
TensorFlow 3
以下代码用于忽略级别 2 及以下的消息(级别 1 是提示,级别 2 是警告,级别 3 是错误)。
import os os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
run(fetches,feed_dict=None,options=None,run_metadata)
语法
1、常量字符串 :tf.constant // t_1 = tf.constant(4) t_2 = tf.constant([4,3,2]) //
2、所有元素为零的张量 : f.zeros()
// 这个语句可以创建一个形如 [M,N] 的零元素矩阵,数据类型(dtype)可以是 int32、float32 等:
tf.zeros([M,N],tf.dtype)
//
3、一个所有元素都设为 1 的张量:tf.ones([M,N],tf.dtype)
4、在一定范围内生成一个从初值到终值等差排布的序列:tf.linspace(start,stop,num) 相应的值为 (stop-start)/(num-1)
5、从开始(默认值=0)生成一个数字序列,增量为 delta(默认值=1),直到终值(但不包括终值):tf.range(start,limit,delta)
6、创建一个具有一定均值(默认值=0.0)和标准差(默认值=1.0)、形状为 [M,N] 的正态分布随机数组:t_random = tf.random_normal([2,3],mean=2.0,stddev=4,seed=12)
7、创建一个具有一定均值(默认值=0.0)和标准差(默认值=1.0)、形状为 [M,N] 的截尾正态分布 随机数组:t_random = tf.truncated_normal([2,3],mean=2.0,stddev=4,seed=12)
8、要在种子的 [minval(default=0),maxval] 范围内创建形状为 [M,N] 的给定伽马分布随机数组,请执行如下语句:t_random = tf.random_uniform([2,3],maxval=4.0,seed=12)
9、要将给定的张量随机裁剪为指定的大小,使用以下语句:tf.random_crop(t_random,[2,5],seed=12)
10、重新排序的张量:tf.random_shuffle(t_random)
11、随机生成的张量受初始种子值的影响。要在多次运行或会话中获得相同的随机数,应该将种子设置为一个常数值。TIP:种子只能有整数值。
当使用大量的随机张量时,可以使用 tf.set_random_seed() 来为所有随机产生的张量设置种子。以下命令将所有会话的随机张量的种子设置为 54:tf.set_random_seed(54)
12、定义变量:tf.Variable()
注意:变量通常在神经网络中表示权重和偏置。
13、每个变量也可以在运行图中单独使用 tf.Variable.initializer 来初始化:
bias = tf.Variable(tf.zeros([100,100])) with tf.Session() as sess: print(sess.run(bias.initializer))
None
14、保存变量:使用 Saver 类来保存变量,定义一个 Saver 操作对象:saver = tf.train.Saver()
15、占位符:tf.placeholder(dtype,shape=None,name=None)
dtype 定占位符的数据类型,并且必须在声明占位符时指定。
16、请注意,与 Python/Numpy 序列不同,TensorFlow 序列不可迭代。试试下面的代码:

