
python3爬取百度知道的问答并存入数据库(MySQL)
一、链接分析:
以"Linux"为搜索的关键字为例:
首页的链接为:https://zhidao.baidu.com/search?lm=0&rn=10&pn=0&fr=search&ie=gbk&word=linux
第二页的链接为:https://zhidao.baidu.com/search?word=linux&ie=gbk&site=-1&sites=0&date=0&pn=10
第三页的链接为:https://zhidao.baidu.com/search?word=linux&ie=gbk&site=-1&sites=0&date=0&pn=20
链接可以统一为:https://zhidao.baidu.com/search?word= + 关键字 + &ie=gbk&site=-1&sites=0&date=0&pn= + (页面数-1)*10
即使首页也可以这样写,只需要将最后的pn的值定为0,。
这样,我们只需要获取页面的最大页面数,然后遍历处理就可以。
二、分析首页页面:
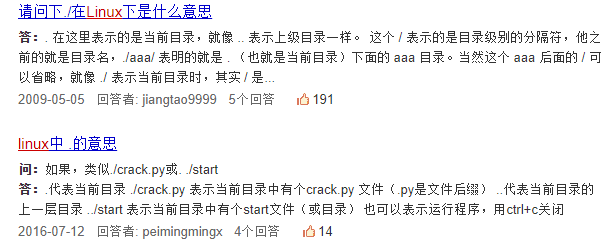
我们可以看到,在索引界面中有问题和问题的答案,此外还有提问时间和答案贡献者,但这些我在这里暂时不爬取,有兴趣的可以去试试。问题的描述一般是完整的但答案的描述就不一定了。
而在详情页两者的描述都很完整,因此为方便起见,我们统一在详情页获取问题和答案,这就需要在索引页获取详情页的URL。
通过分析很容易知道,详情页的URL在 <div class="list-inner"> 这个块中,并且在其中每个的 class="ti" 的a标签的href属性的值就是我们要的URL。
很容易获取,这里我们使用BeautifulSoup来提取。主要的代码如下:
def Get_URL(html): #从html源码中解析出url并返回,传入参数为html源码,返回URL列表 Soup = BeautifulSoup(html,'lxml') info = Soup.select('.list-inner') info = info[0].select('.ti') return [i['href'] for i in info]
三、从详情页获取问题和答案:
详情页的问题的描述一般有两种形式:一种是普通问题,放在 <span class="ask-title "> 这个块中,提取里面的文本就是问题的描述了;一种是作业帮的问题,放在 <span class="qb-content" data-gradeid="0" data-courseid="0"> 这个块中,提取里面的文本就是问题的描述了。
问题的答案也分上述两种,放在 <pre id="best-content-2257025851" accuse="aContent" class="best-text mb-10" style="min-height: 55px;"> 块中的一般问题的答案和放在 <dt class="title"> 块中的作业帮的问题的答案。
当然,你也可以有不同的获取方式,只要最终能得到信息的存放的位置就可以。知道信息的位置,很容易写代码获取。
def Get_info(url): #进入详情页获取问题和答案,传入URL,返回问题和答案 res = requests.get(url, headers = header) res.encoding = 'gbk' Soup = BeautifulSoup(res.text,'lxml') try: info = Soup.select('pre[accuse="aContent"]') if len(info) < 1: #print(url) info = Soup.select('div[accuse="aContent"]') if len(info) < 1: info = Soup.select('dt[class="title"]') info = info[0].text except: info = '' print('获取回答失败,对应的URL为:',url) try: ask = Soup.select('.ask-title ') if len(ask) < 1: ask = Soup.select('.qb-content') ask = ask[0].text except: ask = '' print('获取标题失败,对应的URL为:',url) return ask,info
四、存入数据库:
说实话,爬取数据我一个早上就写完了,但是存入数据库中花了三天时间。主要是数据库的知识忘得差不多了,毕竟自从学完后基本没什么机会用。
这里我们使用了Python操纵数据库的一个模块PyMySQL,不清楚的小伙伴可以参考这里:Python+MySQL数据库操作(PyMySQL)。
当然前提是你懂得MySQL,如果这个你也不是很了解,可以先看看这个:MySQL教程
首先,我们创建一个数据库的表test.Data来存储数据,执行下面代码之前请确认:
- 已经创建了一个数据库:test
- MySQL用户"guest"和密码"12345"可以访问test数据库
具体代码如下:
def Create_table(name = 'Data'): #传入数据库的名称,创建数据库,数据库一共有三列:问题id、问题和答案 db = pymysql.connect("localhost","guest","12345","test", use_unicode=True, charset="utf8") #db.set_character_set('utf8') cursor = db.cursor() sql_1 = "drop table if exists " + name sql_2 = """create table %s( id int(100) not null auto_increment, question text(10000) not null, answer text(10000) default NULL, PRIMARY KEY (`id`) )engine=InnoDB default charset=utf8;""" %name cursor.execute(sql_1) #print(sql_2) cursor.execute(sql_2) return db def Load_date(db,date): #将date数据插入数据库 cursor = db.cursor() sql = """insert into Date(question,answer) values(%s,%s);""" %(date[0],date[1]) #print(sql) cursor.execute(sql) db.commit()
完整的代码如下:
