20175215 2018-2019-2 第八周java课程学习总结
博主QQ:854066859
正文
第十五章 泛型与几何框架
15.1 泛型
泛型(Generics)是在JDK1.5中推出的,其主要目的是可以建立具有类型安全的集合框架,如链表、散列映射等数据结构。
15.1.1 泛型类声明
可以使用“class 名称<泛型列表>”声明一个类,为了和普通的类有所区别,这样声明的类称作泛型类,
如:class People<E>
其中People是泛型类的名称,E是其中的泛型,也就是说我们并没有指定E是何种类型的数据,它可以是任何对象或接口,但不能是基本类型数据。
15.1.2 使用泛型类声明对象
泛型类声明和创建对象时,类名后多了一对“<>”,而且必须要用具体的类型替换“<>”中的泛型。例如:
Cone<Circle> coneOne;
coneOne =new Cone<Circle>(new Circle());
15.2 链表
链表是由若干个称作节点的对象组成的一种数据结构,每个节点含有一个数据和下一个节点的引用 。
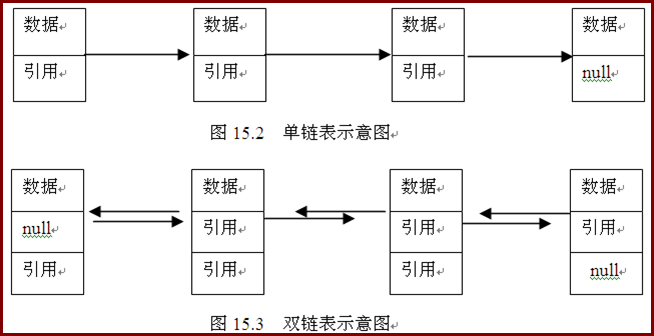
15.2.1 LinkedList<E>泛型类
LinkedList<E>泛型类创建的对象以链表结构存储数据,习惯上称LinkedList类创建的对象为链表对象。
例如,LinkedList<String> mylist=new LinkedList<String>();
创建一个空双链表。
add(E obj) 向链表依次增加节点
15.2.2 LinkedList泛型类常用方法
LinkedList<E>泛型类实现Lis<E>泛型接口中的一些常用方法。public boolean add(E element)向链表末尾添加一个新的节点,该节点中的数据是参数elememt指定的数据。public void add(int index ,E element)向链表的指定位置添加一个新的节点,该节点中的数据是参数elememt指定的数据。public void clear()删除链表的所有节点,使当前链表成为空链表。public E remove(int index)删除指定位置上的节点。public boolean remove(E element)删除首次出现含有数据elemen的节点。public E get(int index)得到链表中指定位置处节点中的数据。
LinkedList<E>泛型类本身新增加的一些常用方法public void addFirst(E element)向链表的头添加新节点,该节点中的数据是参数elememt指定的数据。public void addLast(E element)向链表的末尾添加新节点,该节点中的数据是参数elememt指定的数据。public E getFirst()得到链表中第一个节点中的数据。public E getLast()得到链表中最后一个节点中的数据。public E removeFirst()删除第一个节点,并返回这个节点中的数据。
15.2.3 遍历链表
当用户需要遍历集合中的对象时,应当使用该集合提供的迭代器,而不是让集合本身来遍历其中的对象。由于迭代器遍历集合的方法在找到集合中的一个对象的同时,也得到待遍历的后继对象的引用,因此迭代器可以快速地遍历集合。
链表对象可以使用iterator()方法获取一个Iterator对象,该对象就是针对当前链表的迭代器。
15.2.4 排序与查找
Collections类提供的用于排序和查找的类方法如下:
public static sort(List<E> list)该方法可以将list中的元素升序排列。int binarySearch(List<T> list, T key,CompareTo<T> c)使用折半法查找list是否含有和参数key相等的元素,如果key链表中某个元素相等,方法返回和key相等的元素在链表中的索引位置(链表的索引位置从0开始),否则返回-1。
15.2.5 洗牌与旋转
Collections类还提供了将链表中的数据重新随机排列的类方法以及旋转链表中数据的类方法。
public static void shuffle(List<E> list)将list中的数据按洗牌算法重新随机排列。static void rotate(List<E> list, int distance)旋转链表中的数据。public static void reverse(List<E> list)翻转list中的数据。
15.3 堆栈
堆栈是一种“后进先出”的数据结构,只能在一端进行输入或输出数据的操作。