17、tf.div 返回的张量的类型与第一个参数类型一致
18、所有加法、减、除、乘(按元素相乘)、取余等矩阵的算术运算都要求两个张量矩阵是相同的数据类型,否则就会产生错误。
可以使用 tf.cast() 将张量从一种数据类型转换为另一种数据类型。
19、在整数张量之间进行除法,最好使用 tf.truediv(a,b),因为它首先将整数张量转换为浮点类,然后再执行按位相除。
程序结构
图定义和执行分开
计算图:是包含节点和边的网络。本节定义所有要使用的数据,也就是张量(tensor)对象(常量、变量和占位符),同时定义要执行的所有计算,即运算操作对象(Operation Object,简称 OP)。
每个节点可以有零个或多个输入,但只有一个输出。网络中的节点表示对象(张量和运算操作),边表示运算操作之间流动的张量。计算图定义神经网络的蓝图,但其中的张量还没有相关的数值。
为了构建计算图,需要定义所有要执行的常量、变量和运算操作。
计算图的执行:使用会话对象来实现计算图的执行。会话对象封装了评估张量和操作对象的环境。这里真正实现了运算操作并将信息从网络的一层传递到另外一层。不同张量对象的值仅在会话对象中被初始化、访问和保存。在此之前张量对象只被抽象定义,在会话中才被赋予实际的意义。
例子:以两个向量相加为例给出计算图
1、假设有两个向量 v_1 和 v_2 将作为输入提供给 Add 操作。建立的计算图如下:
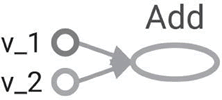
v_1 = tf.constant([1,2,3,4) v_2 = tf.constant([2,1,5,3) v_and = tf.add(v_1,v_2) # you can also write v_1 + v_2 instead
3、然后在会话中执行这个图:
with tf.Session() as sess: print(sess.run(v_add))
4、以上两行相当于下面的代码。上面的代码的优点是不必显式写出关闭会话的命令:
sess = tf.Session() print(sess.run(v_rdd)) sess.close()
5、运行结果:
{3 3 8 7}
请记住,每个会话都需要使用 close() 来明确关闭,而 with 格式可以在运行结束时隐式关闭会话。
如果你正在使用 Jupyter Notebook 或者 Python shell 进行编程,使用 tf.InteractiveSession 将比 tf.Session 更方便。InteractiveSession 使自己成为默认会话,因此你可以使用 eval() 直接调用运行张量对象而不用显式调用会话。下面给出一个例子:
sess = tf.InteractiveSession() v_1 = tf.constant([1,2,3]) v_2 = tf.constant([1,2,3]) v_add = tf.add(v_1,v_2) print(v_add.eval()) sess.close()
[2 4 6]
最基本的 TensorFlow 提供了一个库来定义和执行对张量的各种数学运算。张量,可理解为一个 n 维矩阵,所有类型的数据,包括标量、矢量和矩阵等都是特殊类型的张量。

TensorFlow 支持以下三种类型的张量:
- 常量:常量是其值不能改变的张量。
- 变量:当一个量在会话中的值需要更新时,使用变量来表示。例如,在神经网络中,权重需要在训练期间更新,可以通过将权重声明为变量来实现。变量在使用前需要被显示初始化。另外需要注意的是,常量存储在计算图的定义中,每次加载图时都会加载相关变量。换句话说,它们是占用内存的。另一方面,变量又是分开存储的。它们可以存储在参数服务器上。
- 占位符:用于将值输入 TensorFlow 图中。它们可以和 feed_dict 一起使用来输入数据。在训练神经网络时,它们通常用于提供新的训练样本。在会话中运行计算图时,可以为占位符赋值。这样在构建一个计算图时不需要真正地输入数据。需要注意的是,占位符不包含任何数据,因此不需要初始化它们。

random_uniform( shape, minval=0, maxval=None, dtype=tf.float32, seed=None, name=None )
从均匀分布中输出随机值.
生成的值在该 [minval, maxval) 范围内遵循均匀分布.下限 minval 包含在范围内,而上限 maxval 被排除在外.
对于浮点数,默认范围是 [0, 1).对于整数,至少 maxval 必须明确地指定.
在整数情况下,随机整数稍有偏差,除非 maxval - minval 是 2 的精确幂.对于maxval - minval 的值,偏差很小,明显小于输出(2**32 或者 2**64)的范围.
参数:
- shape:一维整数张量或 Python 数组.输出张量的形状.
- minval:dtype 类型的 0-D 张量或 Python 值;生成的随机值范围的下限;默认为0.
- maxval:dtype 类型的 0-D 张量或 Python 值.要生成的随机值范围的上限.如果 dtype 是浮点,则默认为1 .
- dtype:输出的类型:float16、float32、float64、int32、orint64.
- seed:一个 Python 整数.用于为分布创建一个随机种子.查看 tf.set_random_seed 行为.
- name:操作的名称(可选).
返回:
用于填充随机均匀值的指定形状的张量.
可能引发的异常:
- ValueError:如果 dtype 是整数并且 maxval 没有被指定.


