


背景
欢迎来到Java学院,我们学院学员众多,每年都要招收新学员。但是,我们学院并没有“毕业”这一机制,所以年复一年学员的数量就越来越多。
咱们学院每年都有一次大考,需要统计所有学员的成绩,并按排名的先后顺序公示给大家。
第一年
我们招收了1,000名学员。在一年过后,我们的公示栏分为10页,第一页展示了前100名的学员成绩,第二页展示了101至200名的学员成绩,以此类推...
第二年
由于学院的反响不错,我们扩招了99,000名学员,总人数达到了100,000!为了方便教学管理,我们新增了9名教师,并把学生们分布到10个班进行管理。
这一年的大考由于人数众多,辛勤的园丁们苦不堪言,在经历了漫长的阅卷后,他们把100,000份考卷按照从高到低的顺序一份份排好序...
第三年
我们的学员已经来到了10,000,000,又翻了100倍,这下教师们要罢工了,
“我们和学生的时间可是很宝贵的,这样改卷和排序,已经没有办法正常上课了!”
看着教师们群情激奋,院长只好出手想了个办法,能不能把一部分的排序工作交给学生们进行呢?
说干就干,首先,每个班共有1,000,000名学生,将他们分为1,000个1,000人的小组,每组之间先排好序。这样的确会快很多,因为1000个小组可以一起进行了!
但问题也随之而来,小组内排好序了,整个班级的顺序呢?
其实不难,我们只需要知道每一个同学在每个小组间的顺序就好了。比如说,有一位同学成绩优异,1000个组中只有三个组的同学成绩超过他,这三个组他分别处于3,4,5名,其他小组他都可以排第一,那么他在整个班级的排名就是2+3+4+1=10,第10名!
可比忘了最后的+1,因为如果没有人超过他的话,他就是第一名。
到这里,咱们学院问题可能已经迎刃而解了,但实际情况可能还要复杂一点,让我来为你们详细介绍。
回到正题
现在,让我们结合实际情况,进行具体问题具体分析。
一个20,000,000+数据量的用户表,使用sharding-jdbc分表后均匀拆成了10个表,也就是说,他们的注册时间分布是均匀的,每个表的用户注册时间从早到晚均匀分布,同时,我们使用mysql5.7数据库进行存储,Java 8进行操作。
我们要做的,就是根据用户的注册时间范围,进行一个范围查询,再按照时间的倒序,也就是离现在近的时间排在前面,进行一个分页展示。
简单介绍一下sharding-jdbc做了什么,假如你有一张表order,现在它被拆成三份,分别是order_1,order_2,order_3,你想要查询的话只要访问那个实际不存在的表,也就是order表就好了,sharding-jdbc会帮你去order_1,order_2,order_3中查询数据,并汇总到一起,同时帮你做了一些速度上的优化。
那么我们直接使用sharding-jdbc逻辑表(order)进行分页查询,会发生什么呢?
结果可能出人意料,sharding-jdbc内部采用归并排序的方式进行排序,我们得到的数据可能并不是我们想要的。
举个栗子,现在给你一张简单的表,我想要查找每页大小为2,第一页,并按从大到小的顺序会发生什么?
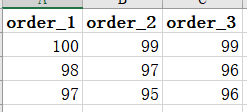
很好,我们的sharding-jdbc取出了每张表的前两个数据,这对应了每页大小为2,随后,再把每张表的最大值取出来,也就是100,99,99,现在再按从大到小取出两个数100,99。
乍一看好像没有问题,恭喜你成功取到了第一页的数据!
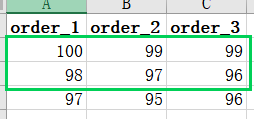
但是,我为什么要说但是呢,当我们取第二页的时候,事情就有点不对劲了。
现在,按照上面的步骤再来一遍,我们从三个表中取到的是98,97,96,最后的结果是98,97。
我们真正的顺序是100,99,99,98,97,97,96,96,95,所以第二页应该是99,98,而不是98,97。这真是令人大失所望,我们的分页之路要变得复杂起来了。
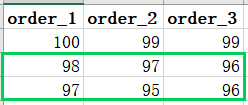
既然使用逻辑表的分页都已经出了问题,那么我们想要使用pagehelper偷懒肯定也是不行的,那么我们只能另谋出路。
我们的问题难点在于时间,为什么一碰到时间就会出问题呢,这就不得不提到mysql5.7的排序问题,只要碰到相同值(比如说时间)的行,那么它采用的堆排序就会出问题。
众所周知,堆排序是个不稳定的排序,比如说,我们要对以下的数字排个序:
1 2(a) 2(b) 3 4
这不是已经有序了吗?还能怎么排序
可实际上,排序后可能会出现这样的结果,我们已经有序的两个2竟然被调换了顺序!在数据量更大,重复数据更多的情况下,这种场景只会越来越多。
1 2(b) 2(a) 3 4
不信你可以在mysql5.7上试试,使用order by + limit进行一个排序后的分页操作,你会惊喜的发现第一页和第二页的数据竟然出现了重复!
