


前言
最近在读Java核心技术 卷1,和大家分享一下集合篇有关散列表的感悟。
正文节选
散列表为每个对象计算一个整数,称为散列码(hashcode)。散列码是由对象的实例域产生的一个整数。更准确地说,具有不同数据域的对象将产生不同的散列码。
在 Java 中,散列表用链表数组实现。每个列表被称为桶(bucket) (参看图 9-10)。要想査找表中对象的位置,就要先计算它的散列码,然后与桶的总数取余,所得到的结果就是保存这个元素的桶的索引。
例如,如果某个对象的散列码为76268, 并且有128个桶,对象应该保存在第108号桶中(76268除以128余108)。或许会很幸运,在这个桶中没有其他元素,此时将元素直接插人到桶中就可以了。
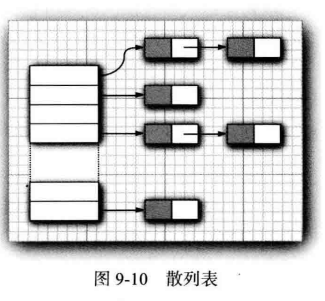
当然,有时候会遇到桶被占满的情况,这也是不可避免的。这种现象被称为散列冲突(hash collision)。这时,需要用新对象与桶中的所有对象进行比较,査看这个对象是否已经存在。如果散列码是合理且随机分布的,桶的数目也足够大,需要比较的次数就会很少。
如果想更多地控制散列表的运行性能,就要指定一个初始的桶数。桶数是指用于收集具有相同散列值的桶的数目。如果要插入到散列表中的元素太多,就会增加冲突的可能性,降低运行性能。
如果大致知道最终会有多少个元素要插人到散列表中,就可以设置桶数。通常,将桶数设置为预计元素个数的75% ~ 150%。有些研究人员认为:尽管还没有确凿的证据,但最好将桶数设置为一个素数,以防键的集聚。
标准类库使用的桶数是2的幂,默认值为16(为表大小提供的任何值都将被自动地转换为2的下一个幂)。当然,并不是总能够知道需要存储多少个元素的, 也有可能最初的估计过低。如果散列表太满,就需要再散列(rehashed)。如果要对散列表再散列, 就需要创建一个桶数更多的表,并将所有元素插入到这个新表中,然后丢弃原来的表。
装填因子(load factor) 决定何时对散列表进行再散列。例如,如果装填因子为0.75 (默认值)而表中超过75%的位置已经填人元素, 这个表就会用双倍的桶数自动地进行再散列。对于大多数应用程序来说, 装填因子为0.75 是比较合理的。
思考
原文中提到了几个关键词
性能,桶数,装填因子
还提到了一个前提条件,也就是我们能大约估计出散列表的大小,或者不妨更大胆一点,这个散列表就是固定的,那我们就可以从桶数和装填因子下手,对性能进行优化,防止触发不必要的扩容机制。
举个栗子,我们现在有10个桶要插入散列表里,我们应该如何选择桶数和装填因子?
// 一个存放10个水果的列表,现在要以中英文名放入散列表里
List<String> fruits = Arrays.asList("苹果", "橘子", "梨子", "葡萄", "香蕉", "西瓜", "柠檬", "橙子", "芭乐", "蓝莓");
是选择默认的大小吗?
HashMap<String, String> fruitsMap = new HashMap<>();
让我们计算一下桶数*装填因子 = 16 * 0.75 = 12 > 10。
刚好满足要求,不会触发扩容!
但是我们的前提是固定的桶数!请注意上文代码的Arrays.asList(),创建的是一个不可变的列表,那么我们多出的16 - 10 = 6个空间不就浪费了吗?
现在让我们来重新考虑一下这个设计,我们能不能把装填因子设置为1呢?也就是当桶满了才触发扩容,正因为我们的桶数不变,所以当我们设置桶数为10 + 1 = 11时,就永远不会触发扩容机制,而且11正好是一个素数,刚好满足了原文中带有不确定性的小建议。
后话
在实际开发过程中,可以不必过于苛求这种细节,但是在提交前代码审视的时候,就可以对这些使用的数据结构进行优化,精益求精。

