集合
在我看来集合就是一个容器,用于存放其他的数据。
集合的类和接口均放在util类中
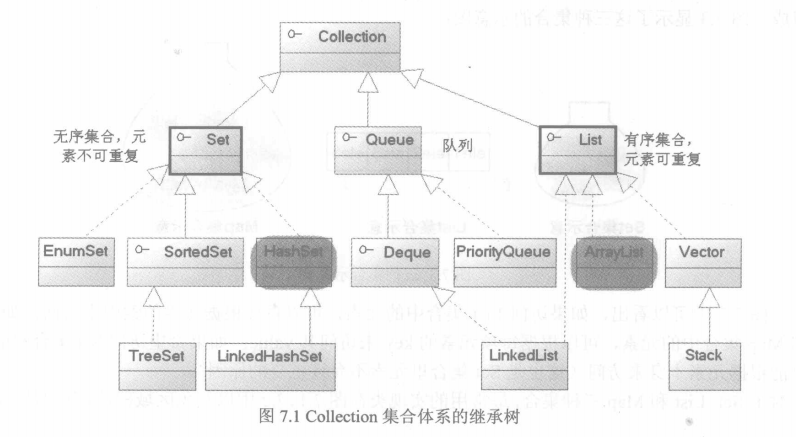
集合框架的两大体系是:collection 和 map
List接口是Collection的子接口,里面的实现子类都是有序。
arrayList的本质:arrayList 就是一个长度可变的数组
常用方法为add(),remove(),set(),get(),indexOf(),contains(),iteractor(),size() 方法, 里面用的下标进行操作
LinkList的本质:LinkList 就是一个动态可变长度的双向链表
vactor本质: 线程安全,执行效率非常低, 常用方法同上,无非增删改查,不过可参数可以是对象的引用
如何进行迭代:
Iterator it = collection.iterator(); // 获得一个迭代子
while(it.hasNext()) {
Object obj = it.next(); // 得到下一个元素
}
Linked 改快读慢
Array 读快改慢
Hash 两都之间
Collection是集合接口
|————Set子接口:无序,不允许重复。
|————List子接口:有序,可以有重复元素。
区别:Collections是集合类
Set和List对比:
Set:检索元素效率低下,删除和插入效率高,插入和删除不会引起元素位置改变。
List:和数组类似,List可以动态增长,查找元素效率高,插入删除元素效率低,因为会引起其他元素位置改变。
Set和List具体子类:
Set
|————HashSet:以哈希表的形式存放元素,插入删除速度很快。
List
|————ArrayList:动态数组
|————LinkedList:链表、队列、堆栈。
Vector是一种老的动态数组,是线程同步的,效率很低,一般不赞成使用。
HashSet:
内部是HashMap的一个实例,存的是key的集合。
元素的表现是无序的,但一旦添加完元素,元素位置是固定的(也就是说你无论再运行多少遍,这个显示的顺序都一样),再添加新元素,不会影响前面元素的位置,给添加的元素分配位置,只要不打乱前面的元素位置,前面的元素位置就不会再发生变化。
方法:add(), clear(), remove() 没有下标,contains(), iteractor(), size()
LinkHashSet 和 HashSet的。。
TreeSet:
确保元素处于排序状态,底层为树结构。使用它可以从Set中提取有序的序列。
两种排序方法:自然排序和定制排序,默认采用自然排序。
自然排序:会调用集合元素的comparaTo(对象)方法来比较元素之间的大小关系,然后把集合按升序排列(实现 Comparable接口)。
定制排序:通过Comparator(比较器)接口,需要重写compara(对象,对象),要实现定制排序,需要把comparator实例作为形 参传给TreeSet的构造器。
要想把元素放到TreeSet中,必须实现Comparable接口,同时必须实现comparaTo方法。
或者继承Comparator接口,然后重写compara方法
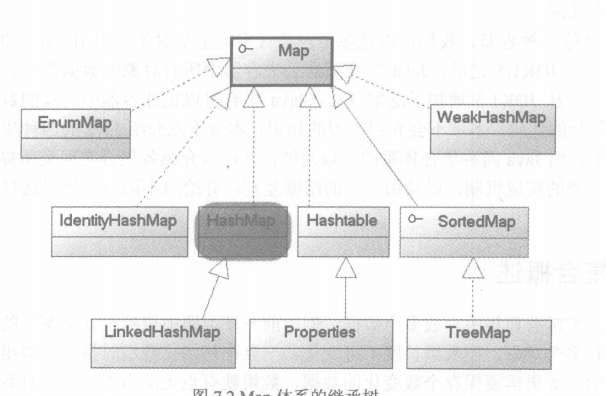
Map集合:维护"键值对"的关联性
key,value 必须都为引用类型数据
key不可以重复(后覆盖先)
常用方法: put(), remove(), putAll(), clear()
关于map的迭代方法
TreeMap:
有序。 基于红黑树数据结构的实现。查看"键"或"键值对"时,它们会被排序(次序由Comparabel或Comparator决定)。TreeMap是唯一的带有subMap()方法的Map,它可以返回一个子树。
HashTable:
最古老,不允许key和value值为null
Properties:
是HashTable的子类,用来处理文件的属性。
文件属性必须是key_value,必须都是字符串,存取数据用put(key,value),get(key)。
Collections:
集合操作类
排序:reverse(list) 反序,shuffle()随机,sort()自然顺序升序,swap(对象,位置,位置)交换
查找:
max(),min(),copy(目标list,srclist),Collections.repalceAll(list,old对象,new对象)
1.按照存入顺序排序->arraylist, vector, linklist
2.键值对无序(hashcode)存入:hashmap, hashSet(方法不同,但set底层为map)
3.单值无序(hashcode)存入:treeSet, Treemap(同上)
New HashMap
1.常用方法统计:
.put,.remove , .keySet, .entrySet, .get, .getKey, .getValue
常用于:(基于new HashMap)增、删、遍历
New HashSet
1.重写equal: hashcode
2.常用方法统计:
.add, .remove, .iterator, .hasnext, .next
共同特点:无序是指用hashcode去排序,不重复性,
New Stack:
1.常用方法:
.push, .pop,.empty
作用:模仿先进后出的栈。
New vector:
1.常用方法:
.add, .remove, .isEmpty
作用:模仿向量,删除从坐标删除到结尾
特殊点:方法同步,所以比Arraylist更加安全
New TreeMap:
1.重写compareble --compareTo comparetor
关于对比对象类方法 .getClass.equal or instanceOf ,用前强转
= 0 > 1 <-1
2.常用方法:
.put, .remove, .iterator, .hasnext, .next, .keySet, .entrySet
New TreeSet:
1.重写comparable-- compareTo comparetor
2.其他与hashSet一致
其他方法论述:
.size: map里面是无重复的key数 ,常用于list 根据下标循环输出
List论述:
1.方法分析:
.remove, .add , .set, 参数带有坐标, . indexOf可以查元素坐标
linkList, arrayList 使用方法相一致,选择要注意更偏向于增删还是改查

 浙公网安备 33010602011771号
浙公网安备 33010602011771号