这看起来似乎是不能忍受的,但我们也只能这样安慰自己,好歹查询速度快了不少对吧!
解决思路
言归正传,我们要开始着手解决这个问题了。
面对这种重复值较多的范围查询,还要排序,还要分页,那我们只能使用大名鼎鼎的二次查询法,也就是背景中交代的,Java学院最终采用的那种方式!
说到这里是不是感到醍醐灌顶了,原来我们的分页问题从一开始就得到解决了!
不不不,我们解决的只是分页和排序问题罢了,可你难道要把性能给丢掉吗?
串行查询多个表,并且还是二次查询,对性能的考验可是很大的,一不小心超时了那可要捅大娄子了!
sql优化
采用只读索引法进行查询,说人话,就是先从表里查出符合条件的主键,再通过主键去表里查出数据。
乍一听是不是很像通过非聚簇索引查出数据,再回表查询?确实如此,但是情况是这样查询会比直接在表上查询所有字段快很多。
举个栗子
`
select * from from 表名 where 条件;
select * from 表名
inner join(select primaryKey from 表名 where 条件) t
using (primaryKey);
`
parallelStream
Java 8中,并行流parallelStream或许可以为我们解决这个问题,我们把查询数据库的操作交给parallelStream来完成,它会使用forkjoin线程池,将你的工作进行分片完成。
那么我们要怎么利用它来进行二次查询呢?
第一次查询
我们需要计算出实际偏移量,比如说10张表,当前页curPage为100,页面大小pageSize为100,实际偏移量offset为(curPage-1)*pageSize=9900
那么我们分散到10张表中的偏移量就是9900/10=990,我们就要带着这个990进行查询,也就是
select ... limit 990,100
第一次查出的数据,我们要计算出最大的那个时间,并按表名和时间存在HashMap中,然后把所有的数据丢进ConcurrentLinkedQueue内。
ConcurrentLinkedQueue<Object> queue=new ConcurrentLinkedQueue<>();
有人就要问了,为什么不放在ArrayList中?
首先,我们使用了parallelStream,ArrayList是线程不安全的,我们可以使用CopyOnWriteArrayList或者Collections.synchronizedList(new ArrayList<>())的方式创建一个线程安全的List。
List<Object> list2 = new CopyOnWriteArrayList<>();
List<Object> list1 = Collections.synchronizedList(new ArrayList<>());
但前者每进行一次写操作都会复制一次数组,对于我们把数据库数据写入是很不友好的,而后者对List集合的操作是阻塞的,这意味着如果一个线程正在对List集合进行操作,其他线程必须等待该操作完成才能继续执行。所以二者都会带来一定的性能开销。
那么ConcurrentLinkedQueue好在哪里?ConcurrentLinkedQueue是一个无界非阻塞队列,也就是说,我们可以自由向里面添加数据而不受束缚,同时还兼顾了线程安全!并且,由于我们会对分页大小作出限制,数据库的时间分布均匀,不用担心无界队列中数据过多的情况。
第二次查询
在第一次查询中,我们得到一个ConcurrentLinkedQueue用来存放用户数据,一个HashMap用来存放每张表最大时间的数据,第二次查询,我们就要利用这个HashMap,查出最大时间在各个表的“位置”,也就是相对偏移量。
我们把HashMap中的value叫做originMaxDate,originMaxDate中最大的叫做maxDate
我们的sql要改写为
select ... between originMaxDate and maxDate
这样,我们把查出少量的额外数据加入到ConcurrentLinkedQueue中,并统计出每个表的额外数据作为相对偏移量,这样我们只需要使用Stream流的distinct()(mysql between and是闭区间,所以会有重复),sort(),skip(),limit(),collect()操作,就能得到最终的数据。
题外话
不能偷懒直接统计逻辑表的总数,这也会出问题的...
逻辑表查出的总数和分别去真实表查出的总数对不上哦~
还是得老老实实查出总数,并根据最大的那个总数计算出总页数。
PS:第一次写博客,只是给大家提供一个解题思路,部分代码都没有放上来,不过聪明的你,根据我提供的思路查查部分API的用法,问题应该就能迎刃而解了吧!

