
- 分工明细:
蒋熊:负责WordCount的升级以及python学习,添加新的命令行参数的重要支持(权重词频统计,词组统计等新功能设计)、
黄志铭:负责python的学习,自定义输入输出文件,VS上词频、行数等设计,性能测试。
- PSP:
| PSP2.2 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 100 | 200 |
| · Estimate | · 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 500 | 800 |
| · Analysis | · 需求分析 (包括学习新技术) | 240 | 300 |
| · Design Spec | · 生成设计文档 | 240 | 200 |
| · Design Review | · 设计复审 | 20 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 30 |
| · Design | · 具体设计 | 70 | 50 |
| · Coding | · 具体编码 | 0 | 0 |
| · Code Review | · 代码复审 | 0 | 0 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 0 | 0 |
| Reporting | 报告 | 40 | 100 |
| · Test Repor | · 测试报告 | 50 | 20 |
| · Size Measurement | · 计算工作量 | 15 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 80 |
| 合计 | 1355 | 1830 |
- 解题思路描述与设计实现说明
拿到题目的第一时间就是想到上一次个人作业的单词统计,这次结对作业的代码即是对上次作业的一点拓展,首先是输入是爬取的论文标题和摘要,数据量比较大,因此在思考问题的解决方案时首先应该考虑时间和空间的优化算法,其次是本次时词组频率统计而不是单词频率,因此上次使用map来记录的方式就将修改,而如何快速获得词组和权重累计就成为关键点。
至于字符、单词数和行数的统计比较简单,与上次无差异就不再做介绍,因此接下来主要介绍词组频率统计部分的代码:
因为词组将被标题和摘要隔开,且遇到’\n’也将被阻隔,因此在考虑时就可以采用分行处理,提取词组,与现有统计词组比较,若出现过相同词组,则权重累加,若无出现过,则新增词组存入,最后排序输出前十即可。而在分行处理时,考虑采用结构体存储单个词组,对每行单词进行预处理,逆序dp,处理每一个单词的连续词组的最后一个单词下标(即如果出现多个单词,中间只含分隔符,不含不合法单词,则称为连续词组,若只有该单词本身则记录自己下标),否则遇见非法单词,记为-1,如此进行正序搜索,如若某合法单词记录的连续词组最后一个单词下标-自身下标+1>=词组要求长度,则说明以此单词为起点存在合法词组,则记入,按上述方法累加权重或新增词组,若遇见-1或是长度不满足需要,则说明是不合法词组,无需操作,最后自定义排序函数cmp进行排序输出即可。
python:

