

系统设计 consistent hashing
System design interview- consistent hash
Tags: consistent hash, DHT, distribute hash table, Java, system design
Consistent hashing is a simple yet powerful solution to a popular problem: how to locate a server in a distributed environment to store or get a value identified by a key, while handle server failures and network change?
A simple method is number the servers from 0 to N – 1. To store or retrieve a value V, we can use Hash(V) % N to get the id of the server.
However, this method does not work well when 1) some servers failed in the network (e.g, N changes) or 2) new machines are added to the server. The only solution is to rebuild the hash for all the servers, which is time and resource consuming Given that failures are common with a network with thousands of machines, we need a better solution.
Consistent hash
Consistent hash is the solution to the above described problem. In consistent hash, the data and the servers are hashed to the same space. For instance, the same hash function is used to map a server and the data to a hashed key. The hash space from 0 to N is treated as if it forms a circle- a hash ring. Given a server with IPX, by applying the hash function, it is mapped to a position on the hash ring. Then for a data value V, we again hash it using the same hash function to map it to some position on the hash ring. To locate the corresponding server we just move round the circle clockwise from this point until the closest server is located. If there is no server found, a first server will be used. This is how to make the hash space as a ring.
For example, in the following figure, A, B, C, D are servers hashed on the ring. K1 and K2 will be served by B. K3 and K4will be served by C.

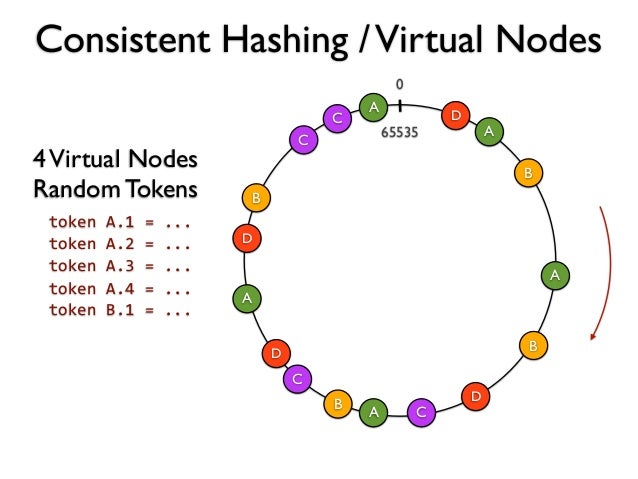
One problem of this method is that some servers may have disproportionately large hash space before them. This will cause these servers suffer greater load while the remainder servers might serve too few data. A solution is to create a number of virtually replicated nodes at different positions on the hash ring for each server. For example, for server A with ip address IPA, we can map it to M positions on the hash ring using Hash(IPA + "0"), Hash(IPA +"1"), … Hash(IPA +"M - 1").
This can help the servers more evenly distributed on the hash ring. Note that this is not related to server replication. Each virtual replicated position with Hash(IPA + "x") represents the same physical server with IP address IPA.
In the following figure, server A has four virtual nodes on the ring. We can see that the physical servers can handle data more proportionally.

consistent hash virtual node
Implementation of Consistent hash
The following is the implementation of Consistent hash using Java.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
import java.util.Collection;
import java.util.SortedMap;
import java.util.TreeMap;
interface HashFunction {
public int hash(Object key);
}
interface Server{
public String getName();
public void setName(String name);
}
public class ConsistentHash<T extends Server> {
private final HashFunction hashFunction;
private final int numberOfReplications;
private final SortedMap<Integer, T> hashRing = new TreeMap<Integer, T>();
public ConsistentHash(HashFunction hashFunc,
int numberOfReplications, Collection<T> servers) {
this.hashFunction = hashFunc;
this.numberOfReplications = numberOfReplications;
for (T server : servers) {
add(server);
}
}
public void add(T serverNode) {
for (int i = 0; i < numberOfReplications; i++) {
hashRing.put(hashFunction.hash(serverNode.getName() + i),
serverNode);
}
}
public void remove(T serverNode) {
for (int i = 0; i < numberOfReplications; i++) {
hashRing.remove(hashFunction.hash(serverNode.getName() + i));
}
}
public T get(Object key) {
if (hashRing.isEmpty()) {
return null;
}
int hash = hashFunction.hash(key);
if (!hashRing.containsKey(hash)) {
SortedMap<Integer, T> tailMap =
hashRing.tailMap(hash);
hash = tailMap.isEmpty() ?
hashRing.firstKey() : tailMap.firstKey();
}
return hashRing.get(hash);
}
}
|
Here we use Java SortedMap to represent the hash ring. The keys for the sorted map are hashed values for servers or data points. The HashFunction is an interface defining the hash method to map data or servers to the hash ring. The numberOfReplications is used to control the number of virtual server nodes to be added to the ring.
A few points to note:
- The default hash function in java is not recommended as it is not mixed well. In practice, we need to provide our own hash function through the HashFunction interface. MD5 is recommended.
- For Server interface, I only define Name related methods here. In practice, you can add more methods to the Server interface.
Reference:

{kind=link}