
JDK1.7-LinkedList循环链表优化
最近在看jdk1.7的时候,发现LinkedList 和1.6中的变化。
首先,简单介绍一下LinkedList:
LinkedList是List接口的双向链表实现。由于是链表结构,所以长度没有限制;而且添加/删除元素的时候,只需要改变指针的指向(把链表断开,插入/删除元素,再把链表连起来)即可,非常方便,而ArrayList却需要重整数组 (add/remove中间元素)。所以LinkedList适合用于添加/删除操作频繁的情况。
--------------------------------the code --------------------------------
在JDK 1.7之前(此处使用JDK1.6来举例),LinkedList是通过headerEntry实现的一个循环链表的。先初始化一个空的Entry,用来做header,然后首尾相连,形成一个循环链表:
在LinkedList中提供了两个基本属性size、header。
private transient Entry<E> header = new Entry<E>(null, null, null); private transient int size = 0;
其中size表示的LinkedList的大小,header表示链表的表头,Entry为节点对象。

private static class Entry<E> {
E element; //元素节点
Entry<E> next; //下一个元素
Entry<E> previous; //上一个元素
Entry(E element, Entry<E> next, Entry<E> previous) {
this.element = element;
this.next = next;
this.previous = previous;
}
}
上面为Entry对象的源代码,Entry为LinkedList的内部类,它定义了存储的元素。该元素的前一个元素、后一个元素,这是典型的双向链表定义方式。
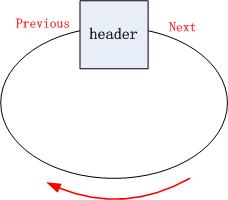
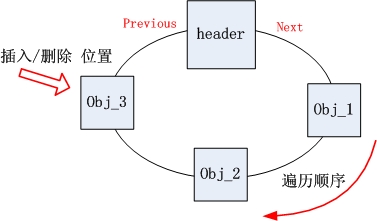
每次添加/删除元素都是默认在链尾操作。对应此处,就是在header前面操作,因为遍历是next方向的,所以在header前面操作,就相当于在链表尾操作。
如下面的插入操作addBefore以及图示,如果插入obj_3,只需要修改header.previous和obj_2.next指向obj_3即可。
private Entry<E> addBefore(E e, Entry<E> entry) {
//利用Entry构造函数构建一个新节点 newEntry,
Entry<E> newEntry = new Entry<E>(e, entry, entry.previous);
//修改newEntry的前后节点的引用,确保其链表的引用关系是正确的
newEntry.previous.next = newEntry;
newEntry.next.previous = newEntry;
//容量+1
size++;
//修改次数+1
modCount++;
return newEntry;
}
在addBefore方法中无非就是做了这件事:构建一个新节点newEntry,然后修改其前后的引用。
---------------------------------------------
在JDK 1.7,1.6的headerEntry循环链表被替换成了first和last组成的非循环链表。
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
在初始化的时候,不用去new一个Entry。
/**
* Constructs an empty list.
*/
public LinkedList() {
}

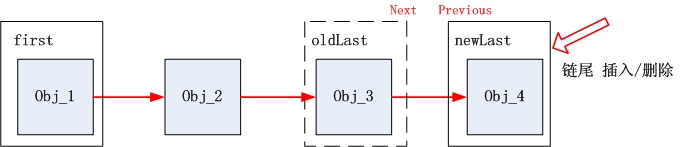
在插入/删除的时候,也是默认在链尾操作。把插入的obj当成newLast,挂在oldLast的后面。另外还要先判断first是否为空,如果为空则first = obj。
如下面的插入方法linkLast,在尾部操作,只需要把obj_3.next指向obj_4即可。
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
其中:
1 private static class Node<E> {
2 E item;
3 Node<E> next;
4 Node<E> prev;
5
6 Node(Node<E> prev, E element, Node<E> next) {
7 this.item = element;
8 this.next = next;
9 this.prev = prev;
10 }
11 }
---------------------------------------------
To sum up: 【1.6-header循环链表】 V.S 【1.7-first/last非循环链表】
JDK 1.7中的first/last对比以前的header有下面几个好处:
1、 first / last有更清晰的链头、链尾概念,代码看起来更容易明白。
2、 first / last方式能节省new一个headerEntry。(实例化headerEntry是为了让后面的方法更加统一,否则会多很多header的空校验)
3、 在链头/尾进行插入/删除操作,first /last方式更加快捷。
【插入/删除操作按照位置,分为两种情况:中间 和 两头。
在中间插入/删除,两者都是一样,先遍历找到index,然后修改链表index处两头的指针。
在两头,对于循环链表来说,由于首尾相连,还是需要处理两头的指针。而非循环链表只需要处理一边first.previous/last.next,所以理论上非循环链表更高效。恰恰在两头(链头/链尾) 操作是最普遍的】
(对于遍历来说,两者都是链表指针循环,所以遍历效率是一样的。)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号