import requests import re from bs4 import BeautifulSoup import time import pymysql import sys url_1 = "https://zhidao.baidu.com/search?word=" url_2 = "&ie=gbk&site=-1&sites=0&date=0&pn=" header = {'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.78 Safari/537.36'} def Get_html(keyword, number = 0): #输入关键字,获取得到结果的数量和源码 #如果是首页,返回首页的HTML源码和最大页数;如果不是,则只返回HTML源码 url = url_1 + keyword + url_2 + str(number) #print(url) res = requests.get(url = url, headers = header) res.encoding = 'gbk' html = res.text if number == 0: reg = r'<a class="pager-last".+?pn=(.+?)">尾页</a>' reg = re.compile(reg) number = re.findall(reg,html)[0] return html,number else: return html def Get_URL(html): #从html源码中解析出url并返回 Soup = BeautifulSoup(html,'lxml') info = Soup.select('.list-inner') info = info[0].select('.ti') return [i['href'] for i in info] def Get_info(url): #传入详情页的URL,进入详情页获取问题和答案并返回 res = requests.get(url, headers = header) res.encoding = 'gbk' Soup = BeautifulSoup(res.text,'lxml') #详情页的问题和答案一共有三种情况,一是普通问题,二是作业帮的问答问题,三是丢失的问答 try: info = Soup.select('pre[accuse="aContent"]') if len(info) < 1: #print('不在pre[accuse="aContent"]') info = Soup.select('div[accuse="aContent"]') if len(info) < 1: info = Soup.select('dt[class="title"]') info = info[0].text except: info = '' print('获取回答失败,对应的URL为:',url) try: ask = Soup.select('.ask-title ') if len(ask) < 1: ask = Soup.select('.qb-content') ask = ask[0].text except: ask = '' print('获取标题失败,对应的URL为:',url) return ask,info def Create_table(name = 'Data'): #传入数据库的名称,创建数据库,数据库一共有三列:问题id、问题和答案 db = pymysql.connect("localhost","guest","12345","test", use_unicode=True, charset="utf8") #db.set_character_set('utf8') cursor = db.cursor() sql_1 = "drop table if exists " + name sql_2 = """create table %s( id int(100) not null auto_increment, question text(10000) not null, answer text(10000) default NULL, PRIMARY KEY (`id`) )engine=InnoDB default charset=utf8;""" %name cursor.execute(sql_1) #print(sql_2) cursor.execute(sql_2) return db def Load_date(db,date): #将date数据插入数据库 #db = pymysql.connect("localhost","guest","12345","test", use_unicode=True, charset="utf8") cursor = db.cursor() sql = """insert into Date(question,answer) values(%s,%s);""" %(date[0],date[1]) #print(sql) cursor.execute(sql) db.commit() def main(): #主调函数,负责调度其他辅助函数 #主要流程如下: #根据获取的关键字,得到首页的HTML源码和最大页数 #从源码中获取详情页的URL #然后创建数据库用来保存爬取的数据 #遍历详情页的URL,获取问题和答案,并将获得的数据插入数据库 keyword = '标书' [html,number] = Get_html(keyword) print("总共有%s页的结果!" %str(number)) URL = Get_URL(html) db = Create_table() for u in URL: #print(u) [ask,answer] = Get_info(u) if len(ask) > 1: ask = """'%s'""" %ask answer = """'%s'""" %answer date = [ask,answer] Load_date(db,date) time.sleep(1) print("首页获取完毕!") time.sleep(3) for i in range(1,int(int(number)/10+1)): html = Get_html(keyword,i*10) URL = Get_URL(html) for u in URL: #print(u) [ask,answer] = Get_info(u) if len(ask) > 1: ask = """'%s'""" %ask answer = """'%s'""" %answer date = [ask,answer] Load_date(db,date) time.sleep(1) print("第" + str(i+1) + "页获取完毕!") time.sleep(3) db.close() if __name__ == '__main__': main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号