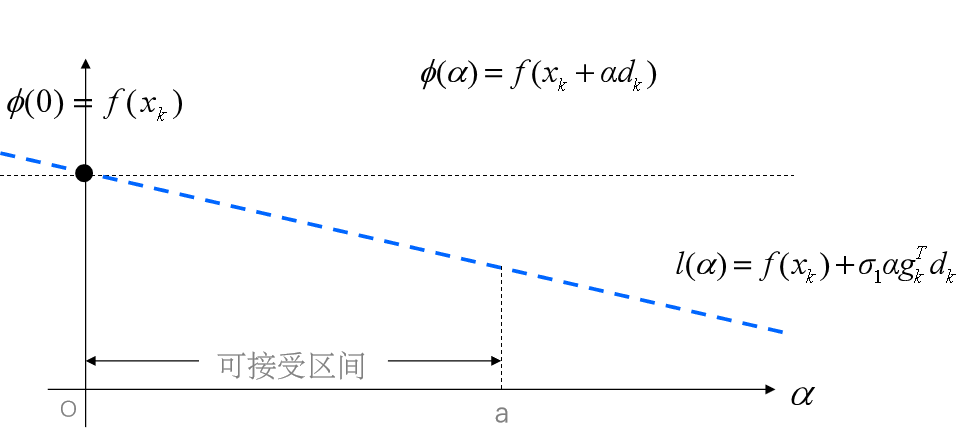
用进退法实现Armijo搜索:逐渐变小以满足Armijo搜索条件
2.2.4 非精确一维搜索方法-Wolfe-Powell方法
Wolfe- Powell方法是1969 年到1976年期间,由Wolfe 和Powell 提出来的。
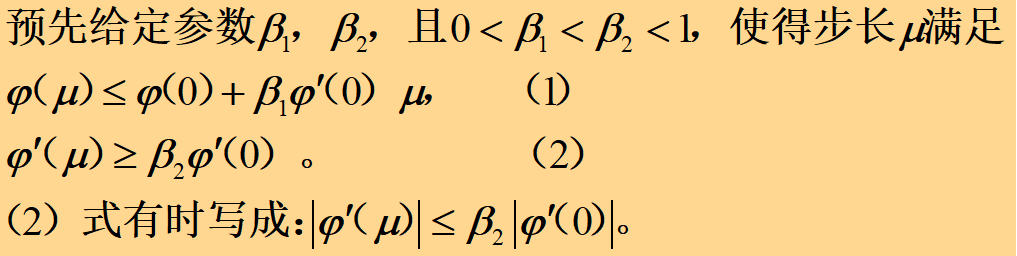
Wolfe- Powell方法的优点是: 在可接受解中保证了最优解a* ,而Goldstein方法却不能保证这一点。

算法比较: 从算法步骤中可以看出,Wolfe 和Goldstein 算法是类似的,不同之处在于: 在准则不成立时,而需要计算新的μ时,后者利用了简单的求区间中点的方法,前者利用二次插值方法. 除了这两种确定新的μ的方法,读者也可以采用其他的方法来确定新的。 (新的算法由此产生!)
2.3 下降算法的全局收敛性与收敛速度
下降算法的一般迭代式
Step 1 给定初始点x1, k = 1; Step 2 确定局部下降方向d k,使得 ∇d^k<0; Step 3 确定步长αk>0,使得f(x^k)^T f(x^k+α_kd^k)<f(x^k) Step 4 令x^k+1=x^k+α_kd^k; Step 5 若xk+1满足终止准则,则停;否则,令k:=k十1,转Step 1.
终止准则,一般是与算法相联系的.一种较为常用的终止准则为∇f(x^k+1)=0
若{f(x)}有下界,则必有极限。但xk不一定收敛(甚至不一定有界)。即使{xk}收敛,其极限也不一定是f的平稳点.
下降算法的全局收敛性
设∇f (x)在水平集L(x0)={x | f(x) ≤ f (x0)}上存在且一致连续,下降算法的搜索方向d k与−∇f(xk)之间的夹角𝜽k。满足(2.3.1)式, 步长αk由以下3种方法: (1) 精确线性搜索; (2) Glodstein方法; (3)Wolfe-Powell方法 之一确定, 则 或者对某个k ,有∇f(xk) =0, 或者有f(xk)→ − ∞( k→∞),或者有 ∇f(xk )→0(k →∞ ).
下降算法的收敛速率
设序列{xk}收敛到x*,若极限lim┬k→∞‖x^k+1−x^∗‖/‖xk_−x∗‖=β存在,则当0<β<1时,称{xk}为线性收敛; 当β=0时,称{xk}为超线性收敛; 当β=1时,称{xk}为次线性收敛, 因为次线性收敛的收敛速度太慢,一般不予以考虑.
若存在在某个p≥1,有lim┬k→∞‖x^k+1−x^∗‖/‖xk_−x∗‖p=β<+∞, 则称{xk}为p阶收敛。当p>1时,p阶收敛必为超线性收敛,但反之不一定成立。 在最优化算法中, 通常考虑线性收敛﹑超线性收敛和二阶收敛. 说一个算法是线性(超线性或二阶)收敛的, 是指算法产生的序列(在最坏情况下)是线性(超线性或二阶)收敛的。
二次终止性
定义 2.3.1 设G是n ×n正定对称矩阵,称函数 f(x)=1/2x^TGx+r^Tx+δ 为正定二次函数
定义 2.3.2 若某个算法对于任意的正定二次函数,从任意的初始点出发,都能经有限步迭代达到其极小点, 则称该算法具有二次终止性.
为什么用算法的二次终止性来作为判定算法优劣的标准呢?
其原因有二: (1) 正定二次目标函数具有某些好的性质, 因此一个好的算法应能够在有限步内达到其极小点; (2) 对于一个一般的目标函数, 若在其极小点处的Hesse矩阵∇2f(x*)正定, 则由Taylor展开式得到 f(x)=f(x*)+∇f(x*)T (x-x*)+1/2(x-x*)T∇2 f(x*)(x-x*)+O(‖x−x∗‖2) 在极小值点附近与正定二次函数相似,对于正定二次函数好的算法,对目标函数也有好的性质。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号