Stack<E>泛型类创建一个堆栈对象,堆栈对象常用方法:public E push(E item);实现压栈操作public E pop();实现弹栈操作。public boolean empty();判断堆栈是否还有数据。public E peek();获取堆栈顶端的数据,但不删除该数据。public int search(Object data);获取数据在堆栈中的位置。
15.4 散列映射
15.4.1 HashMap<K,V>泛型类
HashMap<K,V>对象采用散列表这种数据结构存储数据,习惯上称HashMap<K,V>对象为散列映射。
例如:HashMap<String,Student> hashtable= HashSet<String,Student>(); hashtable可以存储“键/值”对数据。
相关方法:
public V put(K key,V value)将键/值对数据存放到散列映射中,该方法同时返回键所对应的值。
15.4.2 常用方法
public void clear()清空散列映射。public Object clone()返回当前散列映射的一个克隆。public boolean containsKey(Object key)如果散列映射有“键/值”对使用了参数指定的键,方法返回true,否则返回false。public boolean containsValue(Object value)如果散列映射有“键/值”对的值是参数指定的值。public V get(Object key)返回散列映射中使用key做键的“键/值”对中的值。public boolean isEmpty()如果散列映射不含任何“键/值”对,方法返回true,否则返回false。public V remove(Object key)删除散列映射中键为参数指定的“键/值”对,并返回键对应的值。public int size()返回散列映射的大小,即散列映射中“键/值”对的数目。
15.4.3 遍历散列映射
public Collection<V> values()方法返回一个实现Collection<V>接口类创建的对象。
使用接口回调技术,即将该对象的引用赋给Collection<V>接口变量,该接口变量可以回调iterator()方法获取一个Iterator对象,这个Iterator对象存放着散列映射中所有“键/值”对中的“值”。
15.4.4 基于散列映射的查询
对于经常需要进行查找的数据可以采用散列映射来存储这样的数据,即为数据指定一个查找它的关键字,然后按着“健-值”对,将关键字和数据一并存入散列映射中。
15.5 树集
15.5.1 TreeSet<E>泛型类
TreeSet
例如:TreeSet<String> mytree=new TreeSe<String>();
然后使用add方法为树集添加节点,例如:mytree.add("boy");
15.5.2 结点的大小关系
树集用add方法添加节点,节点会按其存放的数据的“大小”顺序一层一层地依次排列,在同一层中的节点从左到右按“大小”顺序递增排列,下一层的都比上一层的小。
15.5.3 TreeSet类的常用方法
public boolean add(E o)向树集添加加节点。public void clear()删除树集中的所有节点。public void contains(Object o)如果树集中有包含参数指定的对象,该方法返回true,否则返回false 。public E first()返回树集中的第一个节点中的数据(最小的节点)。public E last()返回最后一个节点中的数据(最大的节点)。public isEmpty()判断是否是空树集,如果树集不含任何节点,该方法返回true 。public boolean remove(Object o)删除树集中的存储参数指定的对象的最小节点。public int size()返回树集中节点的数目。
15.6 树映射
TreeMap<K,V>类实现了Map<K,V>接口,称TreeMap<K,V>对象为树映射。
树映射使用public V put(K key,V value);方法添加节点。
15.7 自动装箱与拆箱
JDK1.5新增的基本类型数据和相应的对象之间相互自动转换的功能,称作基本数据类型的自动装箱与拆箱(Autoboxing and Auto-Unboxing of Primitive Types)。
SP.第八周学习中碰到的问题
1.在散列映射的查询中无法正常进行查询
在IDEA中,我直接运行书本P453中的Example15_7例子,出现无法找到的问题:
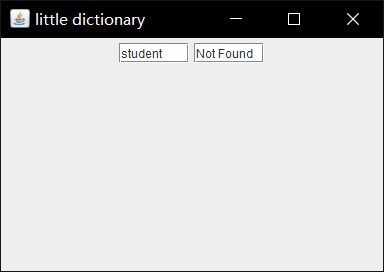
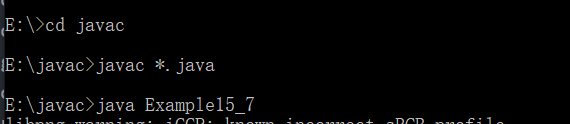
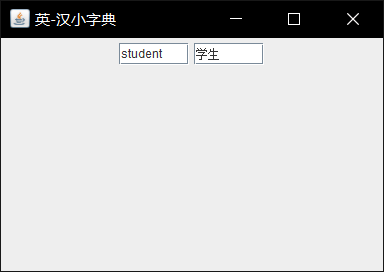
解决方案:在cmd中直接编译运行。

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步