《三国演义》python爬虫并分析数据
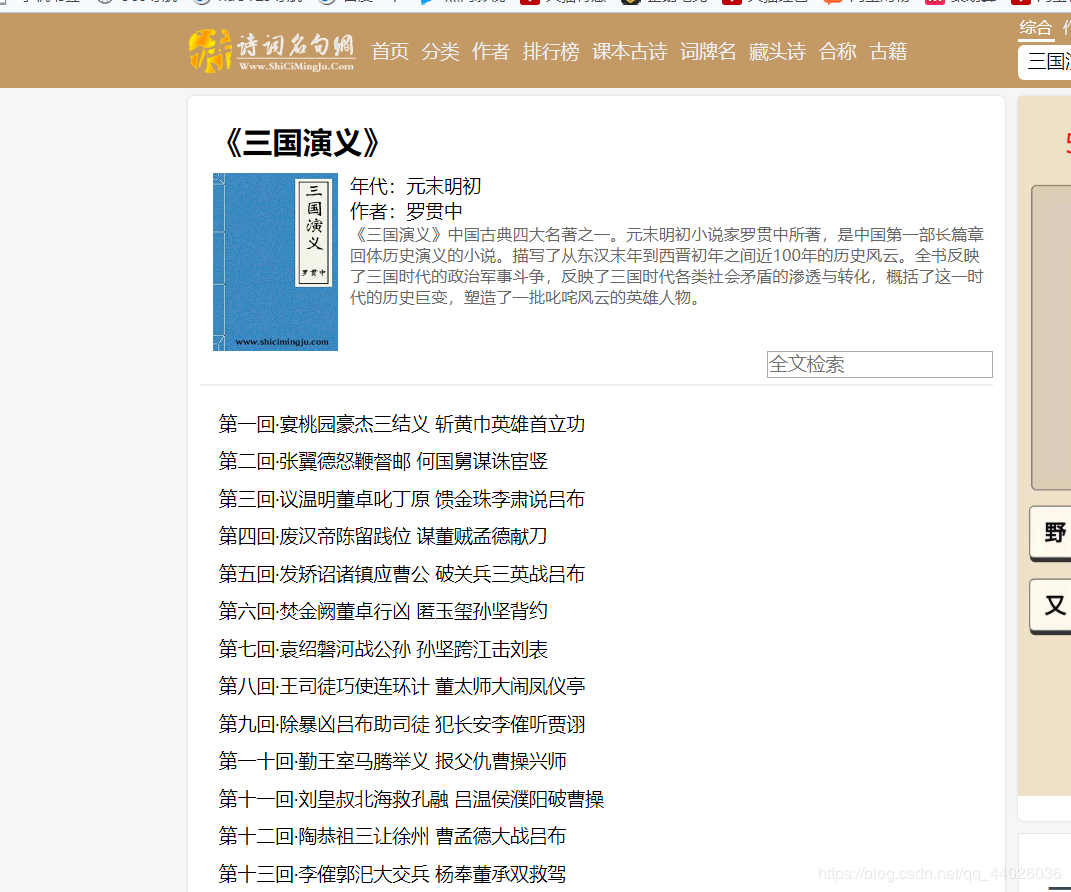
1、网页URL: http://www.shicimingju.com/book/sanguoyanyi.html
接着安装requests库和BeautifulSoup4这两个库
通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取。
快捷键[Ctrl+Shift+C],选择章节标题部分,会自动在Elements的源码中显示在何处
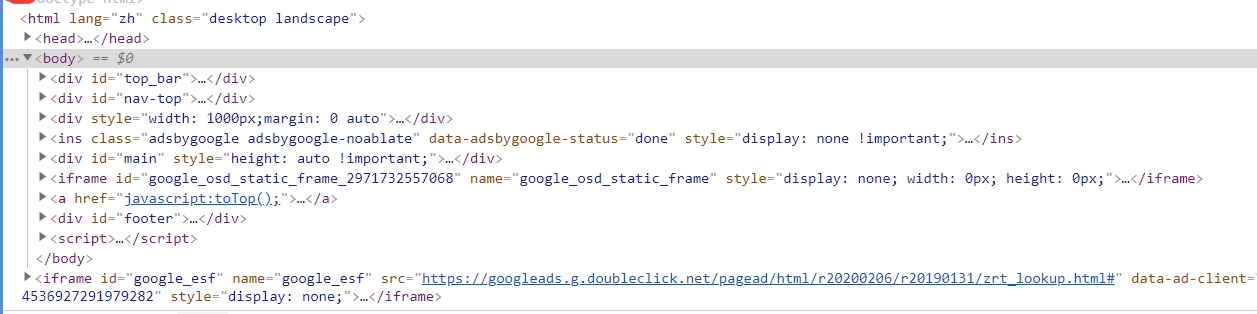
解析出章节标题和超链接

代码如下:
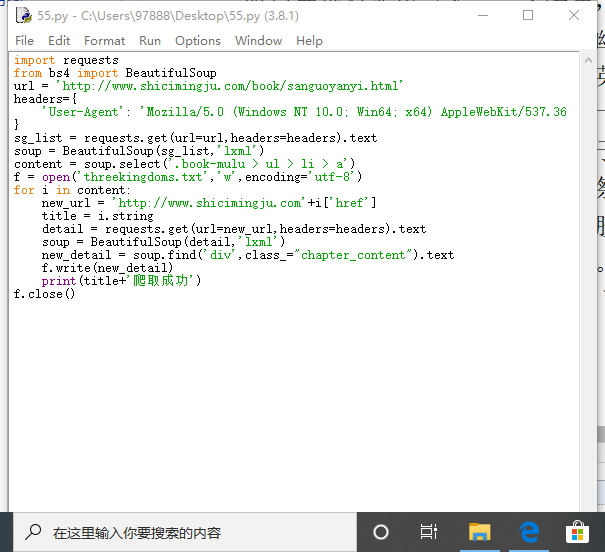
在编码的过程中会遇到各种各样的问题。
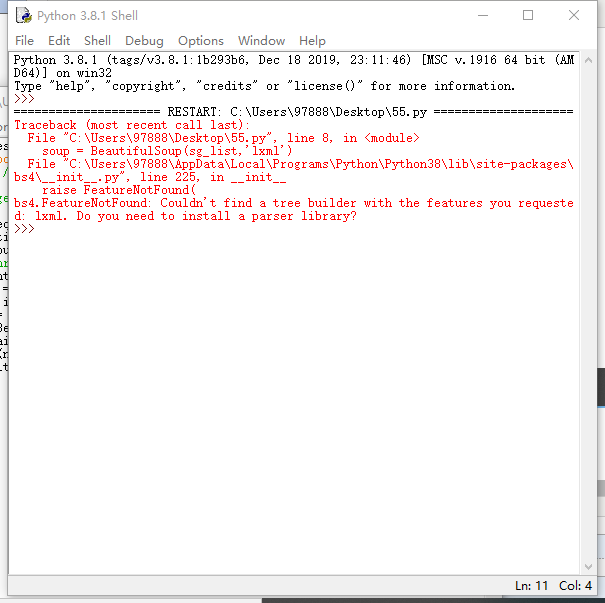
然后发现没安装laml库
之后继续安装
需要和同学教员积极沟通一起解决问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号