#-*- coding: utf-8 -*-
import time
import re
import random
import requests
# url = 'http://openaccess.thecvf.com/CVPR2018.py
'
#这个headers信息必须包含,否则该网站会将你的请求重定向到其它页面
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,fr-FR,zh,en-us;q=0.8',
'Connection':'keep-alive',
'Host':'www.openaccess.thecvf.com
',
'Referer':'http://openaccess.thecvf.com/CVPR2018.py
',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
}
if __name__ == '__main__':
#将爬取结果存储到results.txt文件中
with open('results.txt','a+') as res:
#通过url_results.txt读取链接进行访问
with open('url_results.txt') as f:
for reurl in f:
print("正在读取:"+reurl)
response = requests.get(reurl.replace('\n',''), headers=headers)
all_content = response.text.replace('\r\n', '').replace('\t', '').replace('\n', '').replace(' ', '')
re_title = r'<divid="papertitle">(.*?)</div>'
title = re.findall(re_title ,all_content, re.S | re.M)
re_abstract = r'<divid="abstract">(.*?)</div>'
abstract = re.findall(re_abstract, all_content, re.S | re.M)
res.write("Title: "+title[0]+'\n')
res.write("Abstract: " +abstract[0]+'\n')
res.flush()
res.write('\n')
res.write('\n')
time.sleep(random.randint(1, 3))
程序代码:
int lines_counts() //计算非空行
{
ifstream rf("result(1).txt");
freopen("output1.txt","w",stdout);
if (!rf) {
cout << "open file failed. trying open default file:input.txt" << endl;
}
string Str;
char c;
int lines=0;
while (getline(rf, Str))
{
if(Str!="\0" && ((Str[0] >= 32 && Str[0] <= 126) || Str[0] == 9 || Str[0] == 10) && !(Str[0] >= 48 && Str[0] <= 57) )
{
//cout<<Str<<endl;
lines++;
//cout<<lines<<endl;
}
}
rf.close();
return lines;
}
在计算非空行的时候,逐行读取,判断是否是空行符、数字、以及非ASCII字符。python在爬取过程中有遇到非ASCII字符,所以在这里加以判断。
sort(rr,rr+x,cmp);
int mi = min(10, x);
int d;
rep(i, 0, mi)
{
fprintf(os,"<");
printf("<");
rep(j, 0, m)
{
char sq[50];
int yy = rr[i].s[j].length();
for(d = 0; d < yy; d++)
sq[d] = rr[i].s[j][d];
sq[d] = '\0';
fprintf(os,"%s ",sq);
printf("%s ",sq);
}
fprintf(os,">: %d\n",rr[i].val);
printf(">: %d\n",rr[i].val);
}
其中的mi=min(10, x)主要是对结果词频的判断,如果词频小于10,则输出所有词频,反之则输出前10个词频。
if(s == "Title:")
{
v1 = 10;
h = 1;
continue;
}
else if(s == "Abstract:")
{
v1 = 1;
//flf = false;
continue;
}
在赋予权值的时候,对权值的区分加以区别。
len = s.length();
//cout << "s = " << s << endl;
if(len < 4)
{
ww[h++].flag = false;
//cout << "ccc " << " h = " << h-1 << " flag = " << ww[h].flag << endl;
continue;
}
w(len >= 4)
{
k = 0;
w(len >= 4 && (s[k] == '(' || s[k] == ')' || s[k] == '*'))
{
k++;
len--;
}
s = s.substr(k);
i = 0;
k = 0;
flag = false;
fflag = false;
w(((s[i] >= 65 && s[i] <= 90) || (s[i] >= 97 && s[i] <= 122)) && i < len && !fflag)
{
k++;
if(s[i] >= 65 && s[i] <= 90)
s[i] = s[i] + 32;
i++;
if(k == 4)
{
flag = true;
break;
}
}
if(flag)
{
w((s[i] >= 48 && s[i] <= 57) || (s[i] >= 65 && s[i] <= 90) || (s[i] >= 97 && s[i] <= 122))
{
if(s[i] >= 65 && s[i] <= 90)
s[i] += 32;
k++;
i++;
}
if(k == len)
{
//cout << "aaa" << endl;
ww[h].s = s;
ww[h].flag = true;
//cout << "bbb " << " h = " << h << " flag = " << ww[h].flag << endl;
ww[h].val = v1;
g = 0;
h++;
len -= k;
break;
}
else
{
if(k >= 4)
{
s1 = s.substr(0, k);
//cout << "bbb" << endl;
ww[h].s = s1;
ww[h].flag = true;
//cout << "aaa " << " h = " << h << endl;
ww[h].val = v1;
h++;
//cout << "s1 = " << s1 << endl;
}
s = s.substr(k);
//cout << "s2 = " << s << endl;
len = len - k;
}
}
else
{
len -= k;
ww[h++].flag = false;
//cout << "ddd " << " h = " << h-1 << " flag = " << ww[h].flag << endl;
s = s.substr(k);
k = 0, i = 0;
w((s[i] <= 65 || (s[i] >= 91 && s[i] <= 96) || s[i] >= 123) && i < len)
{
k++;
i++;
}
if(s[i-1] < 48 || (s[i-1] > 57 && s[i-1] < 65) || (s[i-1] >= 91 && s[i-1] <= 96) || s[i-1] > 122)
fflag = false;
else fflag = true;
if(fflag)
{
w(((s[i] >= 65 && s[i] <= 90) || (s[i] >= 97 && s[i] <= 122) || (s[i] >= 48 && s[i] <= 57)) && i < len)
{
k++;
i++;
}
}
if(k)
{
s = s.substr(k);
len -= k;
}
}
}
这个代码段是对单词进行统计,采用结构体存储单个词组,对每行单词进行预处理,逆序dp,得到下标。然后遍历单词,如果是符合m的词组,就记入,否则遇见非法单词,记为-1,如此进行正序搜索。
共计爬取:979篇,以下结果是取前21篇论文进行的测试结果:
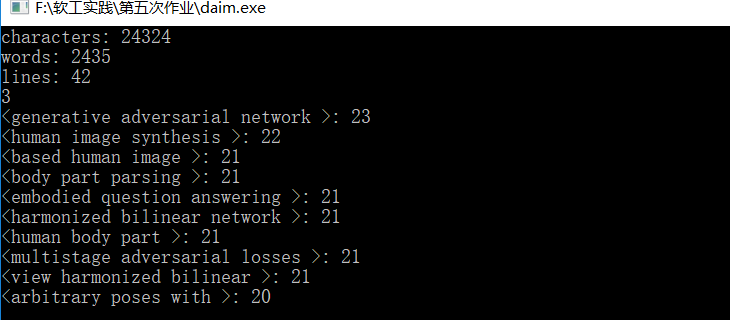
- VS的性能分析:

- 遇到的代码模块异常或结对困难及解决方法:
这次代码的思路一开始就有,写得还算是比较顺利,但是因为代码在Dev-c++上写,所以后续要换到VS上测试的时候,就出现要改的东西很多,吸取下教训,然后就开始学习怎么在VS上面写代码,在百度上百度了好久没发现,结果后来在博客中看到关于C++类的规范写法,才一目了然。目前已经搞清楚怎么使用VS写C++的程序及其类。
另外,有一点需要提及的是,由于刚开始在Dev上写的读入文件形式是以字符读入,而VS刚接触,在里面打开文件好像是采用getline比较合适,所以要改起来比较多,提交的时间快到了,后续再继续改吧。
- 队友评价:
队友很可以啊,志铭做的vs封装,我一开始用的devc++的编译器,然后肯定没法提交,志铭各种查,然后弄得VS,有他我很放心。
还有在省题的时候难点就只是词组频率统计那个,我们在写的时候呢,两个人就想了很多设想,然后分开各种试,就算是有划分分工,但是我们也没真的1认真,也还是互相帮忙,所以这队友特别靠谱,不管最后做的好不好,过程轻松,一个interesting的人。
- 学习进度条
第N周 新增代码(行) 累计代码(行) 本周学习耗时(小时) 累计学习耗时(小时) 重要成长 1 256 256 20 20 学习git,然后就是c++一些数据结构的温习 2 82 338 10 30 优化代码吧 3 0 0 20 50 学习第三和第八章,再就是新工具的使用 4 508 846 30 80 学习python,以及VS

 浙公网安备 33010602011771号
浙公网安备 33010602011771号